
Ch04 Physical Data warehouse design
Yang Haoran 11/16/2021 DataData warehouse
# Physical Data warehouse design
# Partitioning
Partitioning Methods(分表)可以水平切割也可以垂直切割
- Range partitioning
- Hash partitioning
- 也可以结合上面两个,先用range partitioning再用hash partitioning
# Materialized summary data
- explicit summary data(显式调用):有额外的一张表存放,没有和原先数据的连接,在查询的时候也分开查询

- 根据fact表中两个字段(region_dim, region_type)可以在dimension表中查询到唯一一行表示细节
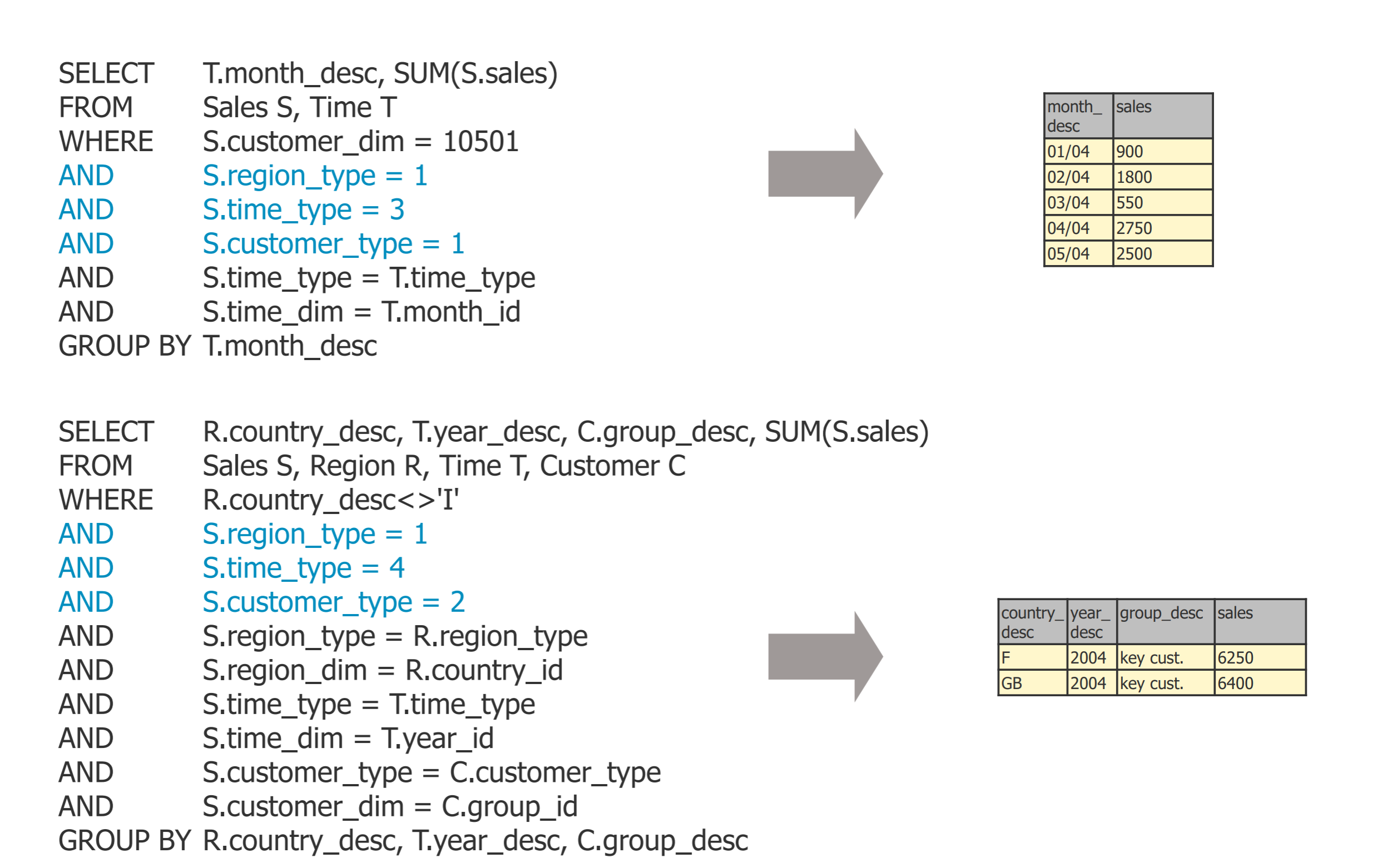
- 查哪些表就把哪些表join起来,用两个and = 表示
- 根据fact表中两个字段(region_dim, region_type)可以在dimension表中查询到唯一一行表示细节
- implicit summary data(隐式调用):只有一张detailed表可以查询,当查询语句查询了这些聚合信息时,自动去Materialized view里找,materialized view refer to the detailed table
# Materialized Views
刷新策略:
- deferred:只有当refresh table 语句执行的时候,才会刷新
- immediate:源数据有更新的时候
Derivability:


- 需要考虑以下4点:
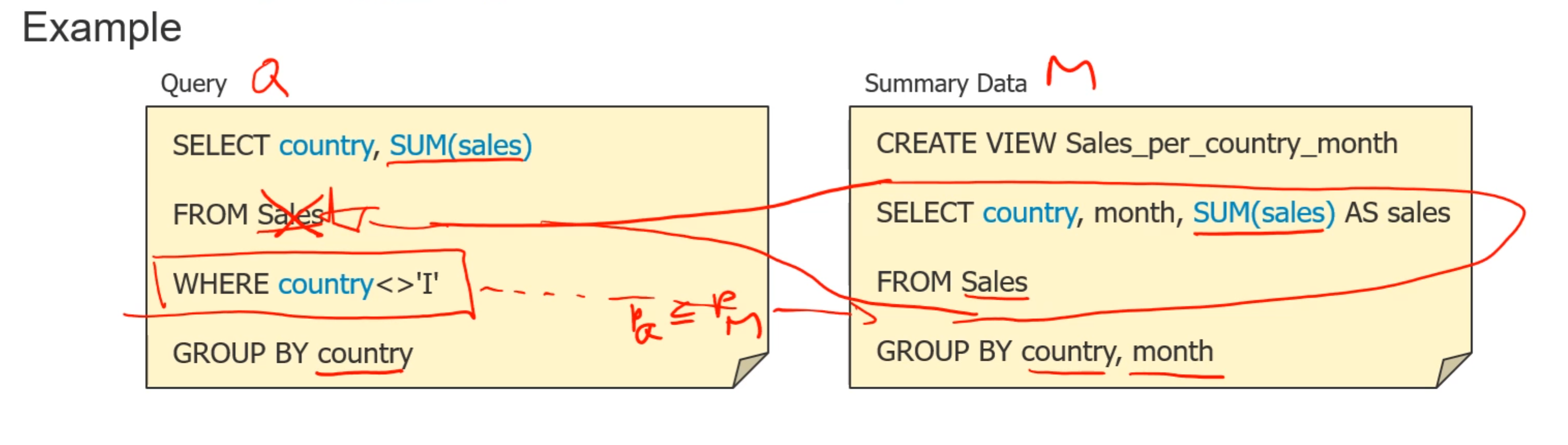
- Predicates:谓词的限制要比summary table要高:如下图,query中有where子句,但是summary中没有,所以在查询的时候满足restiction高的条件,sales就直接从summary data中取,而不是从原始数据中拿
- Aggregate functions:
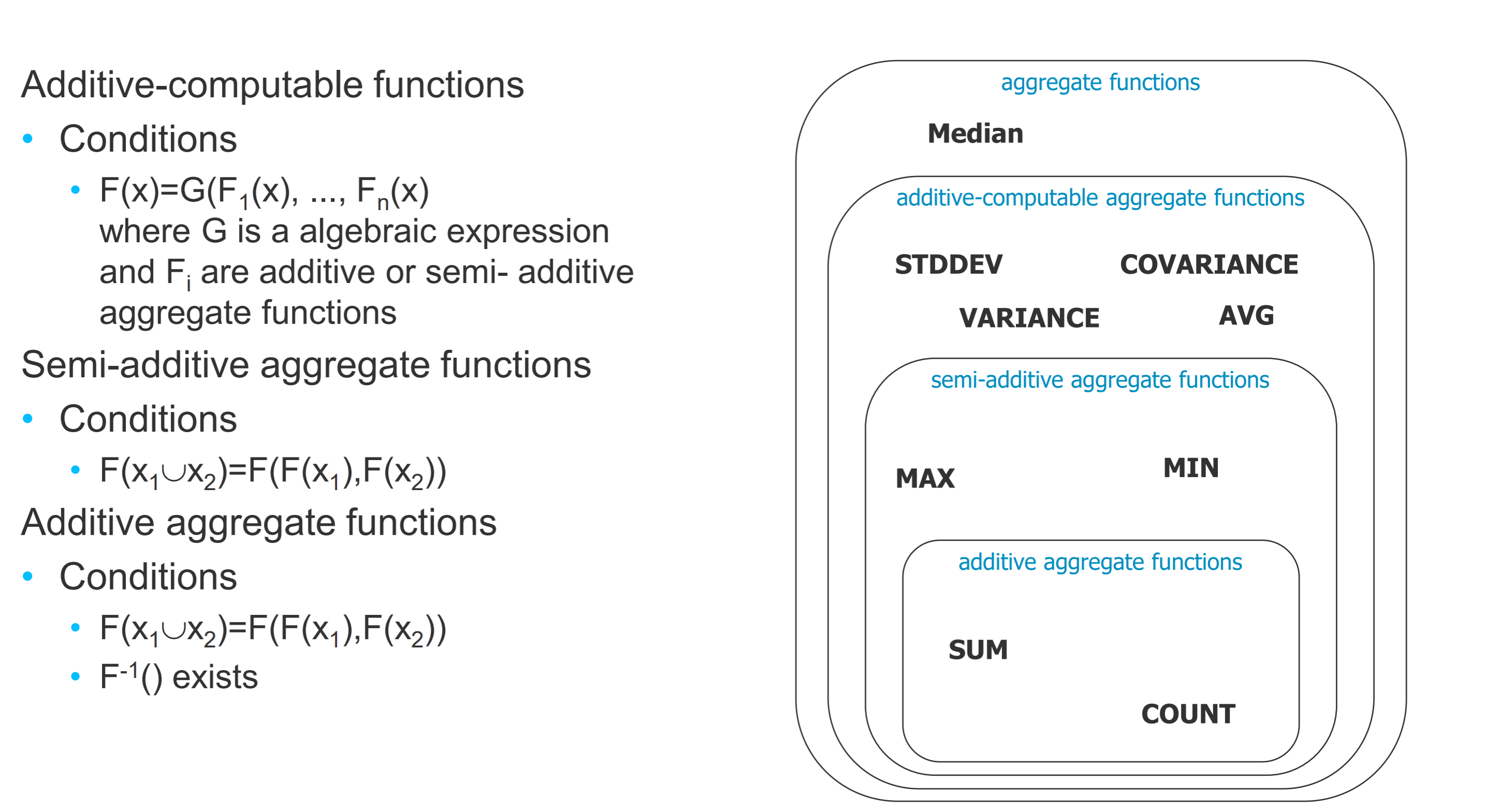
- 如求sum的话可以在两个union中分别求sum,再求总的sum
- 如求max,也可以分别再多个union中求最大值,再求最终的最大值
- additive aggregate function 存在逆函数,但是semi-的不存在
- additive-computable是在求additive function之后再作一步操作
- median是求中位数
- 如在source中删除了最大值,不知道第二大值是什么,但是sum等是可以计算的

- 如果A表,B表 join成了m表:
- 如果join丢失了数据(lossy),那么对A表的查询不能对M表执行
- 如果join没有丢失数据(lose less),那么对A表的查询可以对M表执行
- Groupings:

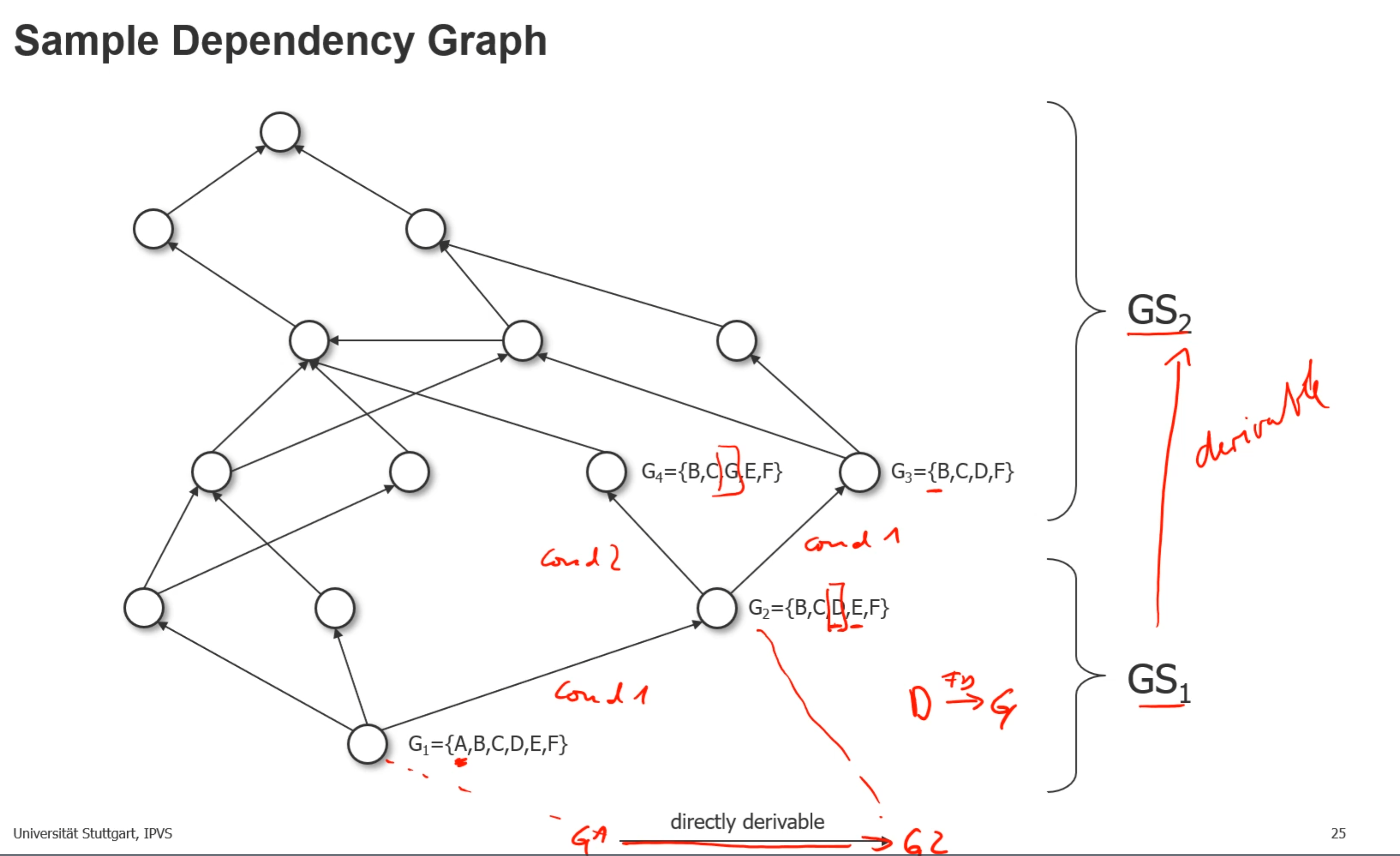
- Grouping set 2 is derivable from Grouping set 1,因为Gs 2中每个group都至少被一个Gs1中的group产生
- 以下两个条件满足一个就可以说明G1 directly derivable G2
- G2 比G1少一个属性
- G2 中有一个属性替代了G1中的一个属性,并且G1中的那个属性functionally determined G2的那个属性
- 可以用G3作为materiliaze view来加速对G2的查询(直接使用G3的数据而不是从source中查)
- 数据量会随着Grouping的数量快速增加

- Predicates:谓词的限制要比summary table要高:如下图,query中有where子句,但是summary中没有,所以在查询的时候满足restiction高的条件,sales就直接从summary data中取,而不是从原始数据中拿
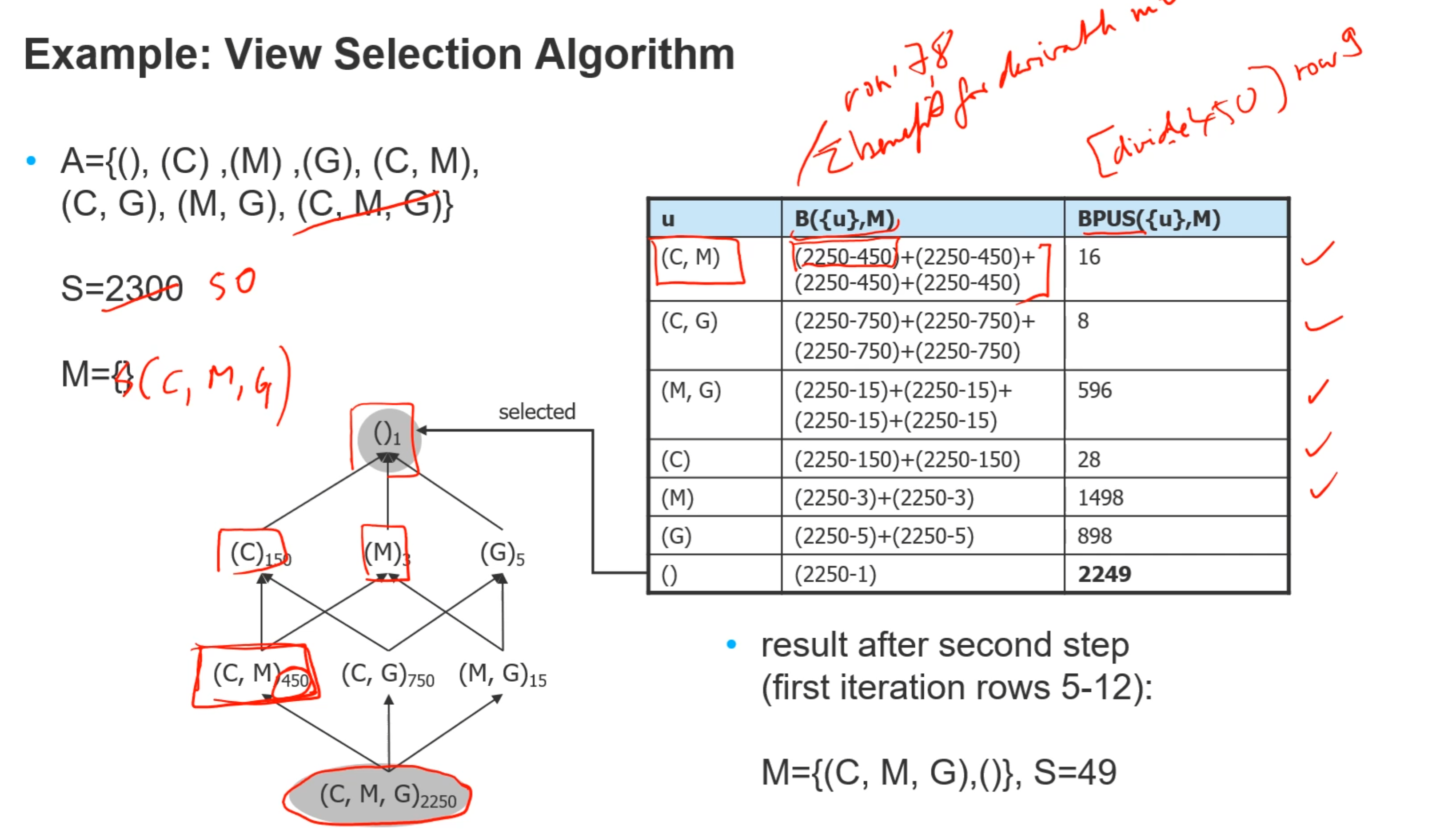
# 计算materilize view的benefit
benefit per unit space: BPUS(u1,...,uk, M)=Benefit/unit size
算法:看ppt中例子,也可以直接根据大小来选择
- 新view: u
- 已有的view:M
- query: q
- 选取没有被test过的u,让每个query对u+M进行计算u产生的benefit
- 取最大的BPUS所对应的u,把u并入M中
- 选取CMG时,分别计算其他组合,由于(),(C),(M),(CM)能derive from CM,所以Benefit是4个2250-450, BPUS就再除以450(size),把最大的BPUS并入总集合中
# INDEXS
Table scan: 扫描整张表,看是否满足查询条件
Index scan:用index来标记一行是否和查询条件相关,查询就只用在相关的列中筛选
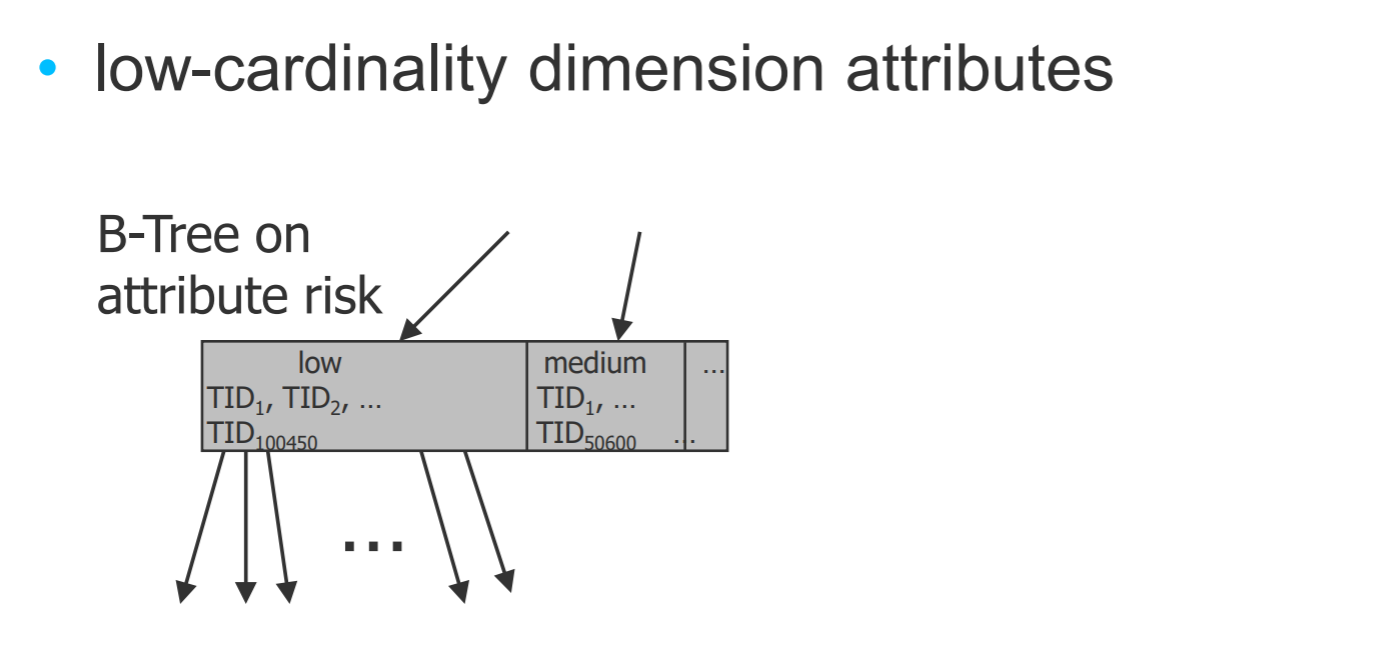
Indexes on dimension tables
- 当某个维度只有三个值:low,medium,high的时候,就可以使用索引
Indexes on fact tables
通常查询对主键进行筛选,主键一般由多个属性共同组成,所以可以使用共同组成的index
但是会有两个问题,属性组合的顺序,index过大
BitMap indexes: 查询结果一位一位竖着计算,比如第一行是O,第二行是O,所以O的前两位是1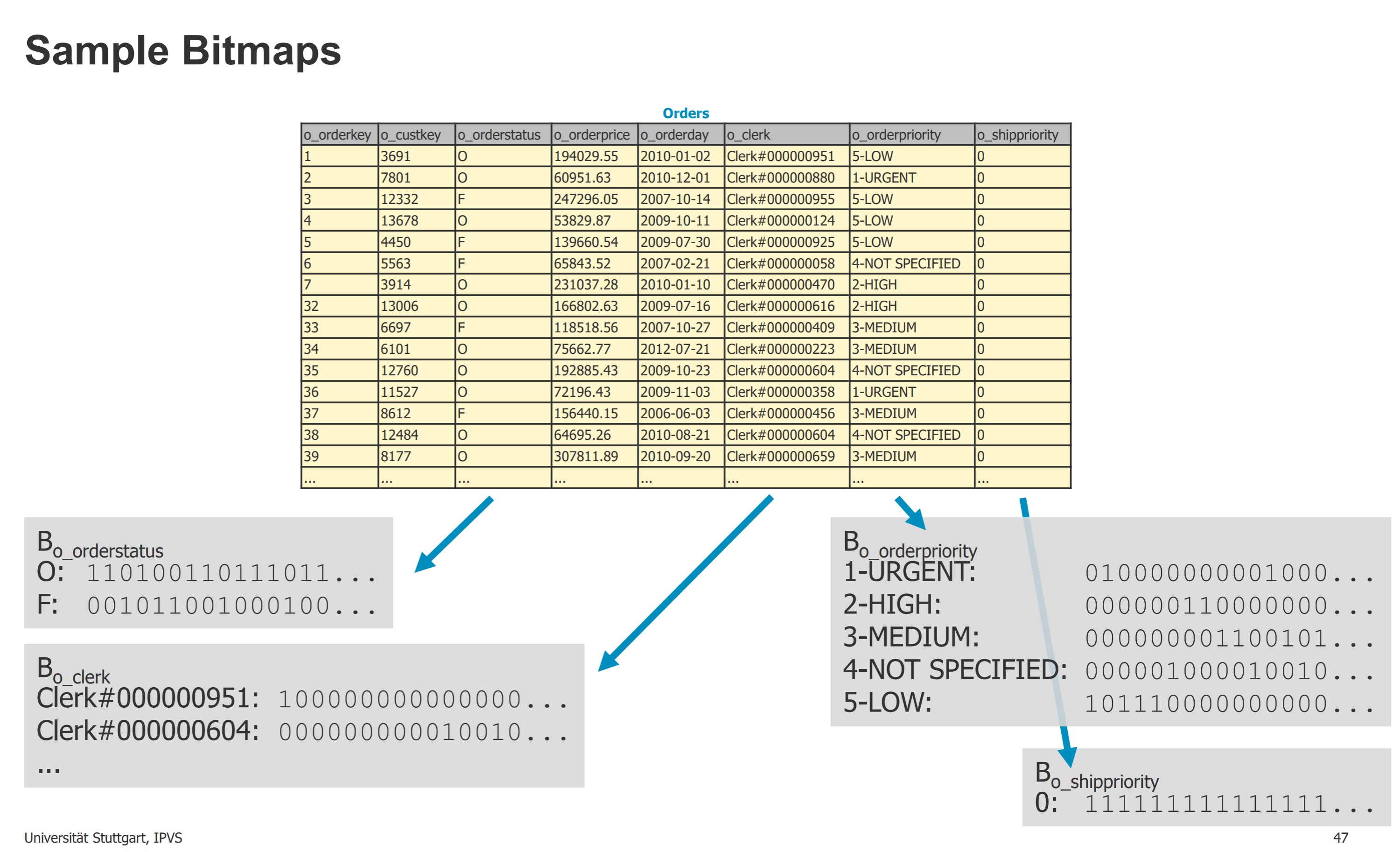

Combining One-dimensional Indexes
- MDB tree:does not treat all dimensions equally
- UB tree