
Ch00 Architecture
ref:https://openmlsys.github.io/chapter_distributed_training/overview.html#id2
# 分布式训练要解决的问题
- 算力不足--->数据并行
- 内存不足--->模型并行
# 系统架构
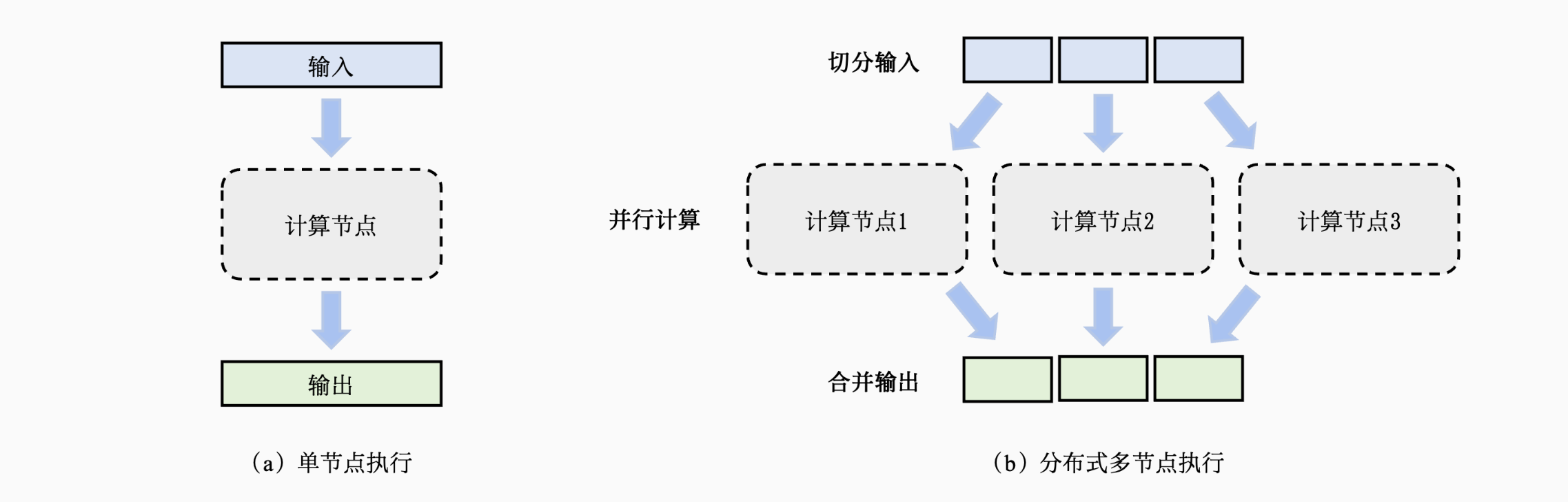
一个模型训练任务(Model Training Job)往往会有一组数据(如训练样本)或者任务(如算子)作为输入,利用一个计算节点(如GPU)生成一组输出(如梯度)
- 将输入进行切分
- 将每个输入部分会分发给不同的计算节点,实现并行计算
- 将每个计算节点的输出进行合并,最终得到和单节点等价的计算结果
# 目标
将单节点训练系统转换成等价的并行训练系统,从而在不影响模型精度的条件下完成训练过程的加速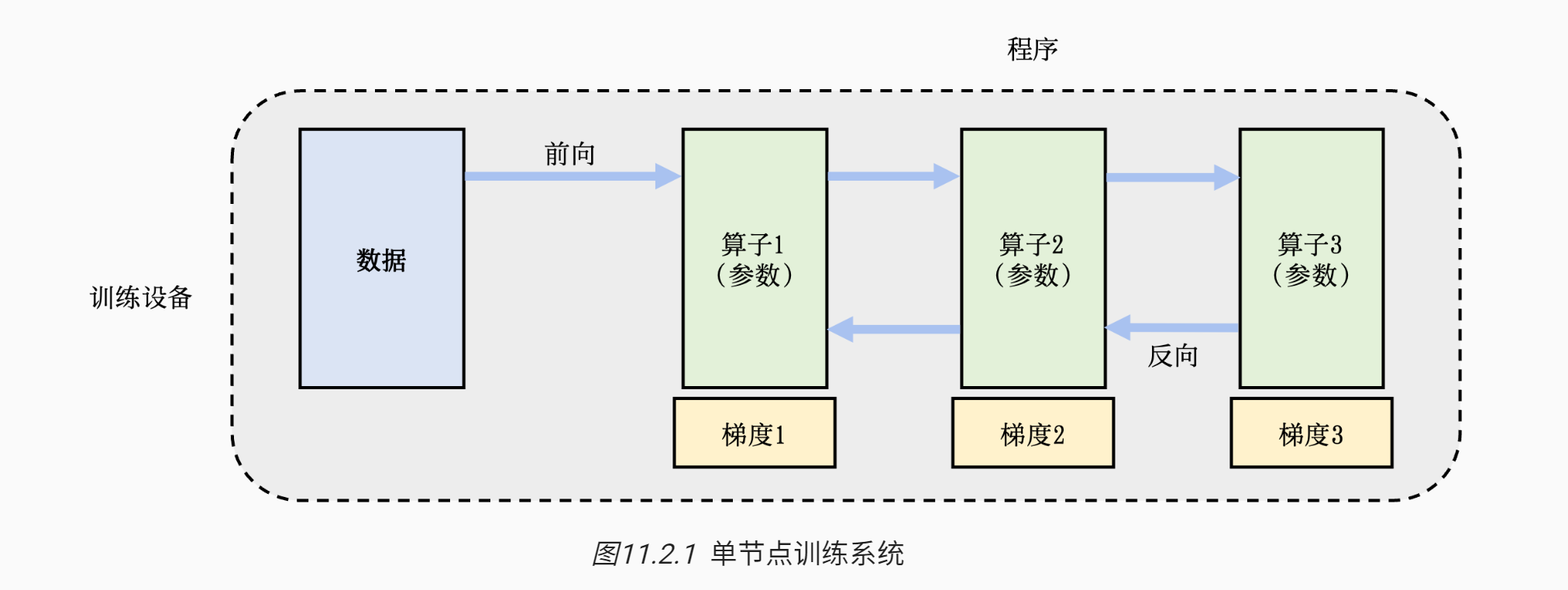
给定一个模型训练任务,人们会对数据和程序切分(Partition),从而完成并行加速。 表11.2.1 (opens new window)总结了不同的切分方法:
- 数据并行(Data Parallelism)
- 模型并行(Model Parallelism)
- 混合并行(Hybrid Parallelism)

# 数据并行
数据并行往往可以解决单节点算力不足的问题。这种并行方式在人工智能框架中最为常见,具体实现包括:TensorFlow DistributedStrategy、PyTorch Distributed、Horovod DistributedOptimizer等。
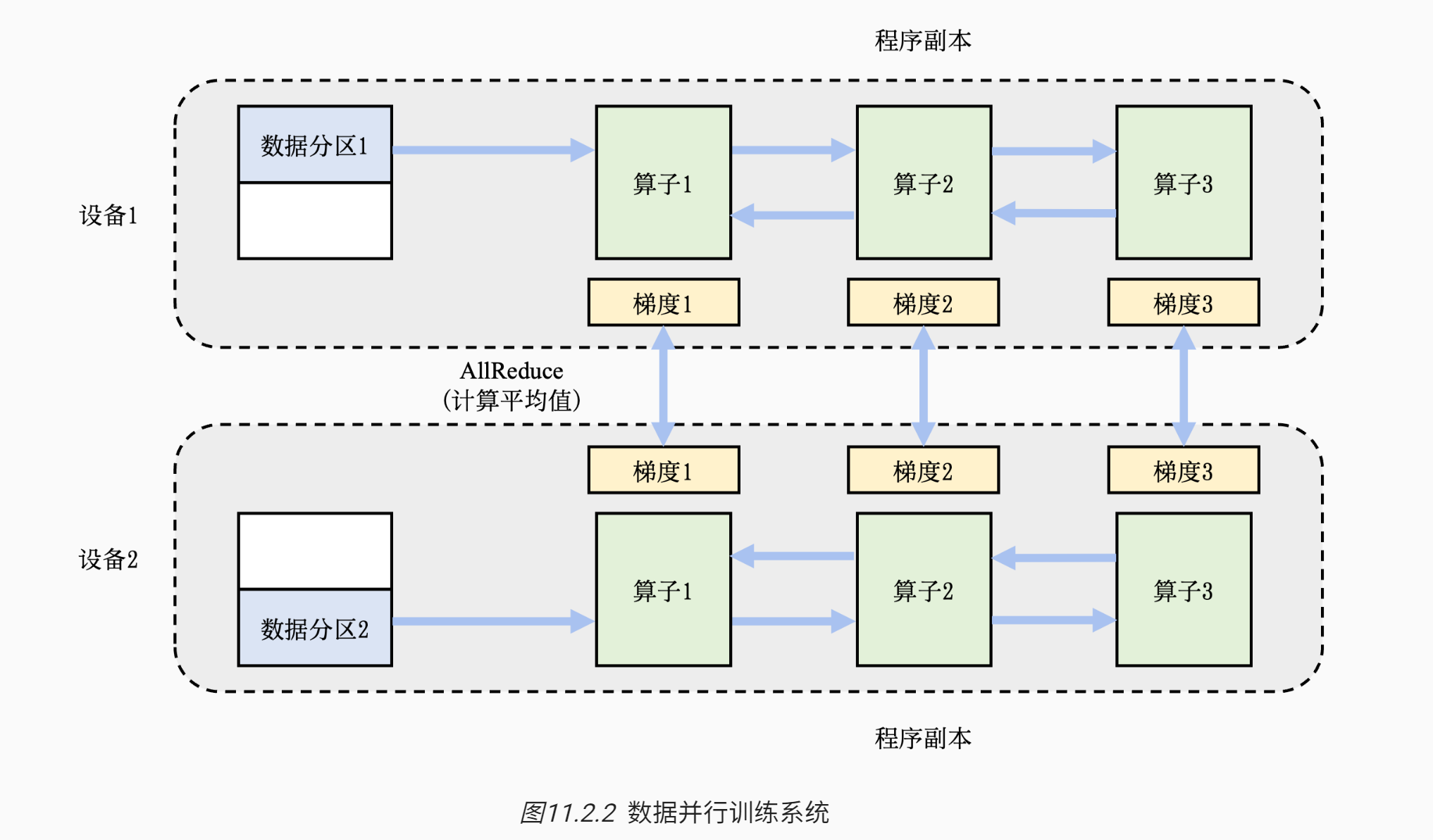
图11.2.2展示了两个设备构成的数据并行训练系统(Data Parallel Training System)的例子。
- 假设用户给定的数据批大小是64,那么每个设备会分配到32个训练样本,并且具有相同的神经网络参数(程序副本)。
- 本地的训练样本会依次通过这个程序副本中的算子,完成前向计算和反向计算。
- 在反向计算的过程中,程序副本会生成局部梯度。
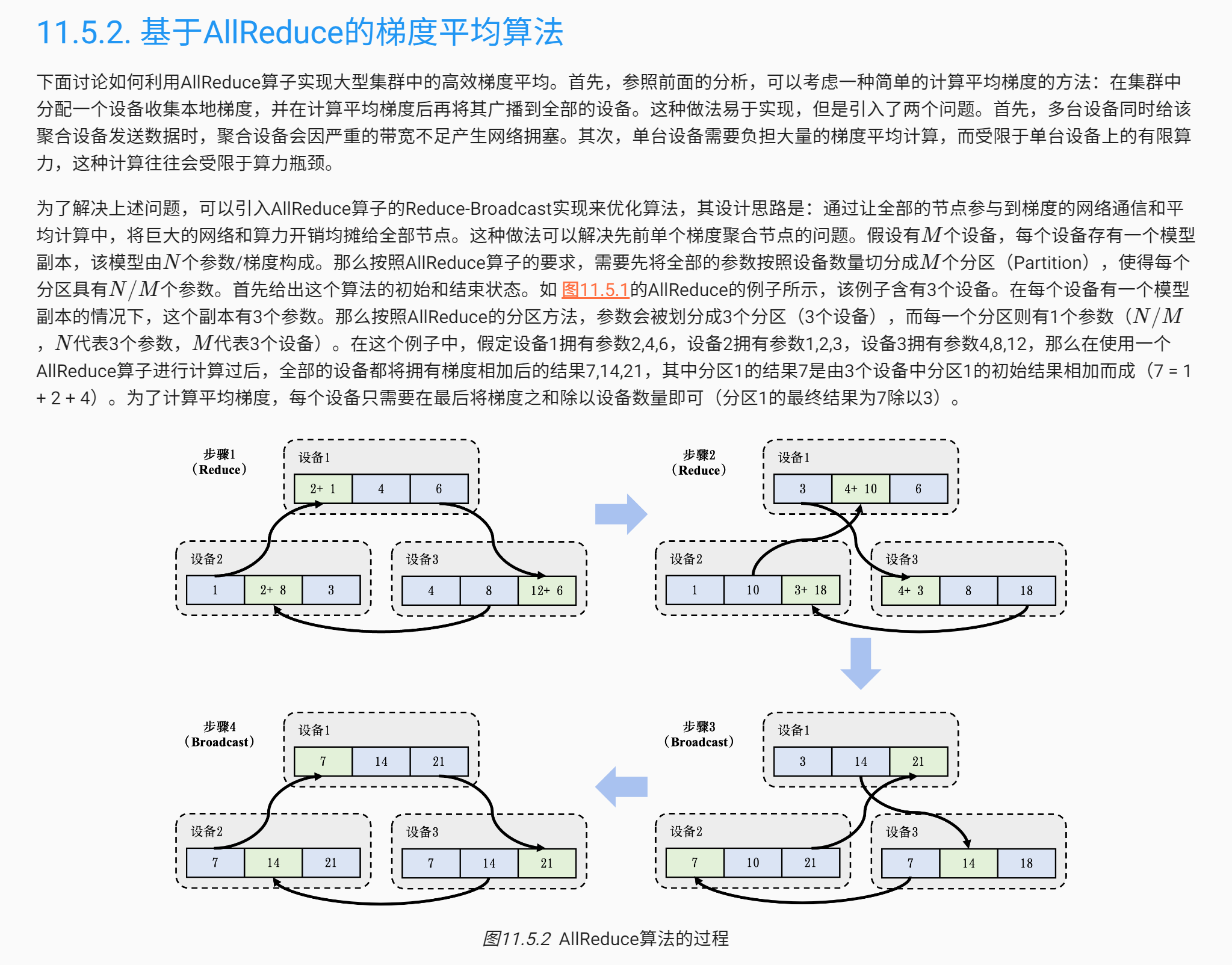
- 不同设备上对应的局部梯度(如设备1和设备2上各自的梯度1)会进行聚合,从而计算平均梯度。这个聚合的过程往往由集合通信的AllReduce操作完成。
# 模型并行
模型并行往往用于解决单节点内存不足的问题
- 一个常见的内存不足场景是模型中含有大型算子,例如深度神经网络中需要计算大量分类的全连接层
- 切分算子,也被称为算子内并行(Intra-operator Parallelism)
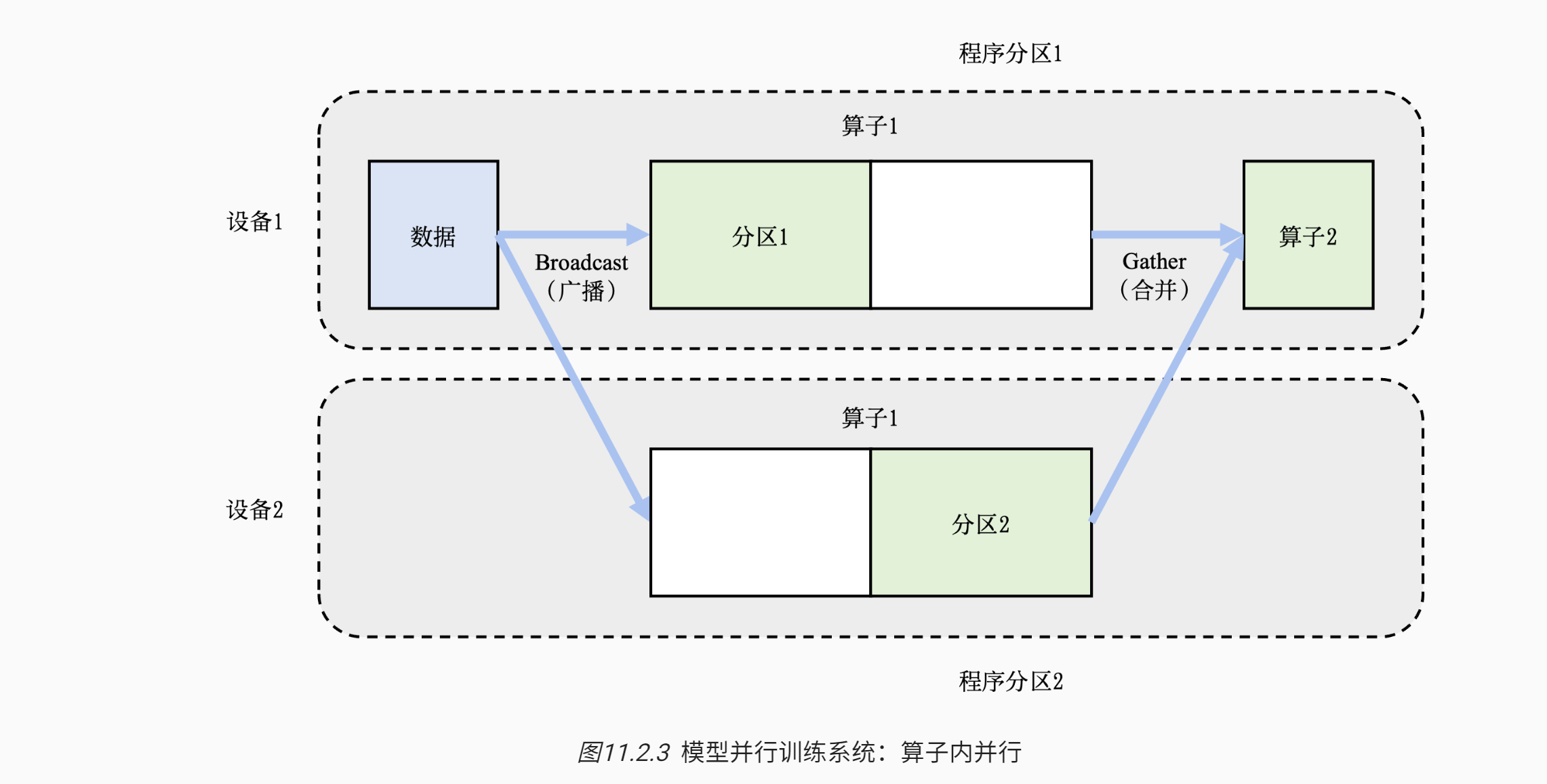
- 在这个例子中,假设一个神经网络具有两个算子,算子1的计算(包含正向和反向计算)需要预留16GB的内存,算子2的计算需要预留1GB的内存
- 而本例中的设备最多可以提供10GB的内存
- 为了完成这个神经网络的训练,需要对算子1实现并行:具体做法是,将算子1的参数平均分区,设备1和设备2各负责其中部分算子1的参数。由于设备1和设备2的参数不同,因此它们各自负责程序分区1和程序分区2。
- 在训练这个神经网络的过程中,训练数据(按照一个小批次的数量)会首先传给算子1。由于算子1的参数分别由两个设备负责,因此数据会被广播(Broadcast)给这两个设备。
- 不同设备根据本地的参数分区完成前向计算,生成的本地计算结果需要进一步合并,发送给下游的算子2。
- 在反向计算中,算子2的数据会被广播给设备1和设备2,这些设备根据本地的算子1分区各自完成局部的反向计算。计算结果进一步合并计算回数据,最终完成反向计算。
- 如果算子在一个设备中放得下,可以算子间并行
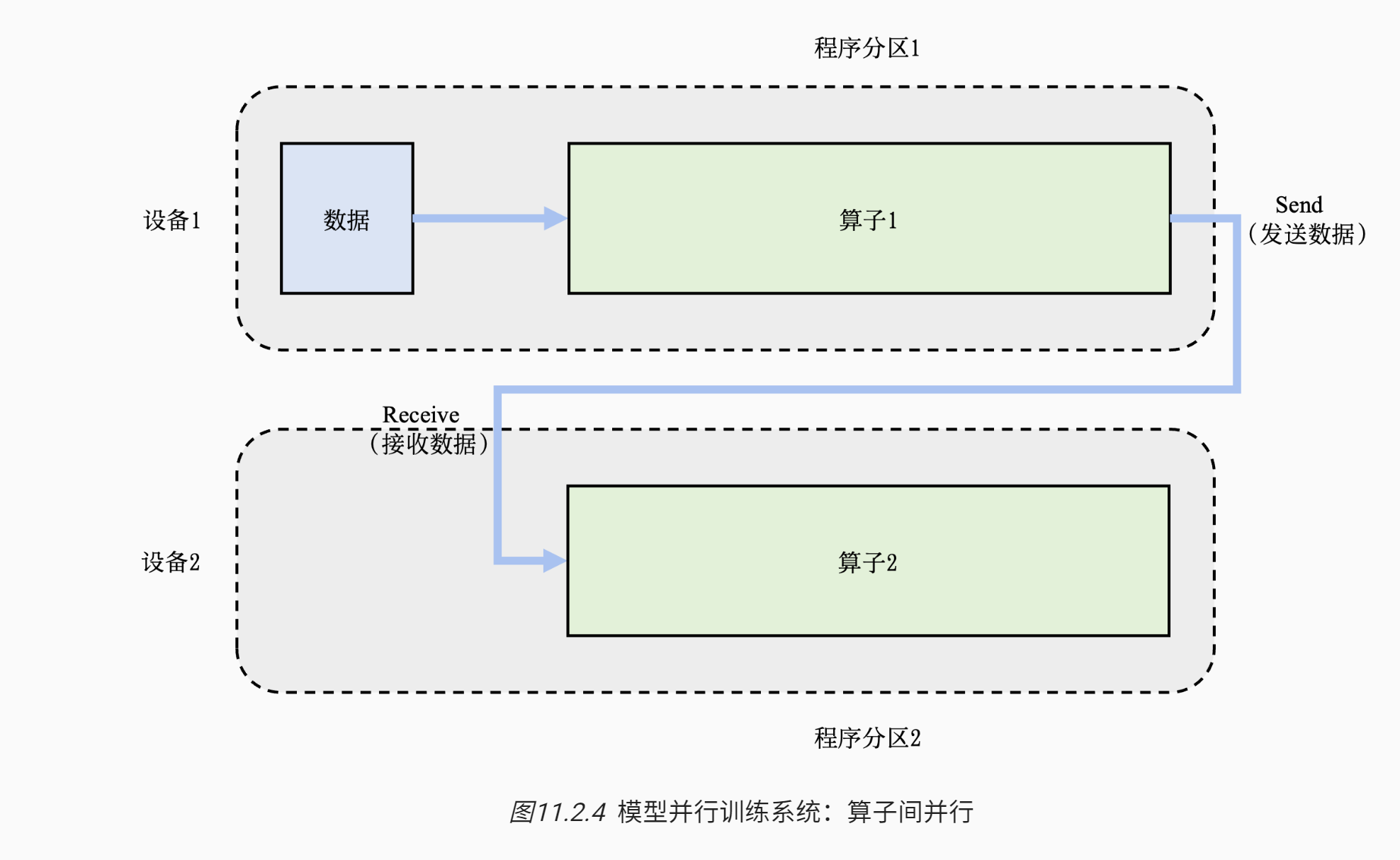
# 混合并行
算力和内存都不够,需要混合使用数据并行和模型并行,这种方法被称为混合并行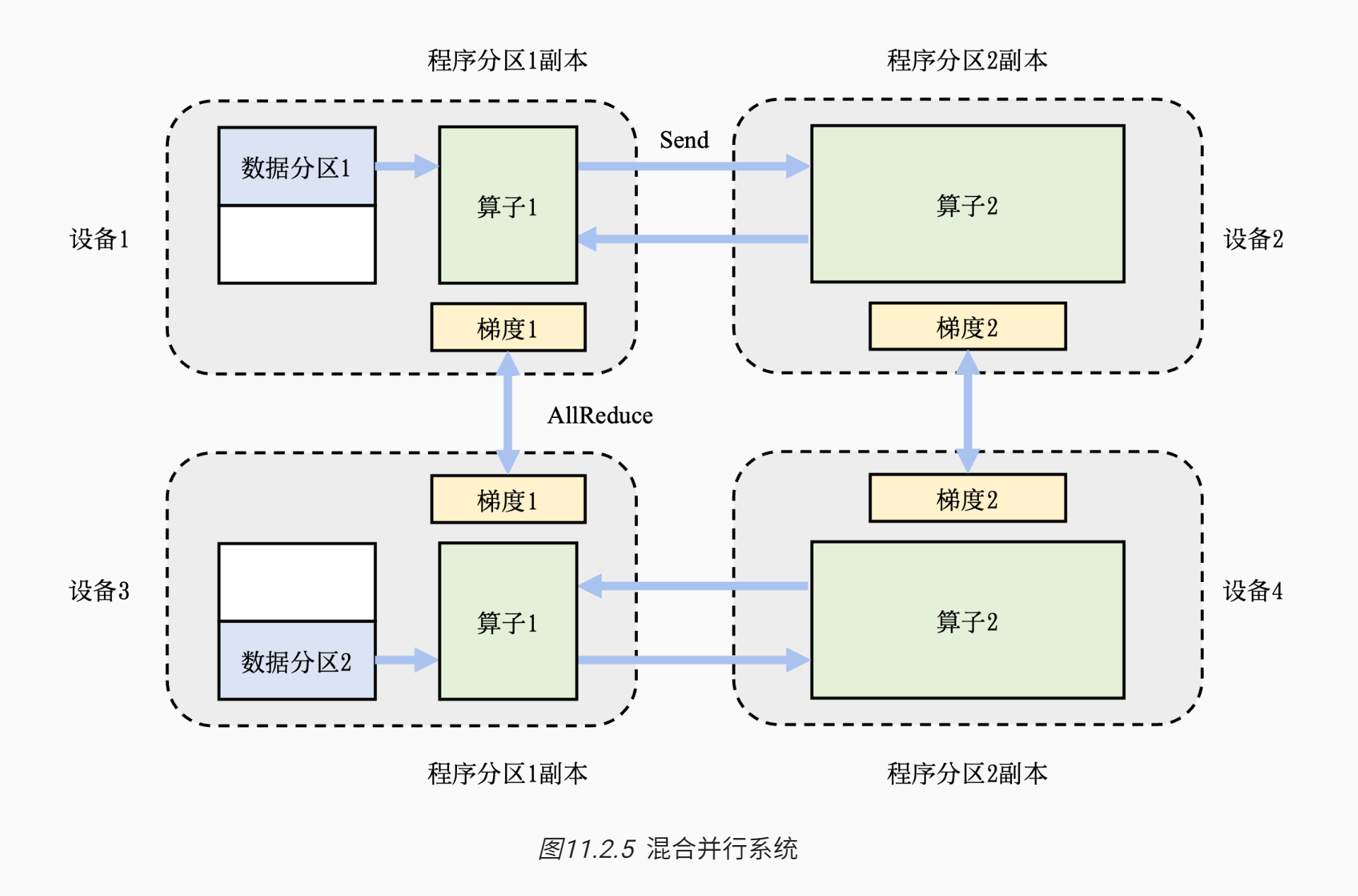
- 在这个例子中,首先实现算子间并行解决训练程序内存开销过大的问题:该训练程序的算子1和算子2被分摊到了设备1和设备2上。
- 进一步,通过数据并行添加设备3和设备4,提升系统算力。
- 为了达到这一点,对训练数据进行分区(数据分区1和数据分区2),并将模型(算子1和算子2)分别复制到设备3和设备4。
- 在前向计算的过程中,设备1和设备3上的算子1副本同时开始,计算结果分别发送(Send)给设备2和设备4完成算子2副本的计算。
- 在反向计算中,设备2和设备4同时开始计算梯度,本地梯度通过AllReduce操作进行平均。反向计算传递到设备1和设备3上的算子1副本结束。
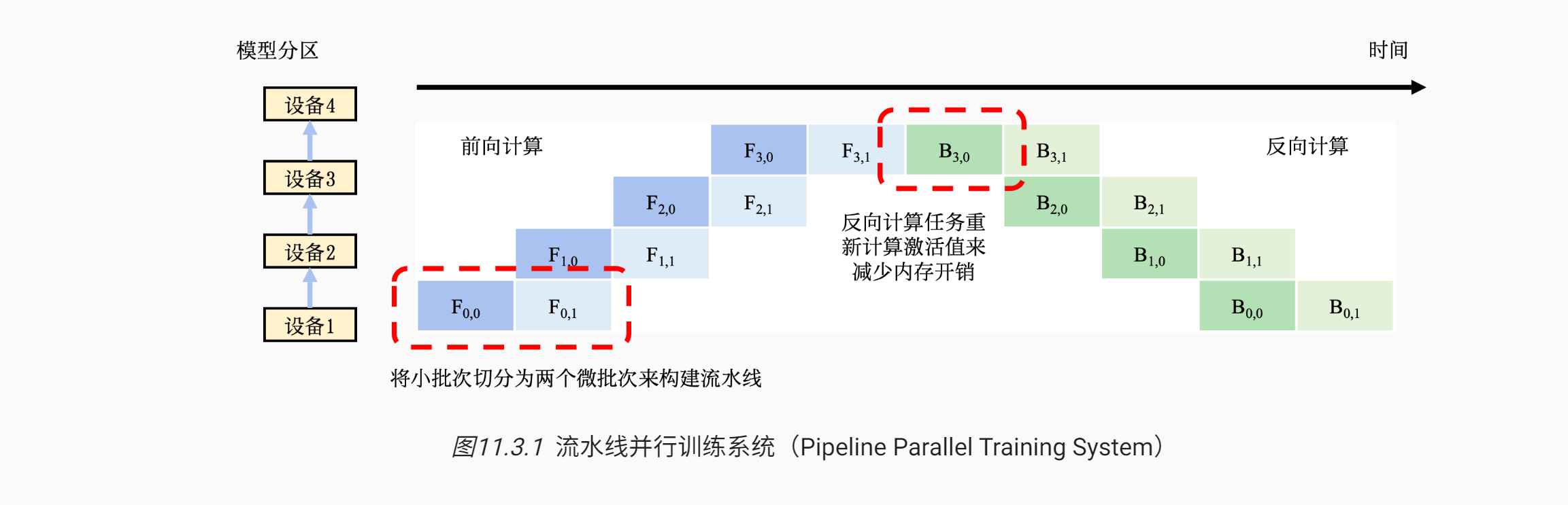
# 流水线并行
流水线并行往往被应用在大型模型并行系统中。
- 这种系统通过算子内并行和算子间并行解决单设备内存不足的问题。
- 然而,这类系统的运行中,计算图中的下游设备(Downstream Device)需要长期持续处于空闲状态,等待上游设备(Upstream Device)的计算完成,才可以开始计算,这极大降低了设备的平均使用率。
- 这种现象称为模型并行气泡(Model Parallelism Bubble)。

# 机器学习集群架构
机器学习模型的分布式训练通常会在计算集群(Compute Cluster)中实现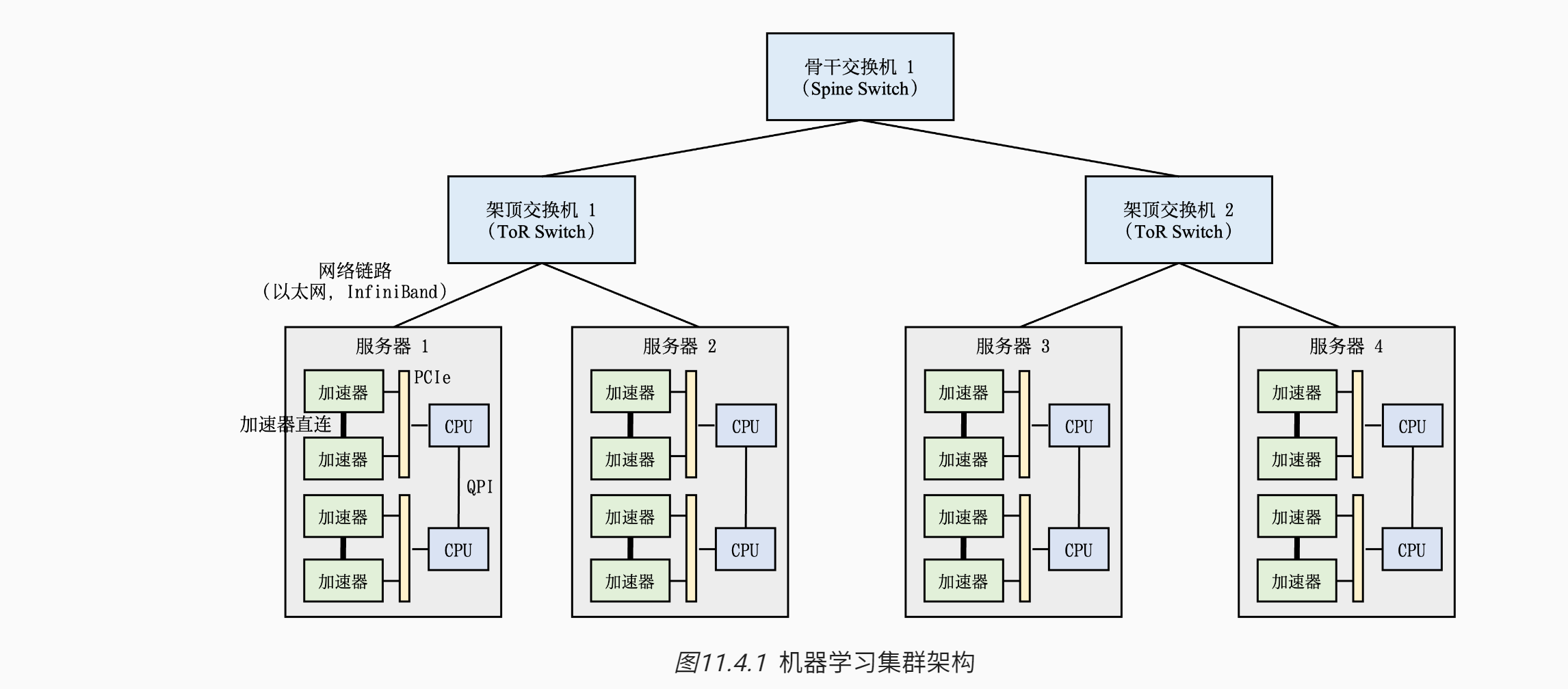
- 这种集群中会部署大量带有硬件加速器的服务器。每个服务器中往往有多个加速器。
- 为了方便管理服务器,多个服务器会被放置在一个机柜(Rack)中,同时这个机柜会接入一个架顶交换机(Top of Rack Switch)。
- 在架顶交换机满载的情况下,可以通过在架顶交换机间增加骨干交换机(Spine Switch)进一步接入新的机柜。这种连接服务器的拓扑结构往往是一个多层树(Multi-Level Tree)。
# 带宽设计
需要注意的是,在集群中跨机柜通信(Cross-Rack Communication)往往会有网络瓶颈。这是因为集群网络为了便于硬件采购和设备管理,会采用统一规格的网络链路。
- 因此,在架顶交换机到骨干交换机的网络链路常常会形成网络带宽超额认购(Network Bandwidth Oversubscription),即峰值带宽需求会超过 实际网络带宽。
- 如 图11.4.1的集群内,当服务器1和服务器2利用各自的网络链路(假设10Gb/s)往服务器3发送数据时,架顶交换机1会汇聚2倍数据(即20Gb/s)需要发往骨干交换机1。
- 然而骨干交换机1和架顶交换机1 之间只有一条网络链路(10Gb/s)。这里,峰值的带宽需求是实际带宽的两倍,因此产生网络超额订购。
- 在实际的机器学习集群中,实际带宽和峰值带宽的比值一般在1:4到1:16之间。因此如果将网络通信限制在机柜内,从而避免网络瓶颈成为了分布式机器学习系统的核心设计需求。
# 例子
那么,在计算集群中训练大型神经网络需要消耗多少网络带宽呢?假设给定一个千亿级别参数的神经网络(比如OpenAI 发布的大型语言模型GPT-3有最多将近1750亿参数),如果用32位浮点数来表达每一个参数
- 那么每一轮训练迭代(Training Iteration)训练中,一个数据并行模式下的模型副本(Model Replica)则需要生成700GB,即175G ∗ 4 bytes = 700GB,的本地梯度数据。
- 假如有3个模型副本,那么至少需要传输1.4TB,即700GB ∗ (3−1),的梯度数据。
- 这是因为对于N个副本,只需传送其中的N−1个副本完成计算。当平均梯度计算完成后,需要进一步将其广播(Broadcast)到全部的模型副本(即1.4TB的数据)并更新其中的本地参数,从而确保模型副本不会偏离(Diverge)主模型中的参数。
当前的机器学习集群一般使用以太网(Ethernet)构建不同机柜之间的网络。主流的商用以太网链路带宽一般在10Gb/s到25Gb/s之间。这里需要注意的是,网络带宽常用Gb/s为单位,而内存带宽常用GB/s为单位。前者以比特(bit)衡量,后者以字节(byte)衡量。
- 利用以太网传输海量梯度会产生严重的传输延迟。
- 新型机器学习集群(如英伟达的DGX系列机器)往往配置有更快的InfiniBand。单个InfiniBand链路可以提供100Gb/s或200Gb/s的带宽。
- 即使拥有这种高速网络,传输TB级别的本地梯度依然需要大量延迟(即使忽略网络延迟,1TB的数据在200Gb/s的链路上传输也需要至少40s)。InfiniBand的编程接口以远端内存直接读取(Remote Direct Memory Access,RDMA)为核心,提供了高带宽,低延迟的数据读取和写入函数。
- 然而,RDMA的编程接口和传统以太网的TCP/IP的Socket接口有很大不同,为了解决兼容性问题,人们可以用IPoIB (IP-over-InfiniBand)技术。这种技术确保了遗留应用(Legacy Application)可以保持Socket调用,而底层通过IPoIB调用InfiniBand的RDMA接口。
为了在服务器内部支持多个加速器(通常2-16个),通行的做法是在服务器内部构建一个异构网络。
- 以图11.4.1 中的服务器1为例,这个服务器放置了两个CPU,CPU之间通过QuickPath Interconnect (QPI)进行通信。而在一个CPU接口(Socket)内,加速器和CPU通过PCIe总线(Bus)互相连接。
- 由于加速器往往采用高带宽内存(High-Bandwidth Memory,HBM)。HBM的带宽(例如英伟达A100的HBM提供了1935 GB/s的带宽)远远超过PCIe的带宽(例如英伟达A100服务器的PCIe 4.0只能提供64GB/s的带宽)。
- 在服务器中,PCIe需要被全部的加速器共享。当多个加速器同时通过PCIe进行数据传输时,PCIe就会成为显著的通信瓶颈。为了解决这个问题,机器学习服务器往往会引入加速器高速互连(Accelerator High-speed Interconnect),例如英伟达A100 GPU的NVLink提供了600 GB/s的带宽,从而绕开PCIe进行高速通信。
# 集合通信
作为并行计算的一个重要概念,集合通信经常被用来构建高性能的单程序流/多数据流(Single Program-Multiple Data, SPMD)程序。
# 常见算子
下面首先定义一个简化的集合通信模型,然后引入常见的集合通信算子:Broadcast、Reduce、AllGather、Scatter和 AllReduce。需要指出的是,在分布式机器学习的实际场景下,人们还会使用许多其他的集合通信算子,如ReduceScatter、Prefix Sum、Barrier、All-to-All等,但由于篇幅限制,便不再赘述。
假定在一个分布式机器学习集群中,存在p个计算设备,并由一个网络来连接所有的设备。每个设备有自己的独立内存,并且所有设备间的通信都通过该网络传输。同时,每个设备都有一个编号i,其中i的范围从1到p。 设备之间的点对点(Point-to-Point, P2P)通信由全双工传输(Full-Duplex Transmission)实现。该通信模型的基本行为可以定义如下:
- 每次通信有且仅有一个发送者(Sender)和一个接收者(Receiver)。在某个特定时刻,每个设备仅能至多发送或接收一个消息(Message)。每个设备可以同时发送一个消息和接收一个消息。一个网络中可以同时传输多个来自于不同设备的消息。
- 传输一个长度为l个字节(Byte)的消息会花费a+b×l的时间,其中a代表延迟(Latency),即一个字节通过网络从一个设备出发到达另一个设备所需的时间;b代表传输延迟(Transmission Delay),即传输一个具有l个字节的消息所需的全部时间。前者取决于两个设备间的物理距离(如跨设备、跨机器、跨集群等),后者取决于通信网络的带宽。需要注意的是,这里简化了传输延迟的定义,其并不考虑在真实网络传输中会出现的丢失的消息(Dropped Message)和损坏的消息(Corrupted Message)的情况。
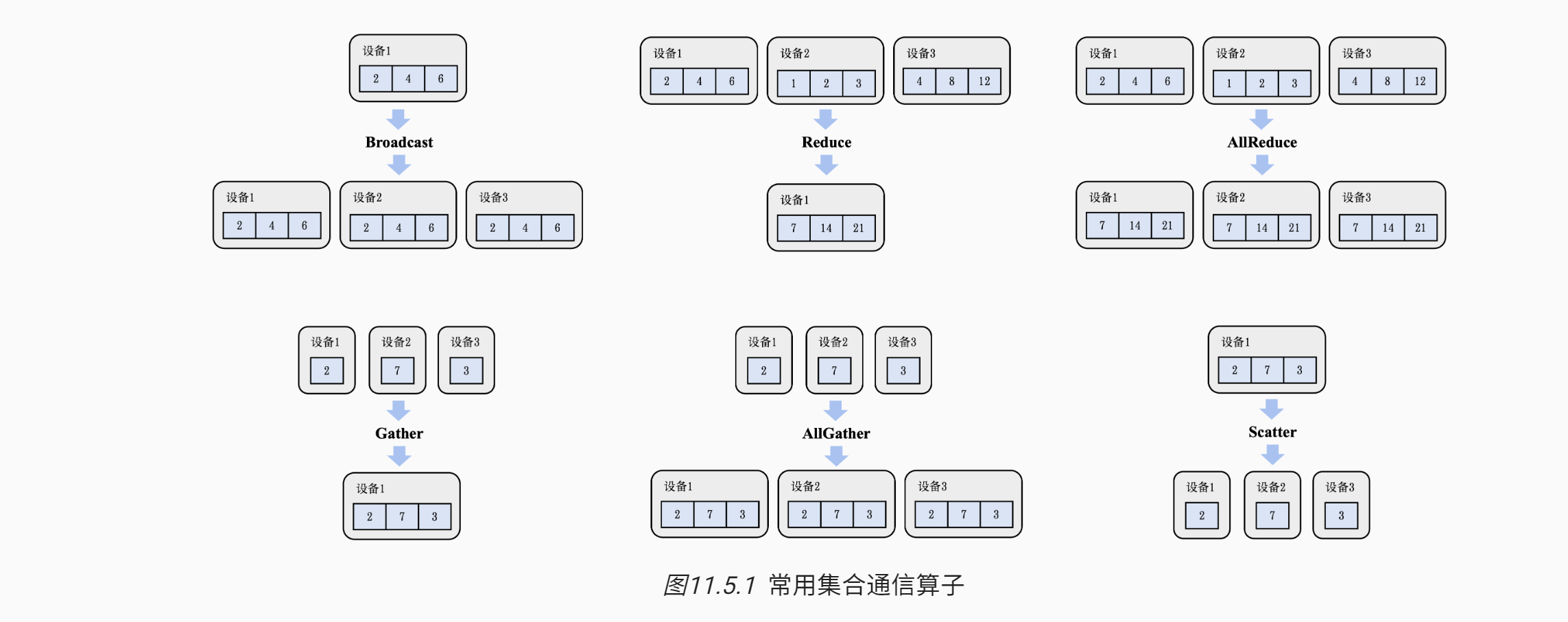




more: https://openmlsys.github.io/chapter_distributed_training/collective.html
# 参数服务器
下面介绍另一种常见的分布式训练系统:参数服务器。不同的机器学习框架以不同方式提供参数服务器的实现。TensorFlow和MindSpore内置了参数服务器的实现。PyTorch需要用户使用RPC接口自行实现。同时,我们也有参数服务器的第三方实现,如PS-Lite。
不同于基于集合通信实现的机器学习系统,参数服务器系统中的服务器会被分配两种角色:
- 训练服务器:需要提供大量的计算资源(如硬件加速器)
- 参数服务器:需要提供充足内存资源和通信资源
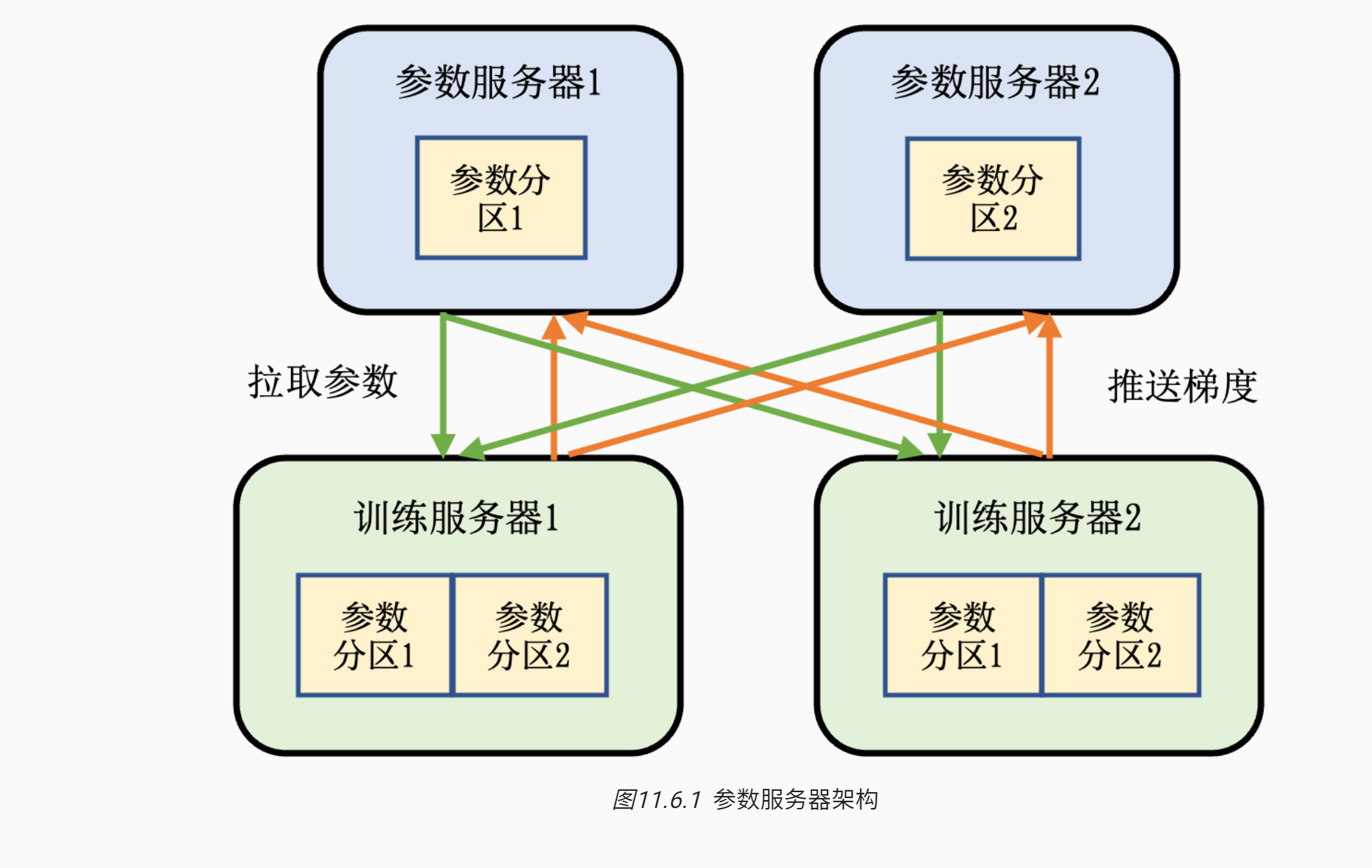
- 图11.6.1 描述了带有参数服务器的机器学习集群。
- 这个集群中含有两个训练服务器和两个参数服务器。 假设我们有一个模型,可以切分为两个参数分区。
- 每个分区被分配给一个参数服务器负责参数同步。
- 在训练的过程中,每个训练服务器都会有完整的模型,根据本地的训练数据集切片(Dataset Shard)训练出梯度。这个梯度会被推送(Push)到各自参数服务器。参数服务器等到两个训练服务器都完成梯度推送,开始计算平均梯度,更新参数。它们然后通知训练服务器来拉取(Pull)最新的参数,开始下一轮训练迭代。
# 异步训练
参数服务器的一个核心作用是可以处理分布式训练服务器中出现的落后者(Straggler)。
在之前的讨论中,在每一轮训练结束后,训练服务器都需要计算平均梯度对每一个模型副本进行更新,从而保证下一轮训练开始前,全部模型副本参数的一致性,这种对于参数一致性的确保一般被称为同步训练(Synchronous Training)。
同步训练一般有助于训练系统达到更好的模型精度,但是当系统规模变大,往往会观察到落后者服务器的出现。落后者出现的原因很多。常见的原因包括:落后者设备可能和其他设备不在同一个机柜中,因此落后者的通信带宽显著小于其他设备。另外,落后者设备也可能和其他进程共享本地的服务器计算和通信资源,形成资源竞争,从而降低了性能。
落后者对于基于AllReduce的同步训练系统的性能有显著影响,这是因为AllReduce让全部节点参与到平均梯度的计算和通信中,而每个节点负责等量的数据。
因此一个落后者的出现,都会让整个AllReduce操作延迟完成。为了解决这个问题,人们常使用参数服务器同步梯度。一种常见的设计是:训练服务器训练出梯度后,会把本地梯度全部推送到参数服务器。参数服务器在等到一定训练服务器(例如90%的训练服务器)的梯度后,就开始计算平均梯度。这样可以确保平均梯度的计算不会被落后者的出现延误。计算好的平均梯度马上推送给全部训练服务器,开始下一轮训练。
解决落后者的另一种常见做法是利用参数服务器实现异步训练(Asynchronous Training)。在一个异步训练系统中,每个训练服务器在训练开始时,有相同的模型参数副本。在训练中,它们计算出梯度后会马上将梯度推送到参数服务器,参数服务器将推送的梯度立刻用于更新参数,并通知训练服务器立刻来拉取最新的参数。在这个过程中,不同的训练服务器很可能会使用不同版本的模型参数进行梯度计算,这种做法可能会伤害模型的精度,但它同时让不同训练服务器可以按照各自的运算速度推送和拉取参数,而无须等待同伴,因此避免了落后者对于整个集群性能的影响。
# 数据副本
在参数服务器的实际部署中,人们往往需要解决数据热点问题。互联网数据往往符合幂律概率(Power-Law Distribution),这会导致部分参数在训练过程中被访问的次数会显著高于其他参数。例如,热门商品的嵌入项(Embedding Item)被训练服务器拉取的次数就会远远高于非热门商品。因此,存储了热门数据的参数服务器所承受的数据拉取和推送请求会远远高于其他参数服务器,因此形成数据热点,伤害了系统的可扩展性。
利用数据副本的另一个作用是增加系统的鲁棒性。当一个参数服务器出现故障,其所负责的参数将不可用,从而影响了整体系统的可用性。通过维护多个参数副本,当一个参数服务器故障时,系统可以将参数请求导向其他副本,同时在后台恢复故障的参数服务器,确保系统的可用性不受影响。
解决参数服务器故障和数据热点问题的常用技术是构建模型主从复制(Leader-Follower Replication)。一份参数在多个机器上拥有副本,并指定其中一个副本作为主副本(Leader Replica)。训练服务器的所有更新操作都向主副本写入,并同步至全部从副本(Follower Replica)。如何取得共识并确定哪一个副本是主副本是分布式系统领域一个经典问题,对该问题已经有了相当多的成熟算法,例如Paxos和Raft。此外,主副本上的更新如何复制到从副本上也是分布式系统领域的经典共识问题。通常系统设计者需要在可用性(Availability)和一致性(Consistency)之间做出取舍。如果参数服务器副本间采用强一致性(Strong Consistency)的复制协议(Replication Protocol),例如链式复制(Chain Replication),则可能导致训练服务器的推送请求失败,即参数服务器不可用。反之,如果参数服务器采用弱一致性(Weak Consistency)的复制协议,则可能导致副本间存储的参数不一致。