
Ch18 InceptionNet
Yang Haoran 7/1/2022 TensorflowInceptionNet
# Ch18 InceptionNet
InceptionNet 引入了Inception结构块,在同一层网络内,使用不同尺寸的卷积核(可以提取不同尺寸的特征),提升了模型感知力,使用了批标准化,缓解了梯度消失
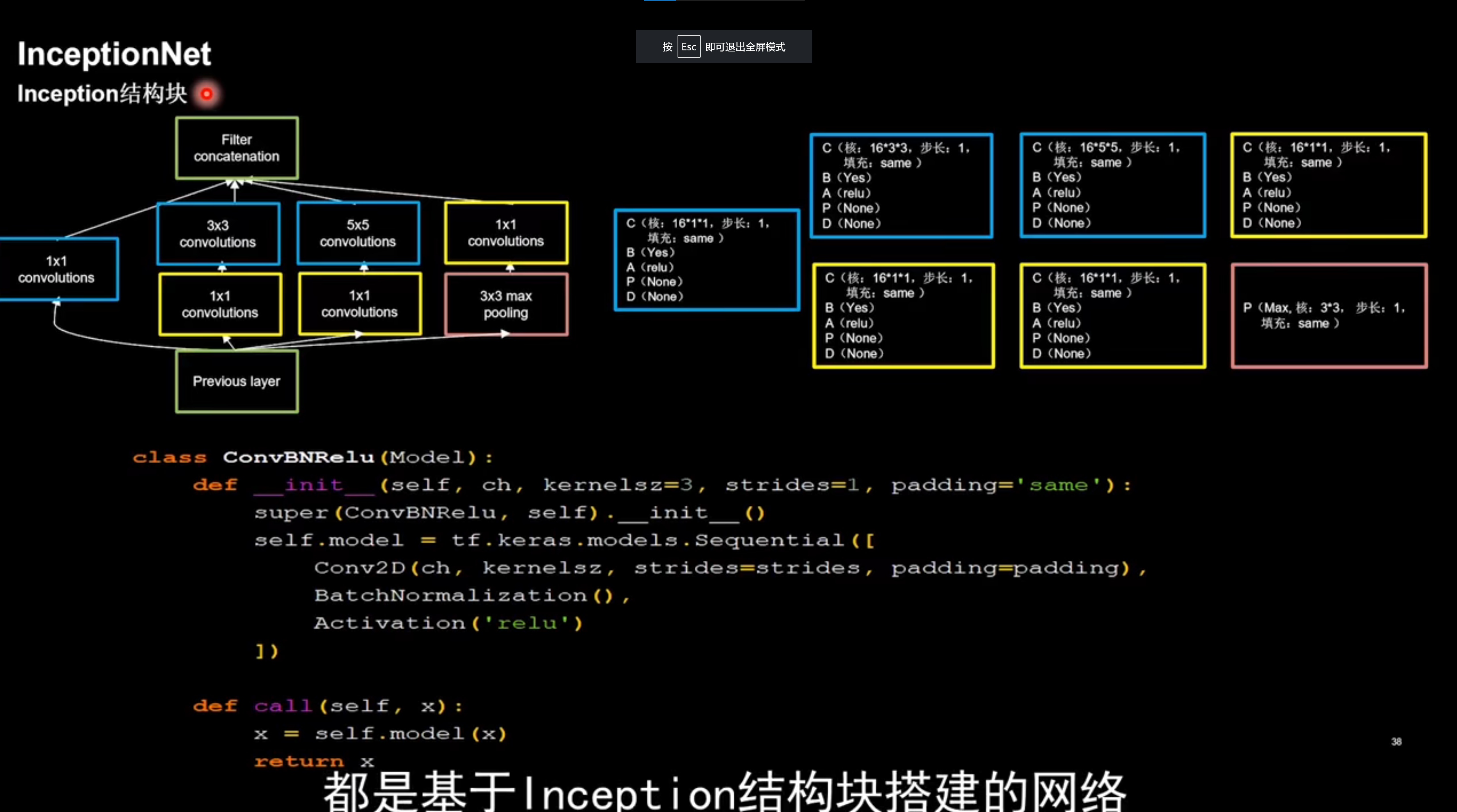
- 通过设定小于输入特征图深度的1*1卷积核个数,减少了输出图深度,起到了降维的作用,减小了参数量和计算量
- 通过不同的卷积核卷积之后,送入到卷积连接器,送入卷积连接器的尺寸相同,卷积连接器会把收到的4路特征按深度方向拼接
- 把输出特征图的深度加深,尽可能使信息承载量一致
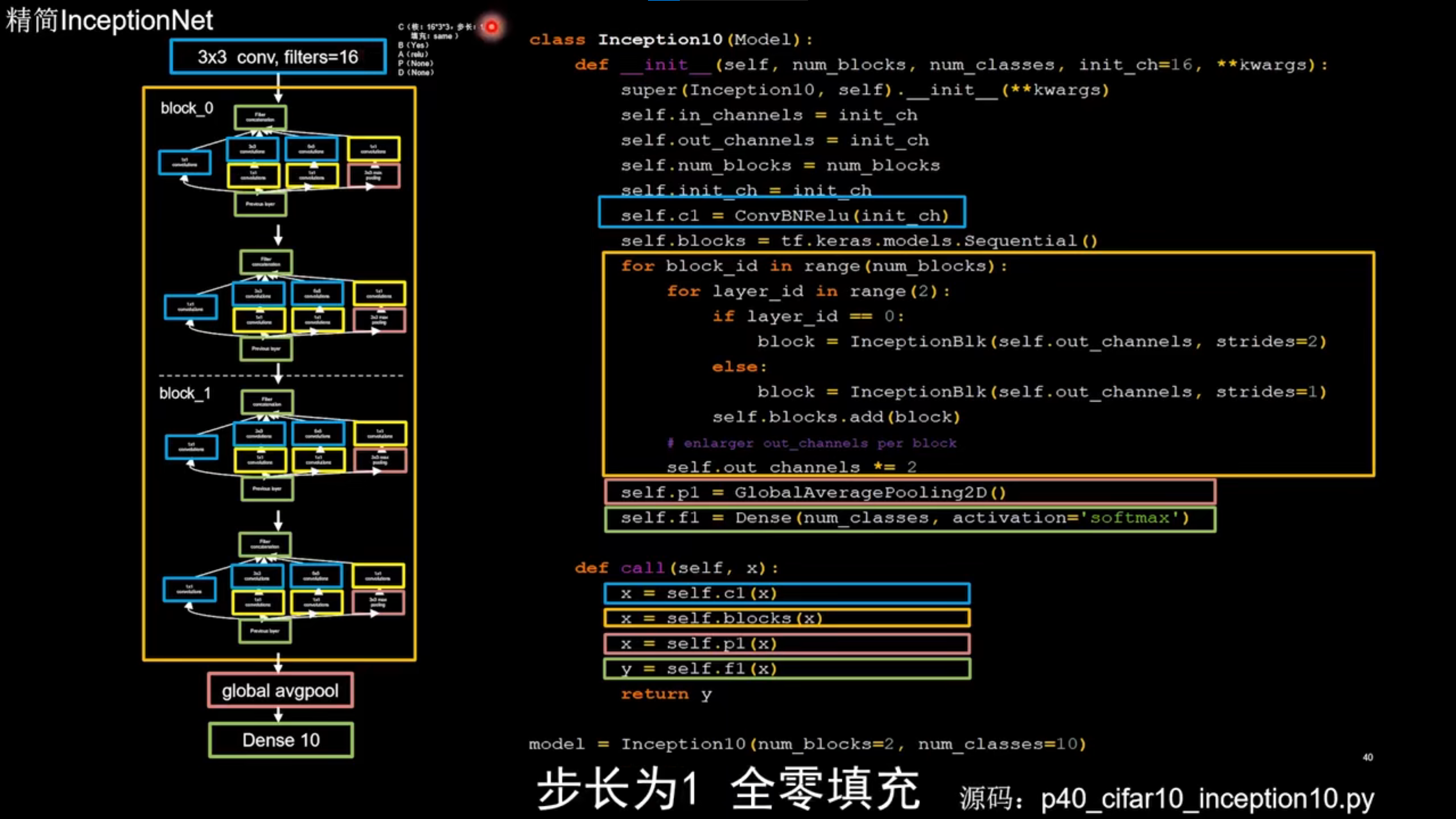
- block 1 通道数是block 0 通道数的两倍
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense, \
GlobalAveragePooling2D
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
print("x_train.shape", x_train.shape)
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) # 给数据增加一个维度,使数据和网络结构匹配
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
print("x_train.shape", x_train.shape)
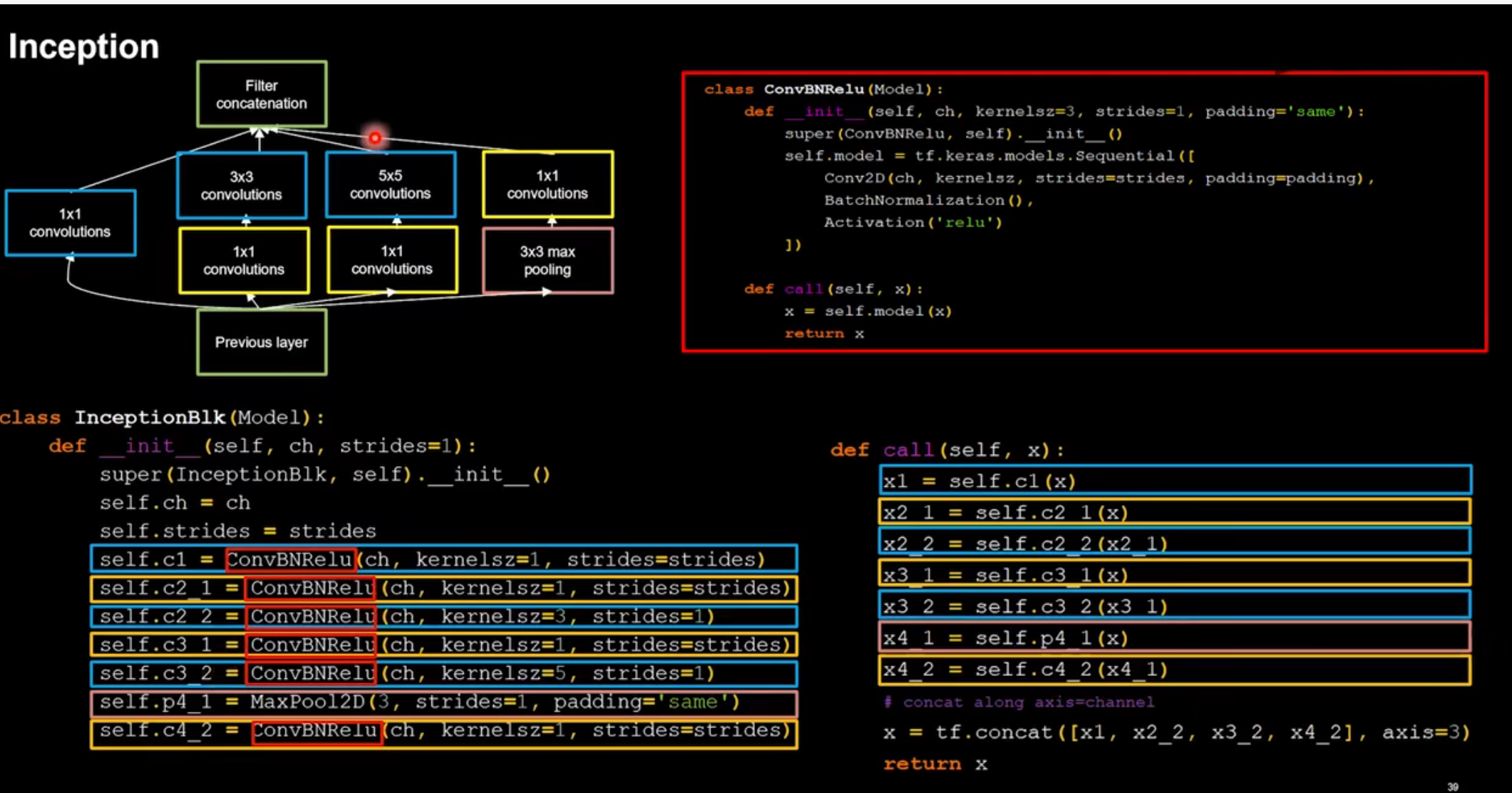
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/Inception10.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=1024, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136