Ch07 Data Mining
Yang Haoran 12/21/2021 DataData warehouseData Mining
# Data Mining
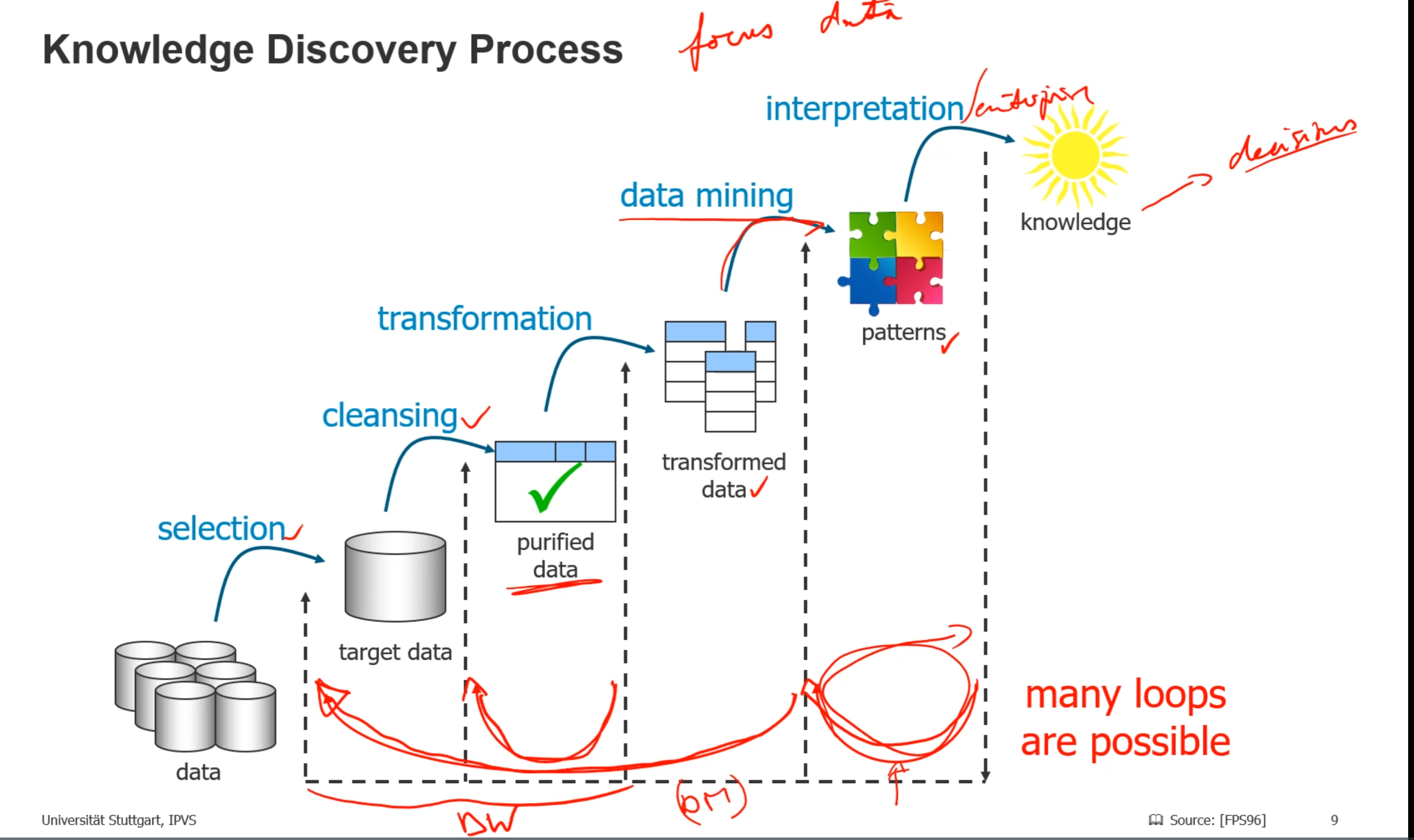
Data --> Information --> knowledge --> decision

Knowledge discovery process
Data mining的挑战(ad hoc data是临时数据)

# Data mining techniques

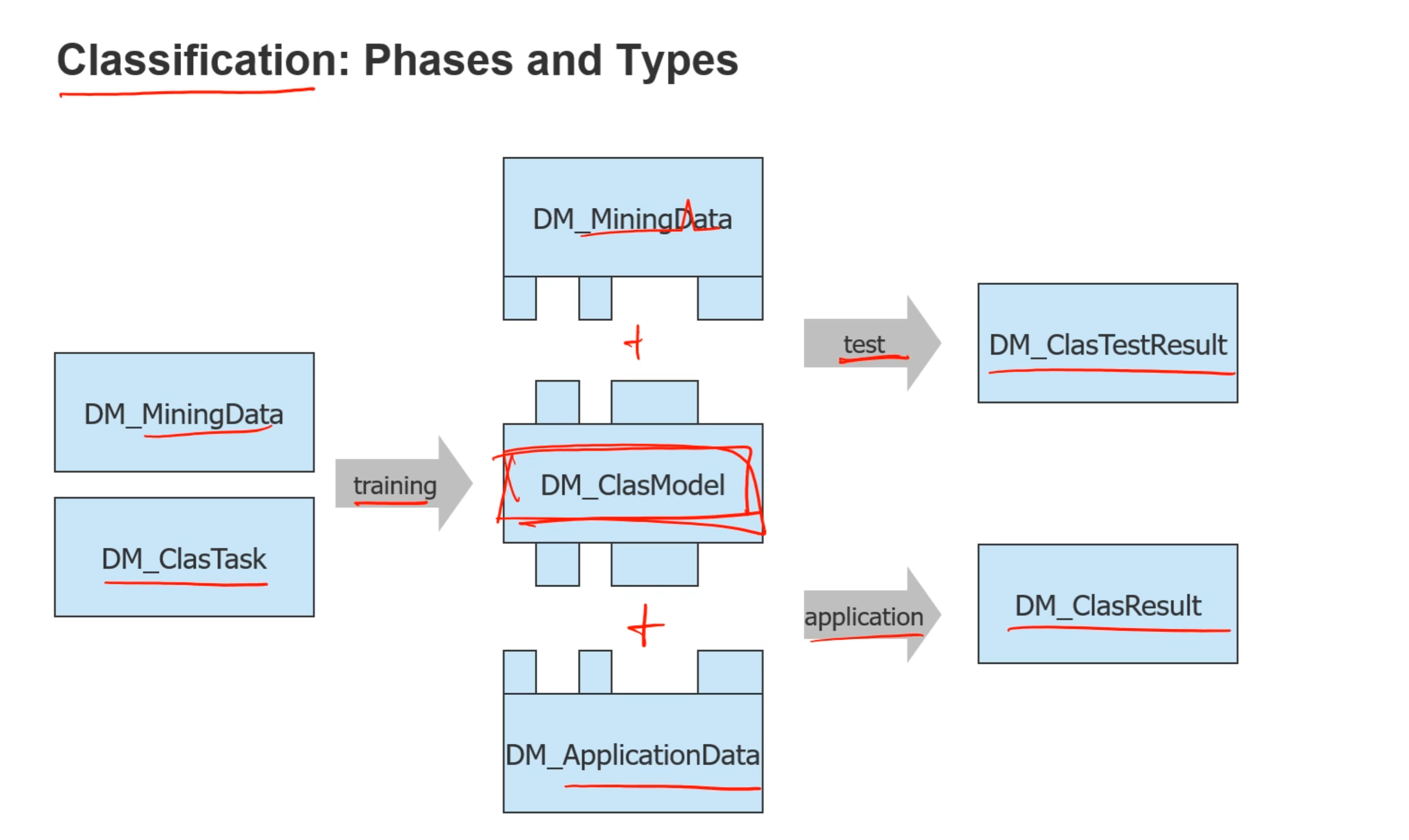
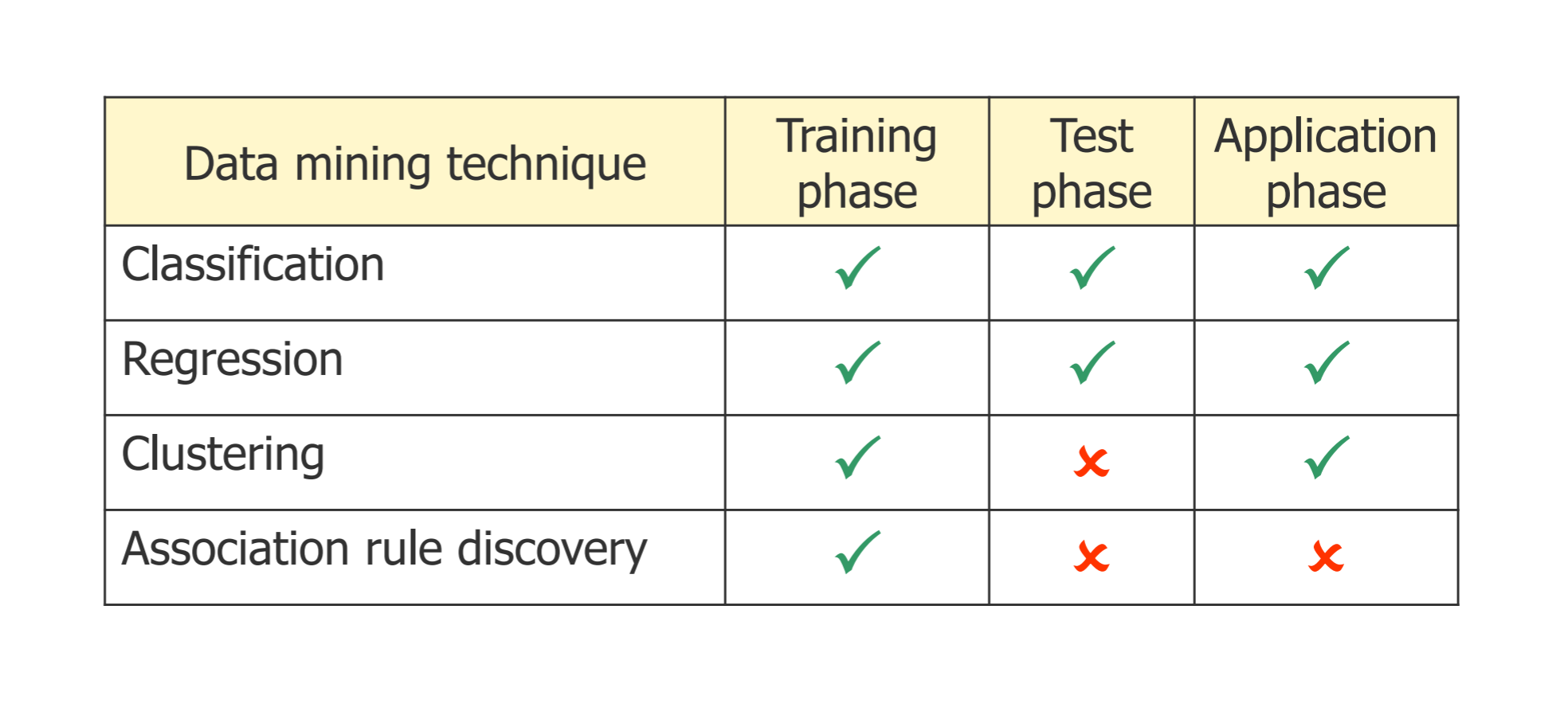
# Data mining phases:
- Training phase:

- Classification:
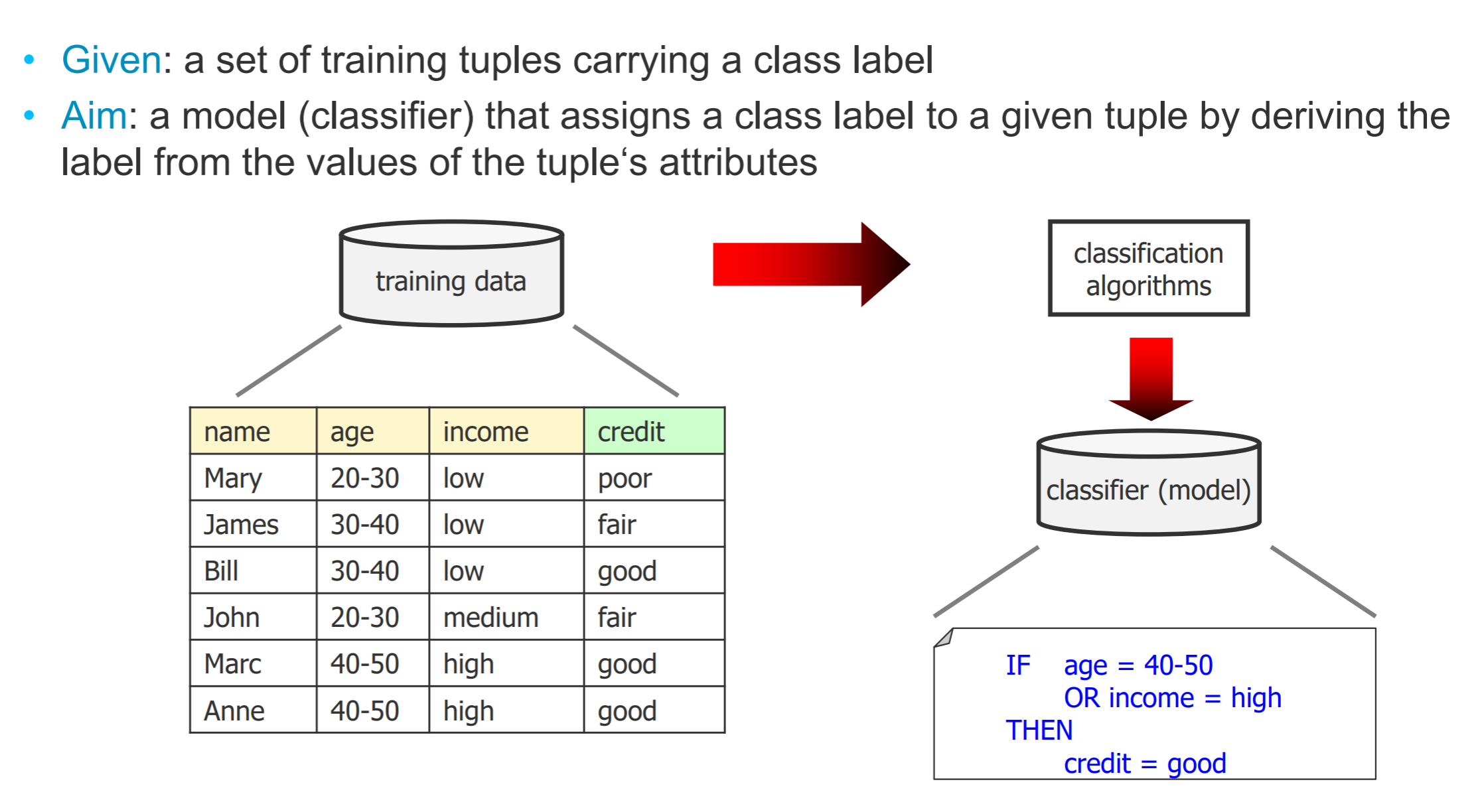
- Classification:
- Test phase:
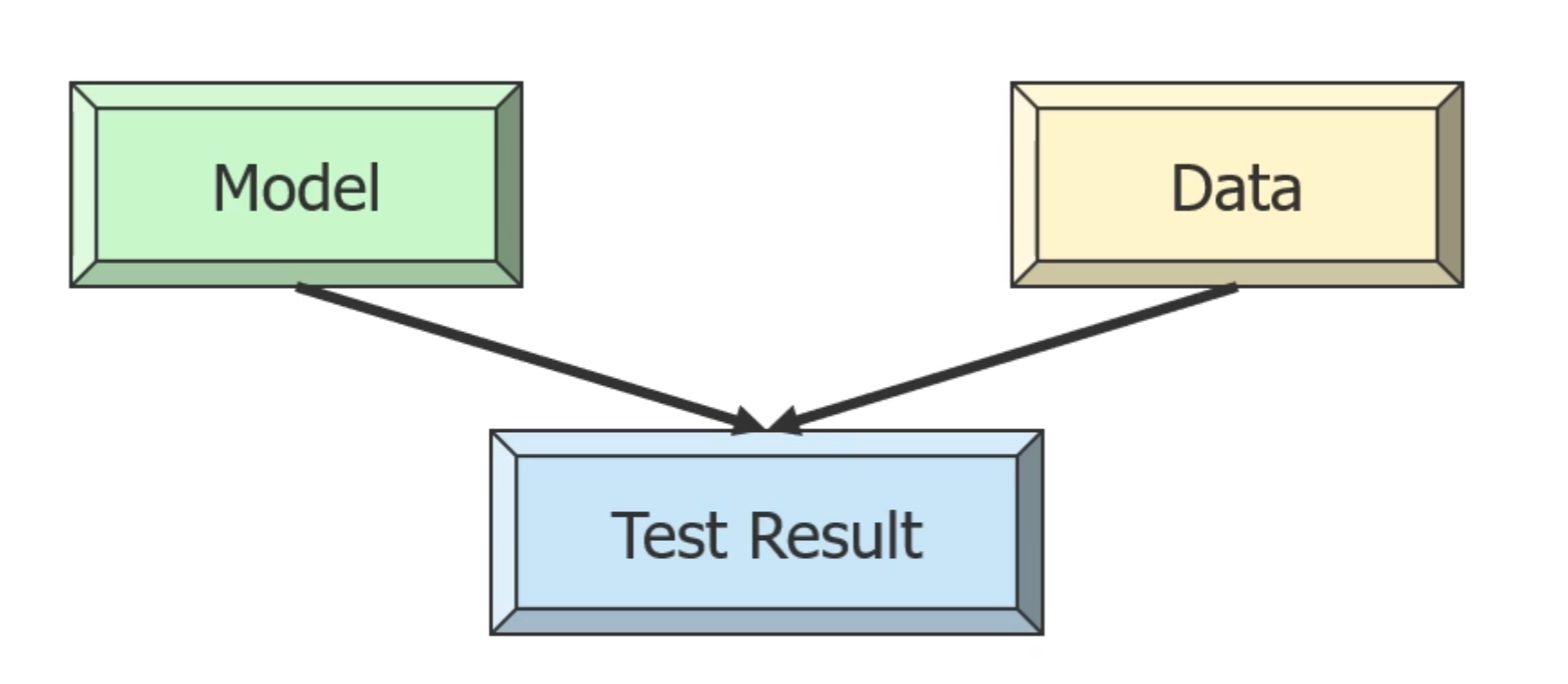
- Classification:
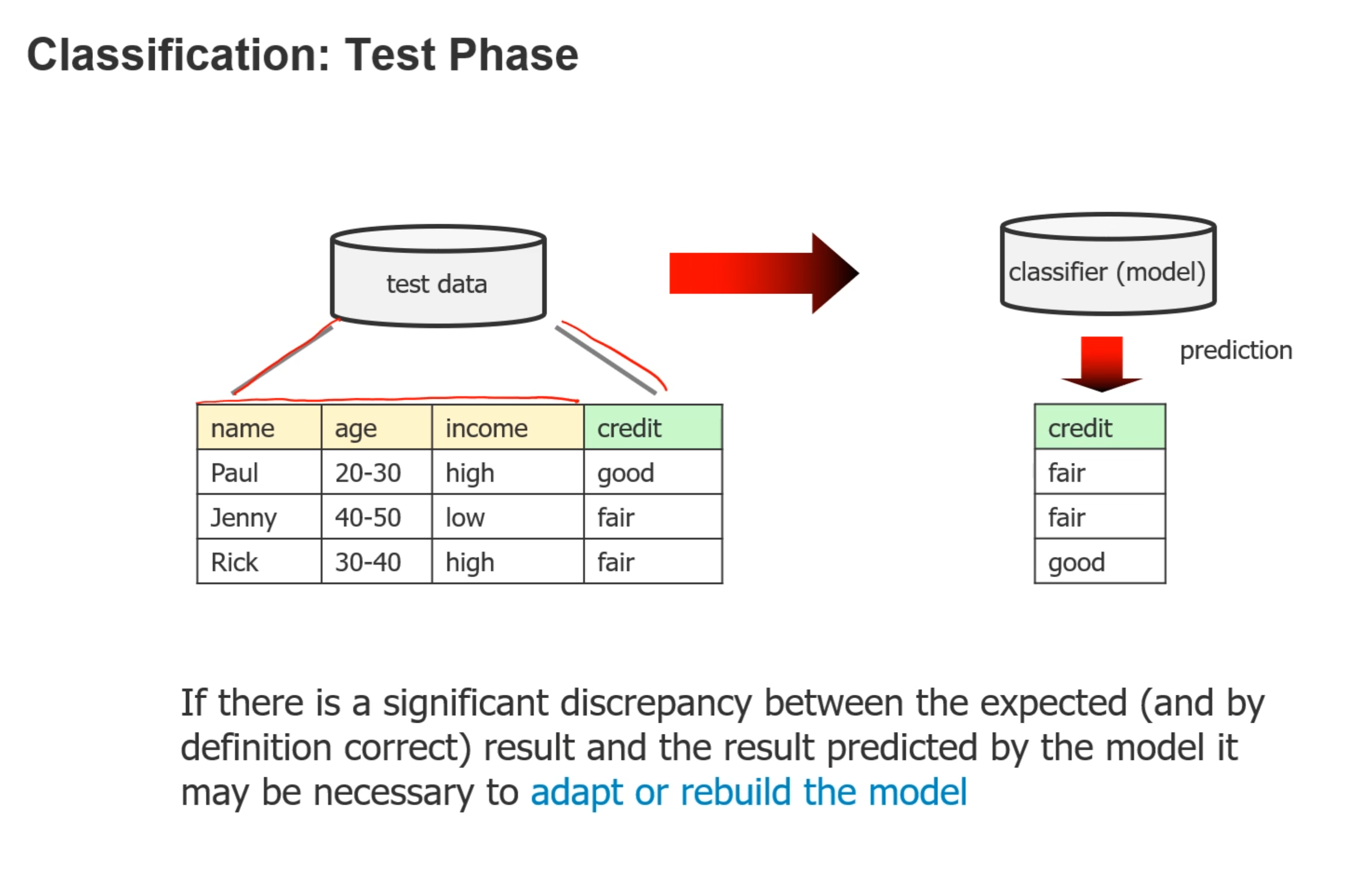
- Classification:
- Application phase:

- 比如给新的数据分类,会给他一个cluster id和confidence(对此次分类的确定程度)
- Classification:
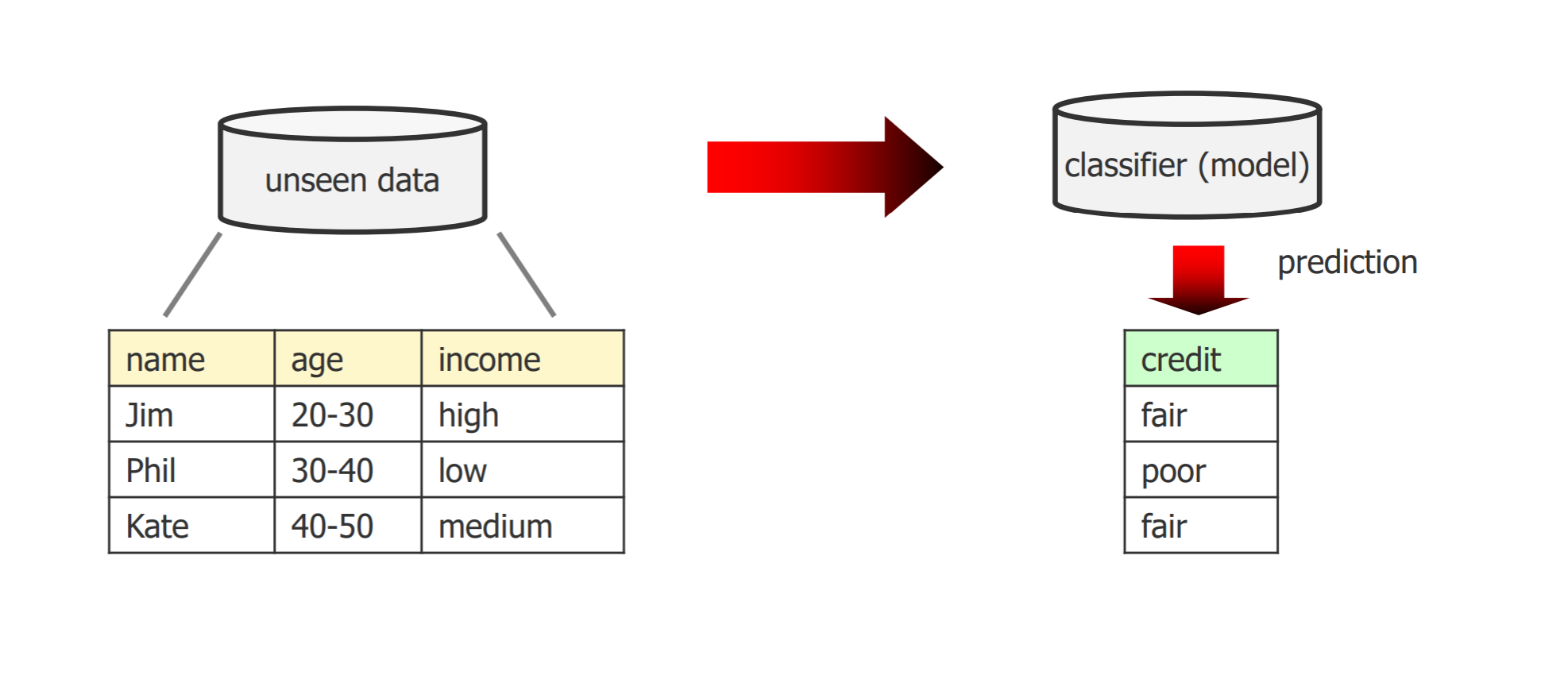
- 总结:
# Association Rule Discovery
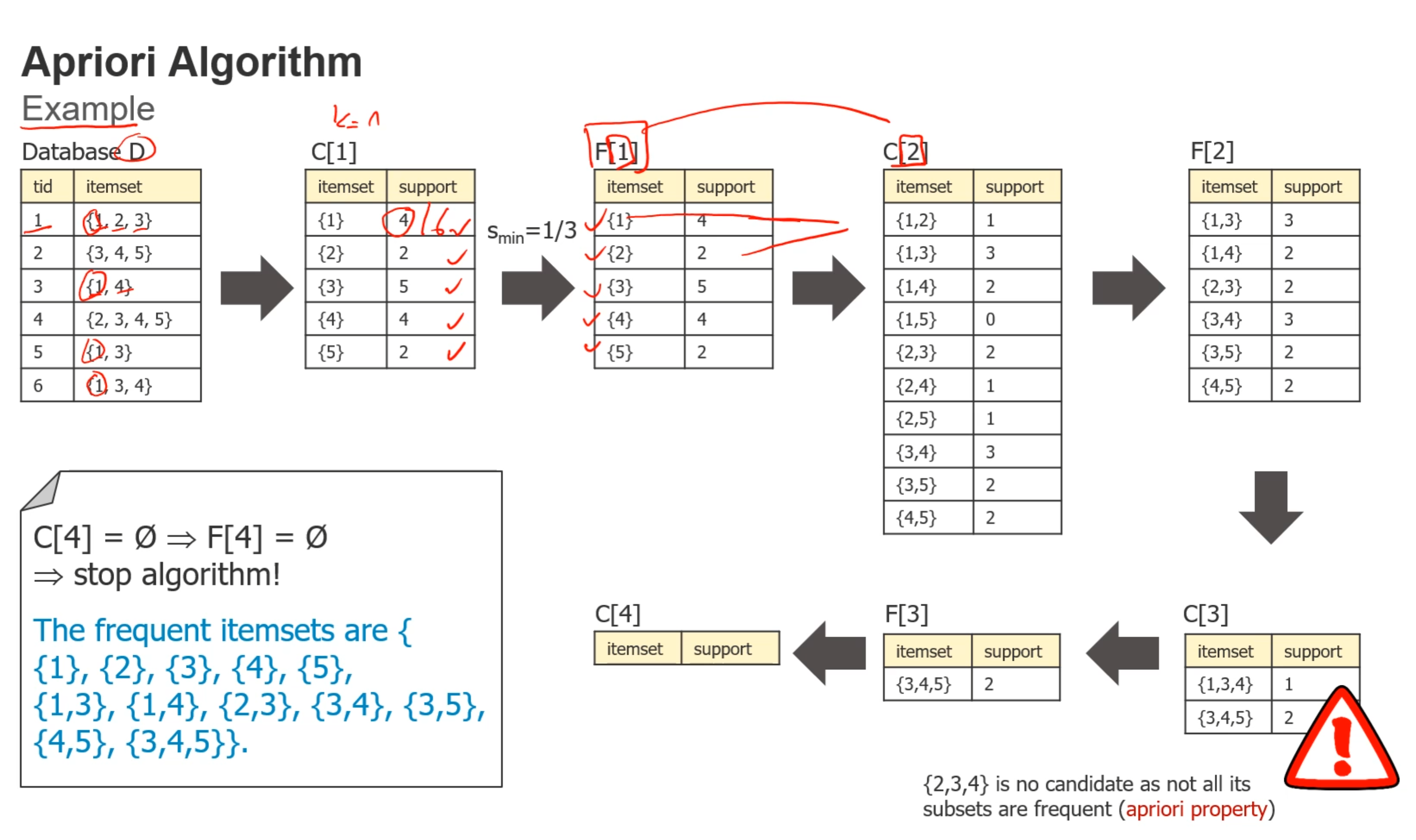
itemset 表示一行数据

在表中有三个transaction,分别tid为 101,102,103
比如beer的support:beer在两个transaction中出现了,总共有三个transaction,所以是2/3
满足 support 和confidence大于某个最小值的时候,则这个rule成立

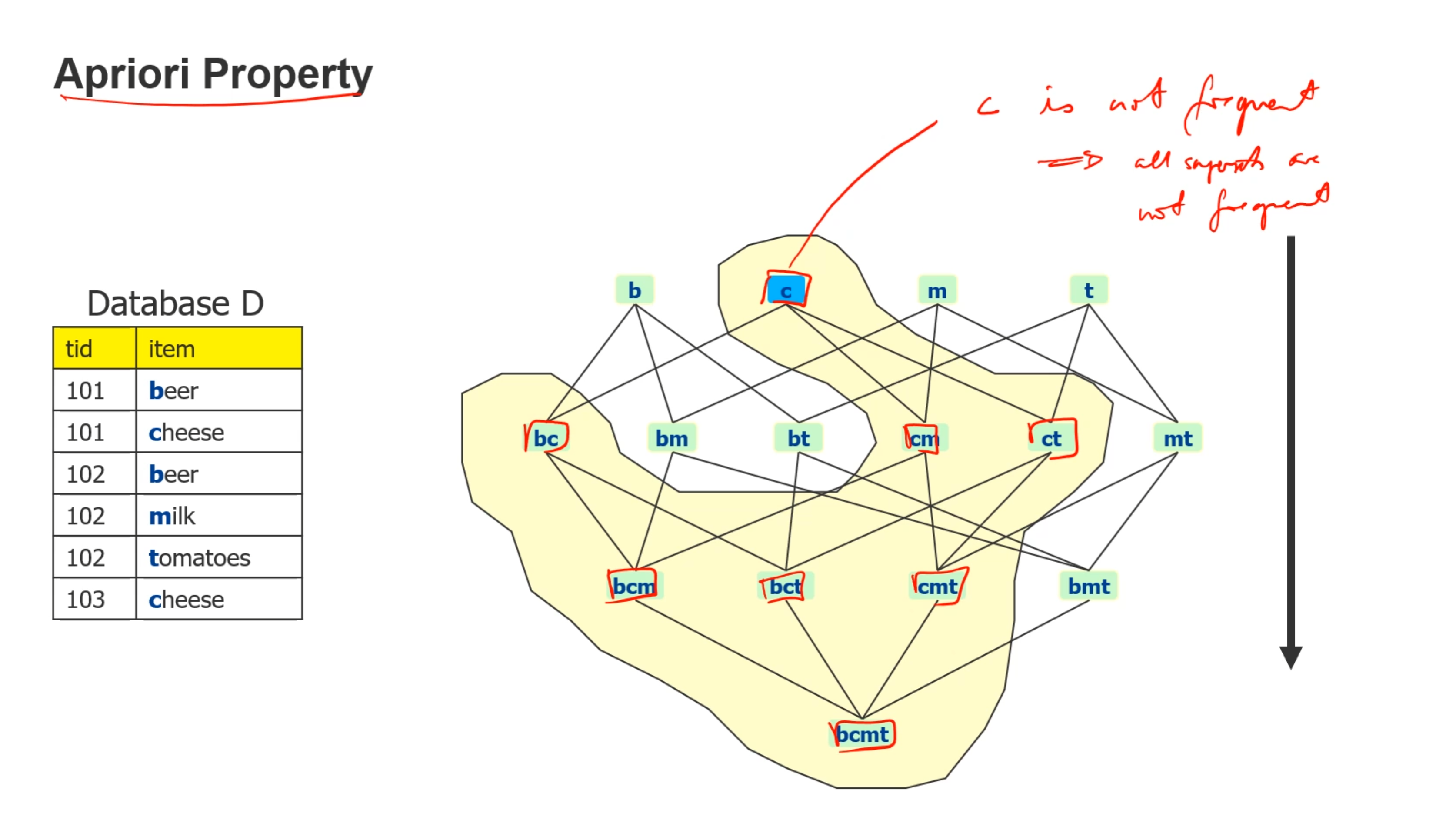
由于每个support算起来开销太大,使用apriori property来简化计算,当一个组合的support大于最小值的时候,他就是frequent,所以当一个集合的support 是frequent的时候,他的子集也都frequent,也就是2的n次方个子集
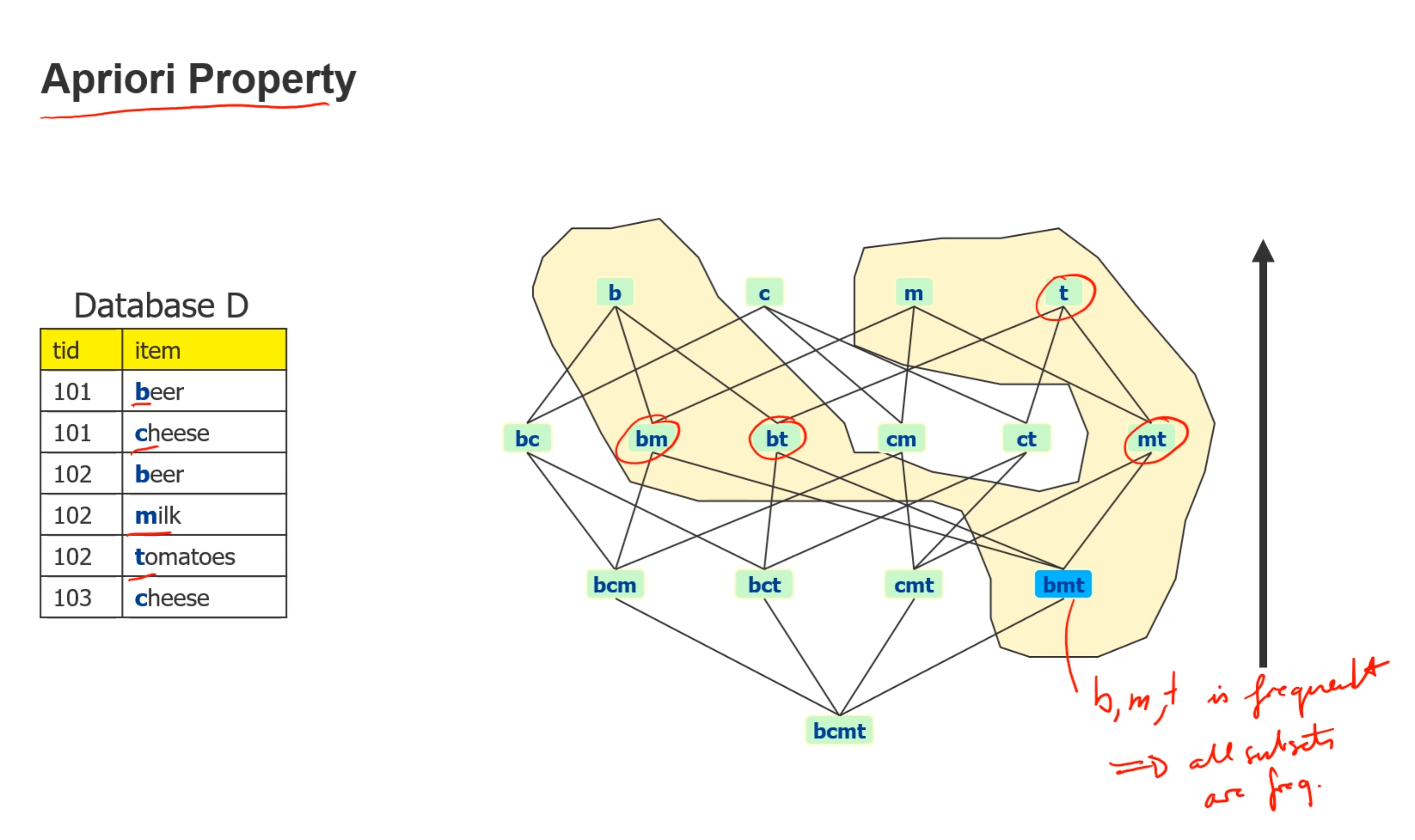
并且,当c不是frequent的时候,所有包含c的父集都不是frequent的
- 寻找frequent集
寻找frequent itemset的算法:F[k]是满足条件的itemset(S>Smin)从子集开始判断,寻找符合条件的父集
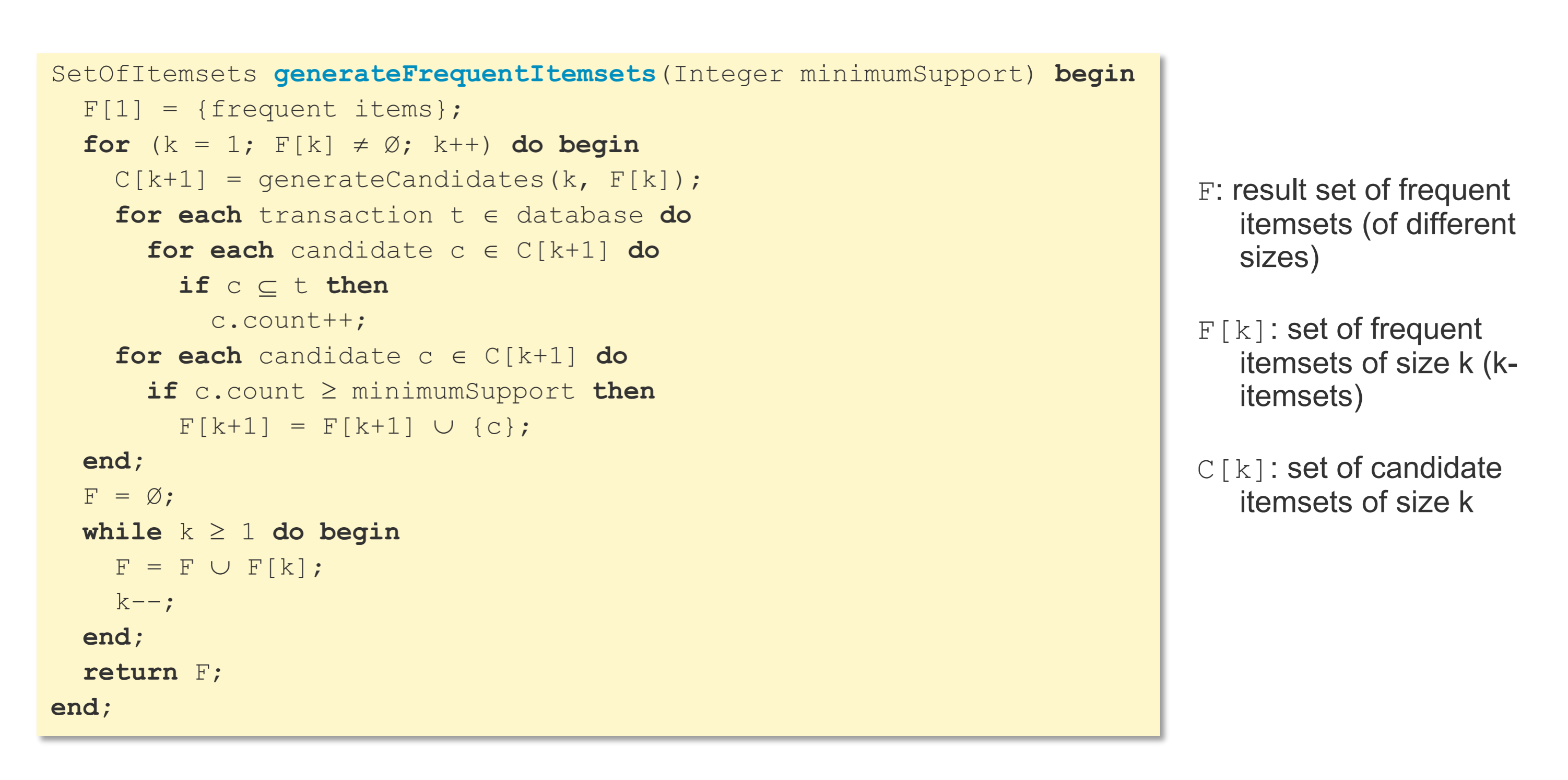
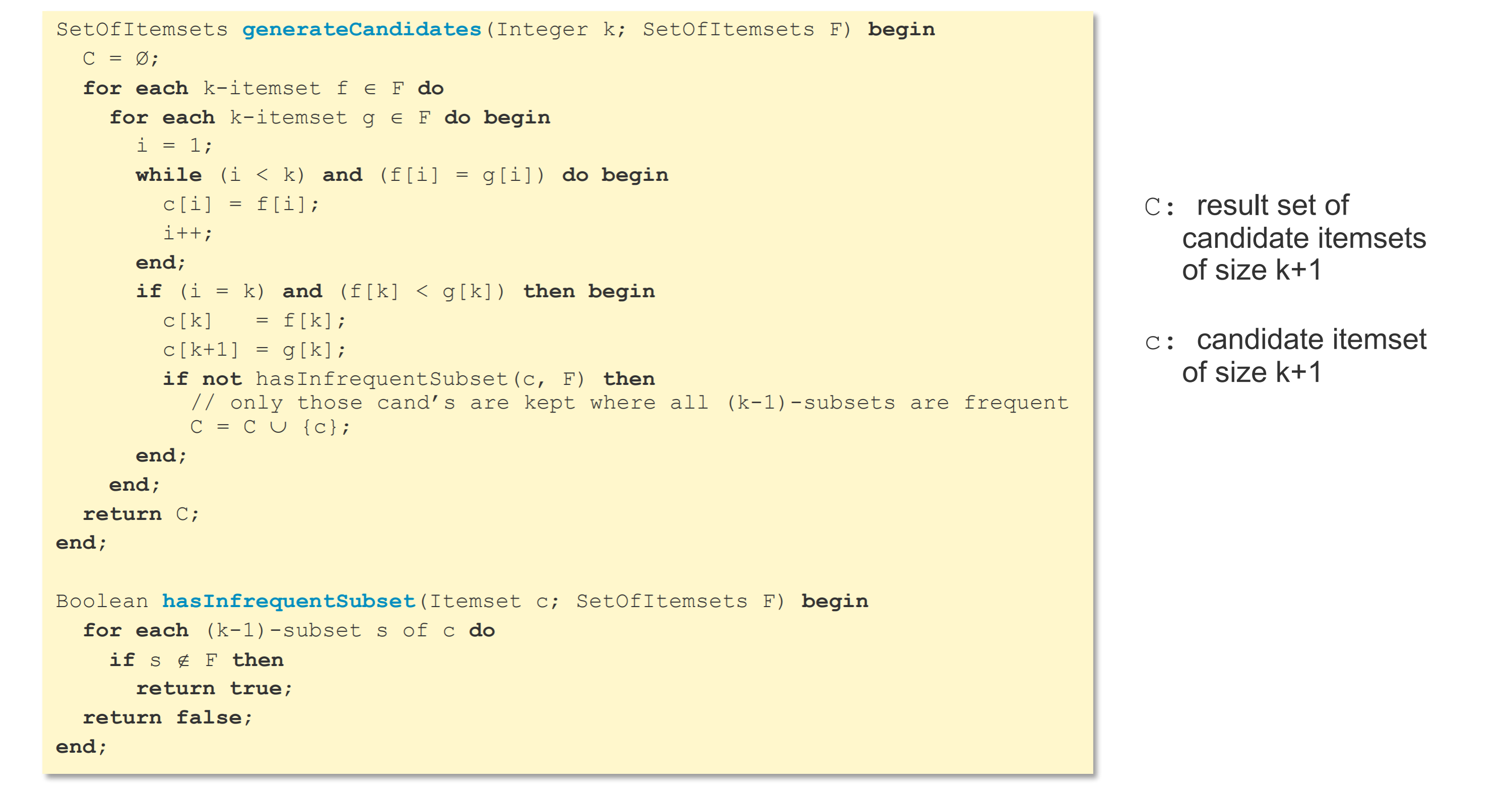
- 子集是frequent,父集才有可能是
- 子集不是frequent,父集就不可能是
- 父集如果是frequent,子集一定是
sql语句实现,在原来frequent集的基础上加一个元素,组成下一个candidate集

- 可以用剪枝算法改进
- 寻找rule:C(L,R)=S(L ,R)/S(L)
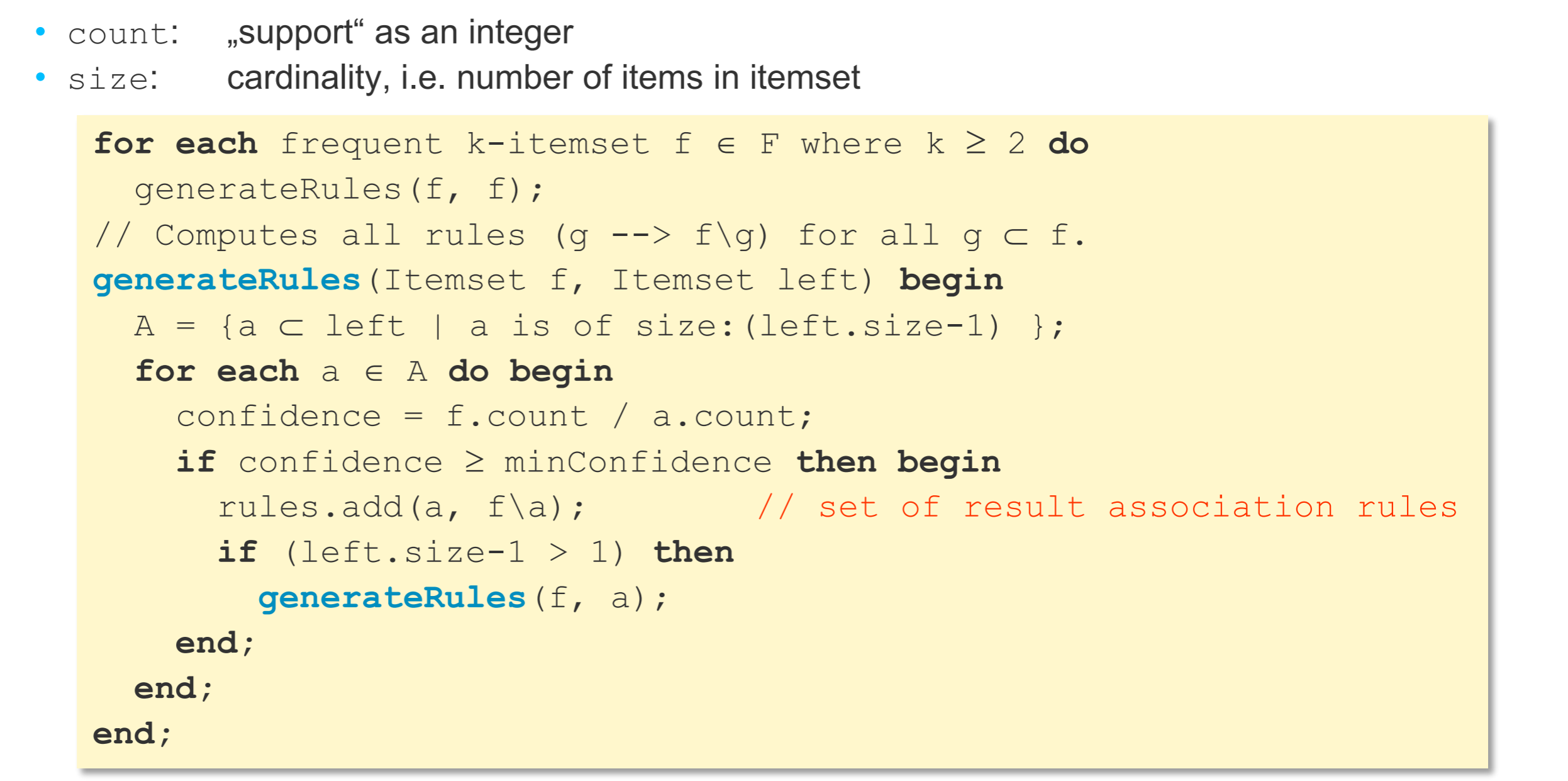
- 性质:若父集不能-->, 则子集更不能-->, 因为子集的support更大,所以confidence更小

- 所以{3 ,4} --> {5} ,才有可能{3} --> {4,5}, {4} -->{3,5} (父集能产生,则子集才有可能能产生)
- 所以从父集开始判断,寻找符合条件的子集
- 如果子集可以,那么父集一定可以
- 性质:若父集不能-->, 则子集更不能-->, 因为子集的support更大,所以confidence更小
- 寻找rule:C(L,R)=S(L ,R)/S(L)
Association rules 的种类:

Constraint-based Association Rules:
- 独立事件:意思为事件A不影响事件B的发生,称这两个事件独立,记为P(AB)=P(A)P(B)
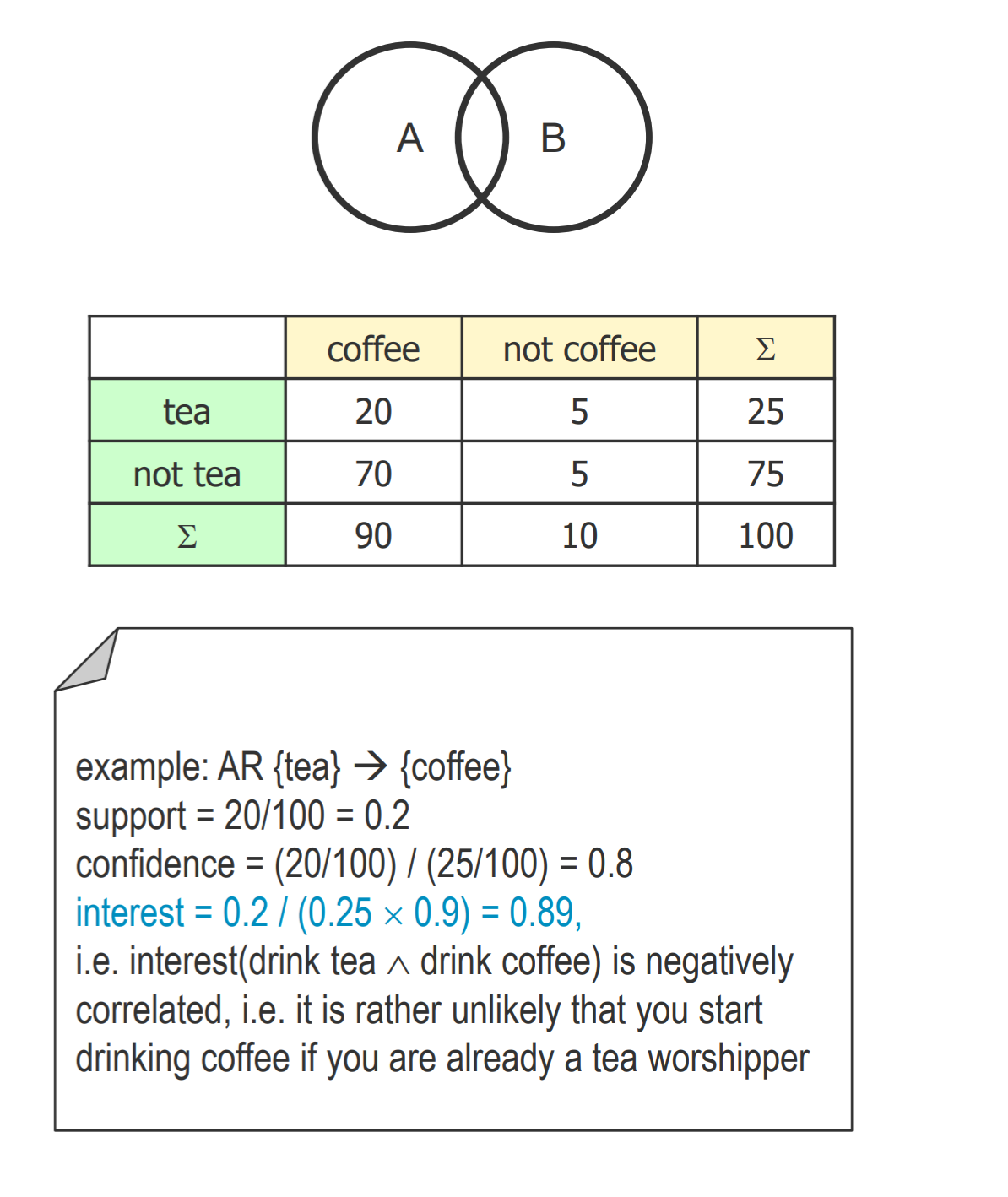
- Interest:

# Clustering
Partitioning
K-means algorithm: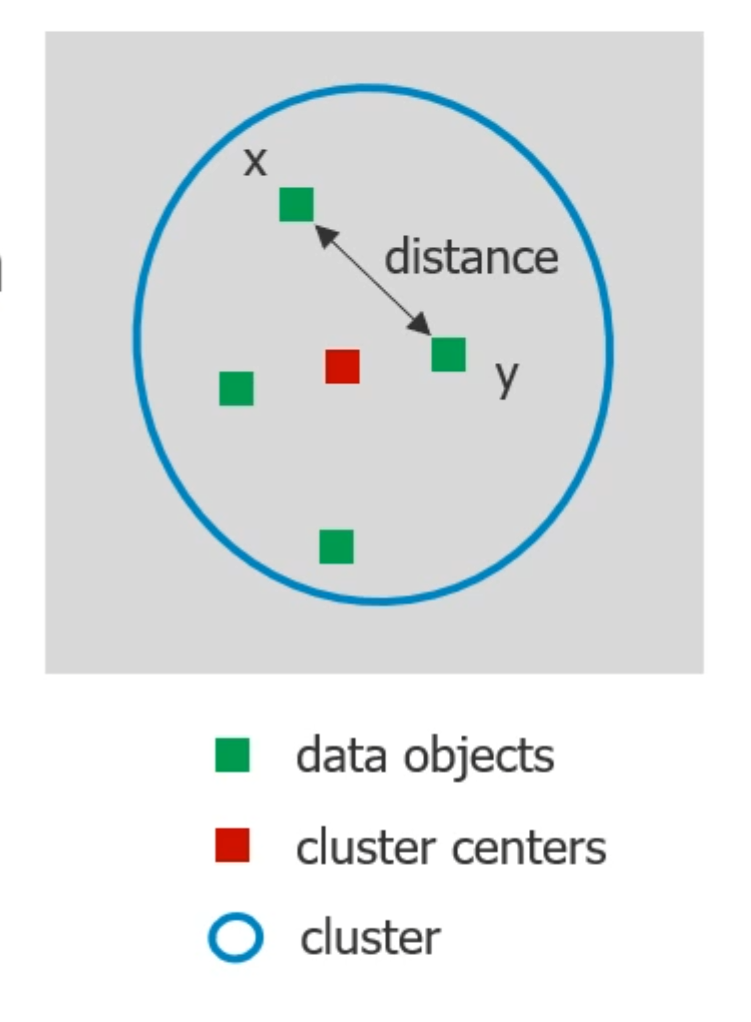
- 两个点之间的距离:

- 算法:
- 先指定一些点为cluster的中心,循环2,3,直到没有改变
- 计算所有的点到哪个中心的距离更近,归类为cluster
- 计算每个cluster的平均值,把这个值作为cluster的新中心
- 最后的结果很大程度上取决于一开始指定的中心,并且极端异常数据影响大
- 时间复杂度:O(nkt)
K-Medoids algorithm:
- 时间复杂度:O(n^2 kt)
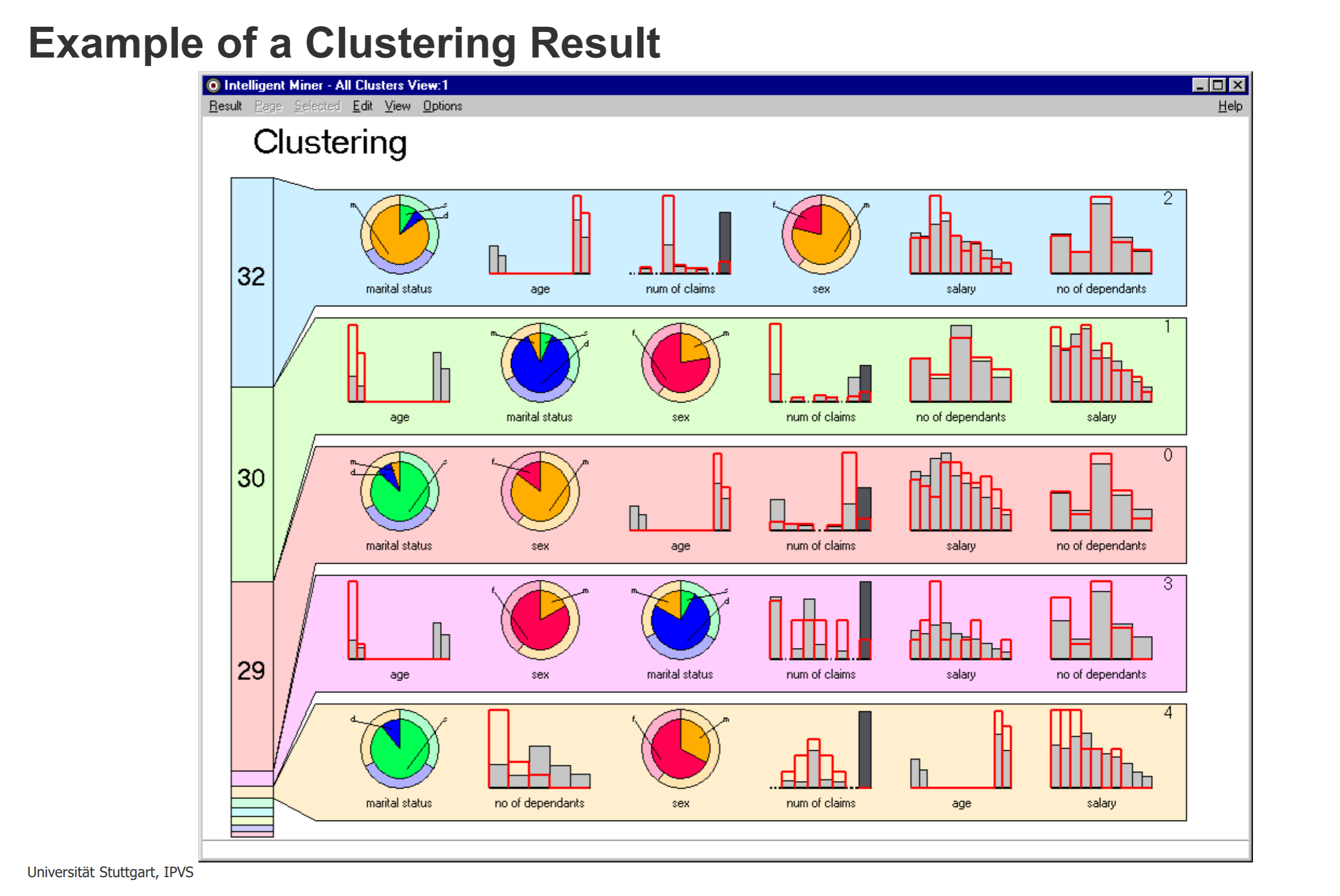
柱状图:continuous variables(灰色表示总的数据,红的表示在此cluster中的数据)
饼图:categories variables(内圈表示在此cluster中的,外圈表示总的数据)
- hierarchical methods
- top down:一开始只有一个cluster,每次迭代分裂出更多的cluster
- bottom up:一开始每个元素都是一个cluster,每次迭代merge cluster
- attribute不能考虑的太多,不然在cluster的时候最后有些重要的属性会被忽视

- 只考虑4,5,6是比较好的选择,因为他们关联性不强
# Classification
- decision tree

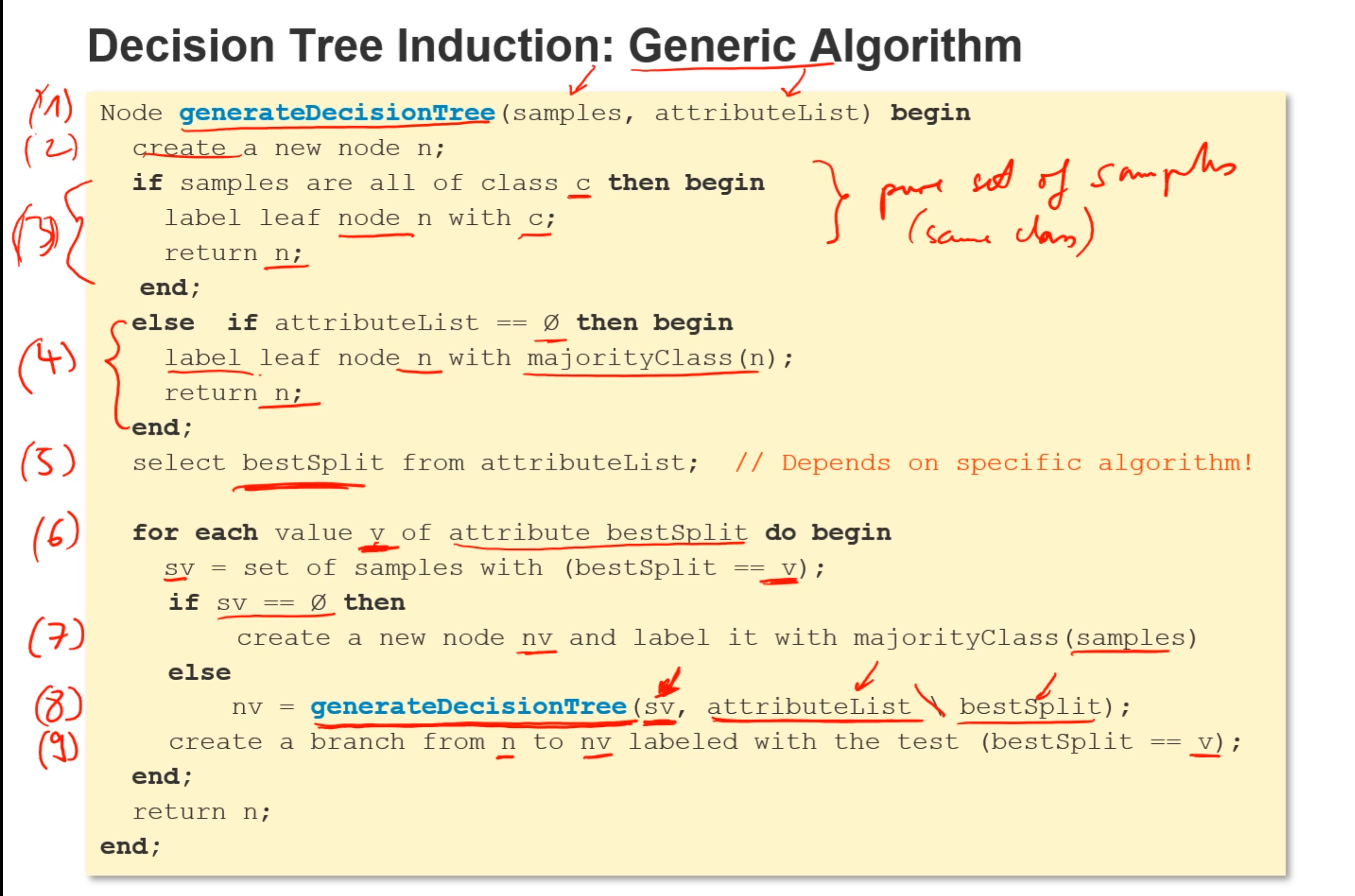
- 算法:第3,4块是用来判断结束递归,attribute list是分类的依据字段,每次都选择最佳分类字段
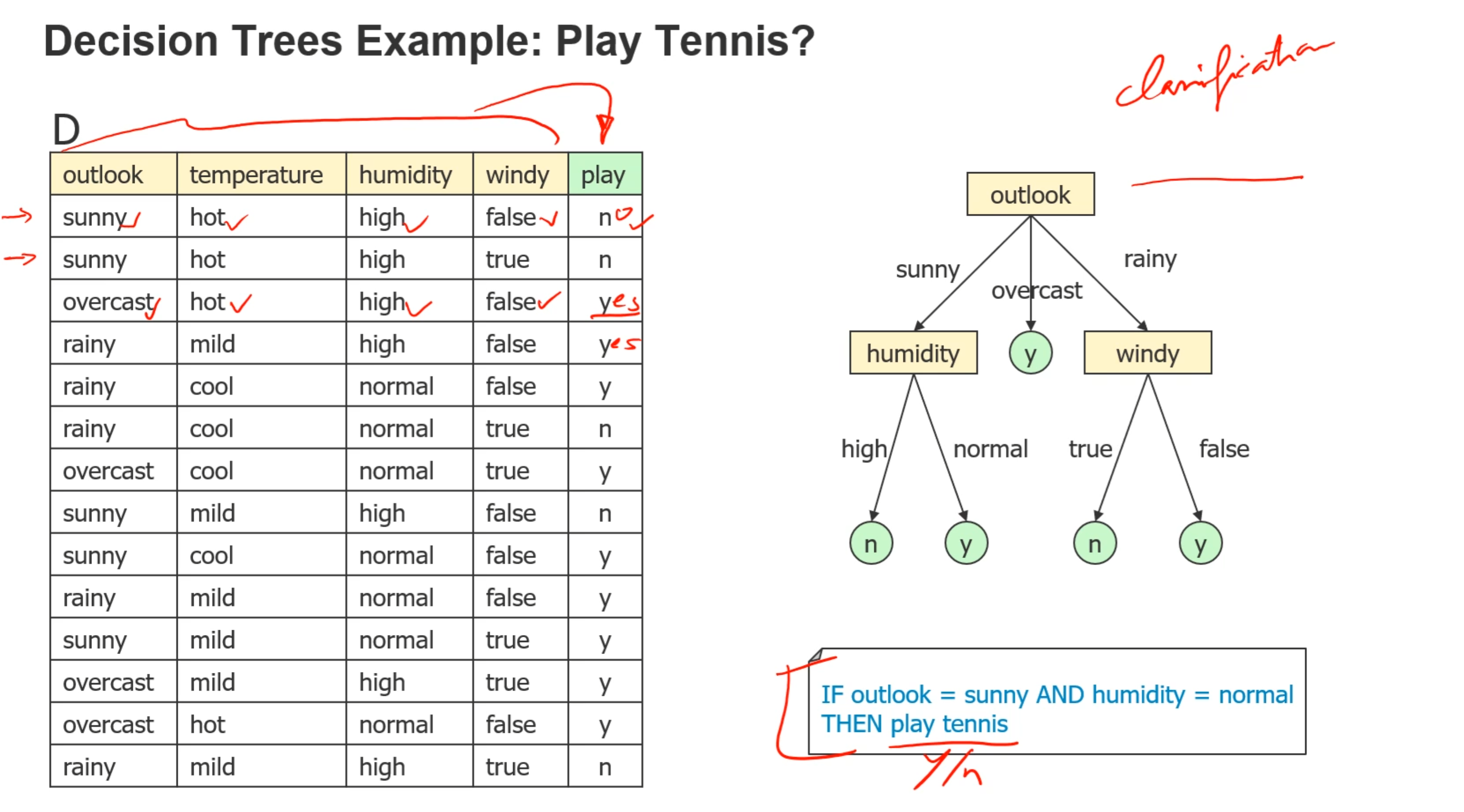
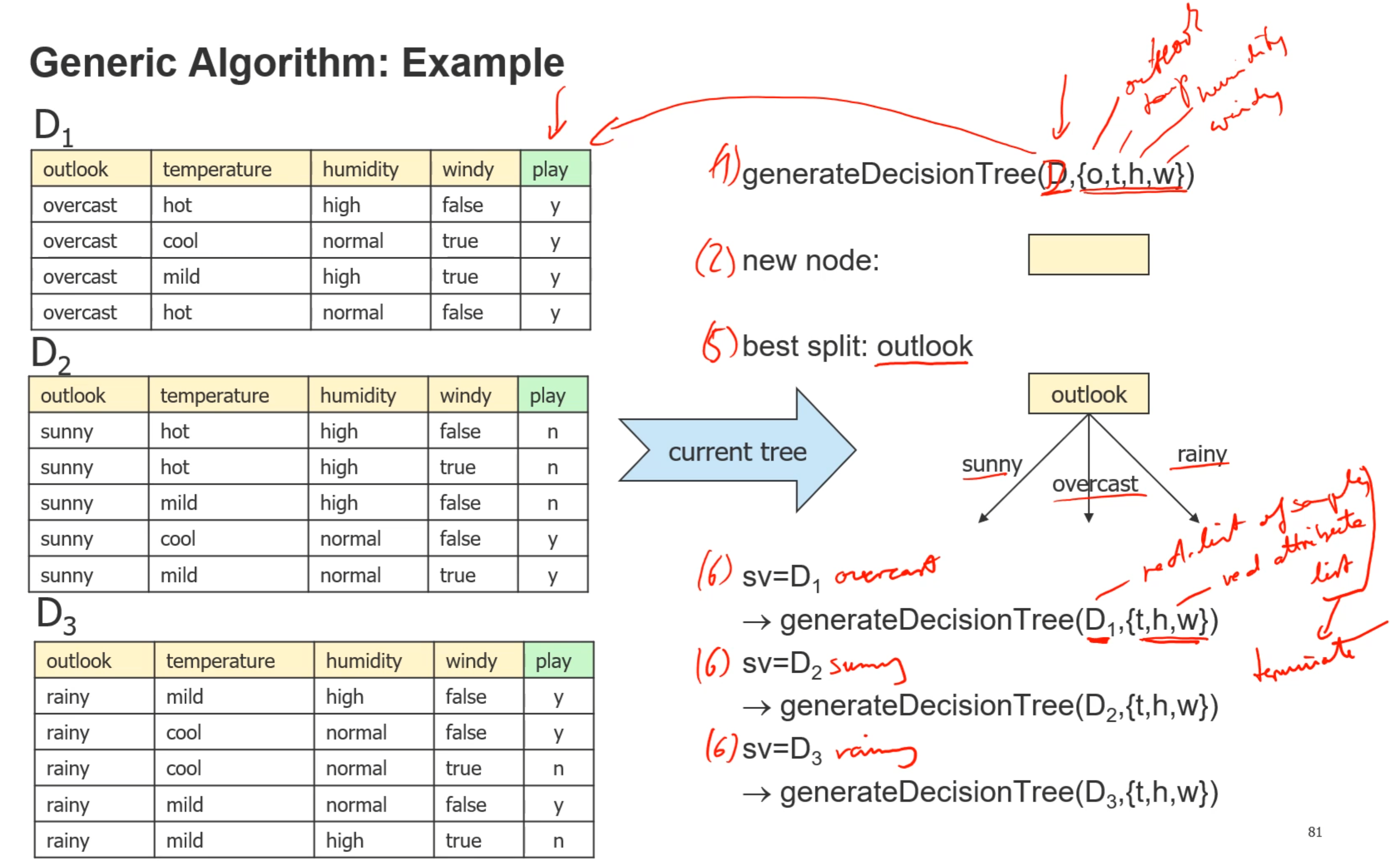
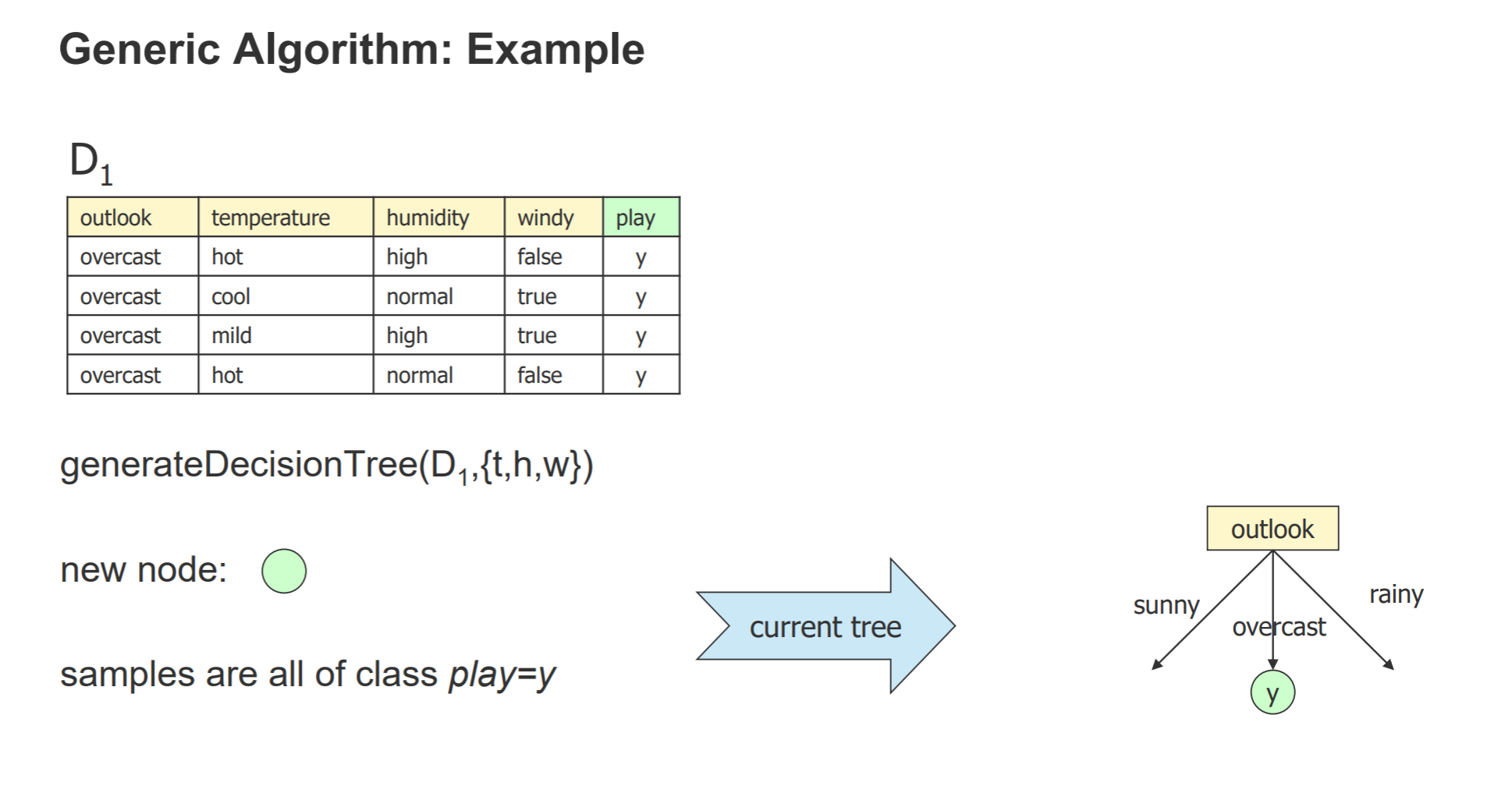
- 例子:


- (3)判断是否所有的数据的play字段都是一样的,是的话退出递归
- (4)判断是否已经没有可分类的字段了,是的话退出递归
- 最后的叶子节点的值取决于多数节点的值
- 可能存在过拟合问题:
- 可能是训练样本过小
- 也可能是噪声太大
- 两种解决过拟合的方法:

- 拆分数据的算法(在一个属性中如何拆分值):通过拆分之后信息的纯度计算,纯度越高越好(gini越低越好)

- gini(S)表示集合中数据的不纯净性,越大表示越不纯净,比如一个集合中有y的有n的
- 尽量找变量可以拆分出最纯净的集合,gini split相当于两个gini加权相加
- 例子:一个属性的set总共有2的n次方-2种(减去空集和全集)
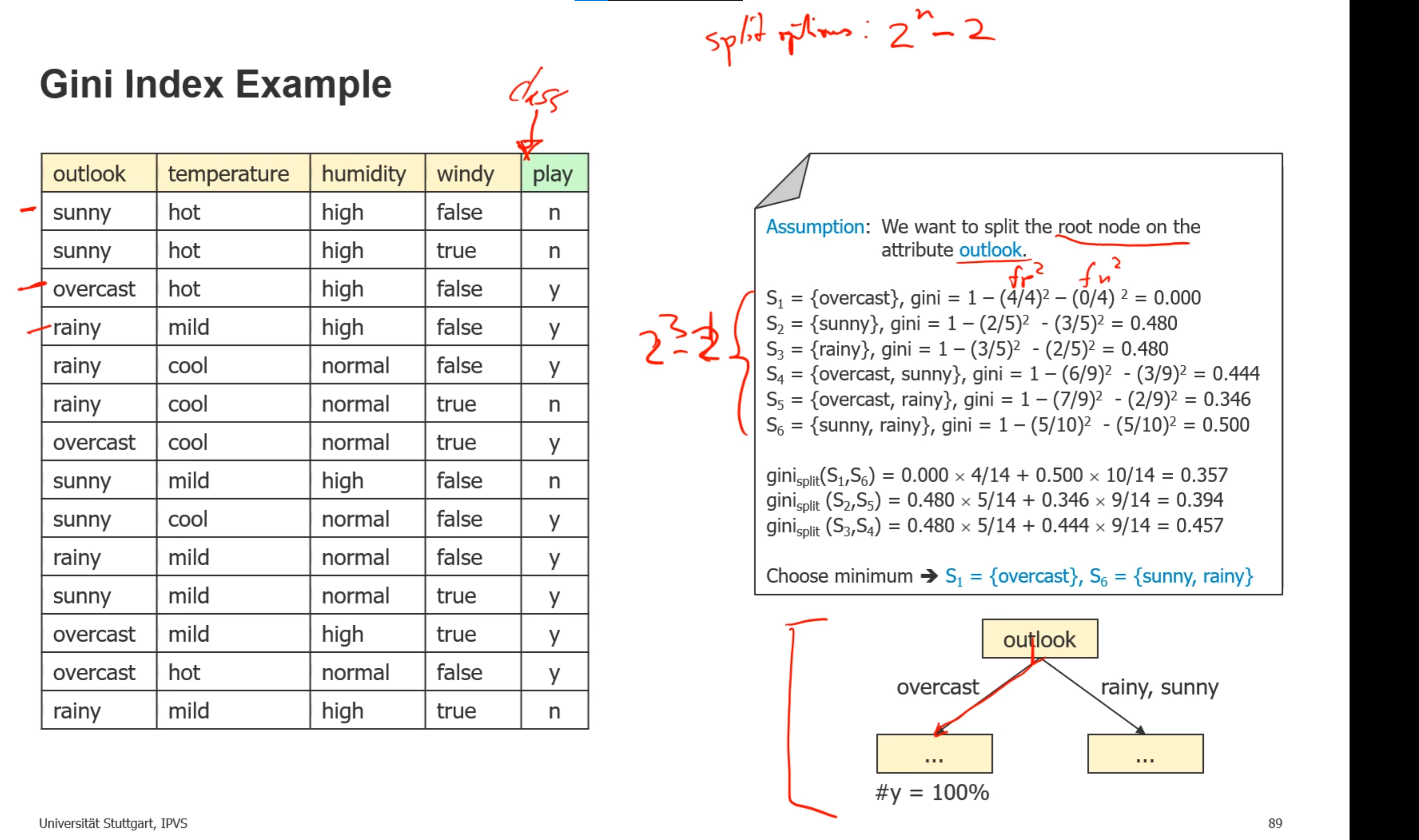
- 拆分数据的算法(如何选取拆分的属性):通过拆分获取的信息量计算,信息量越高越好

- 例子:分别计算原来的信息量与拆分之后的信息量,选取信息量获取最多的那个
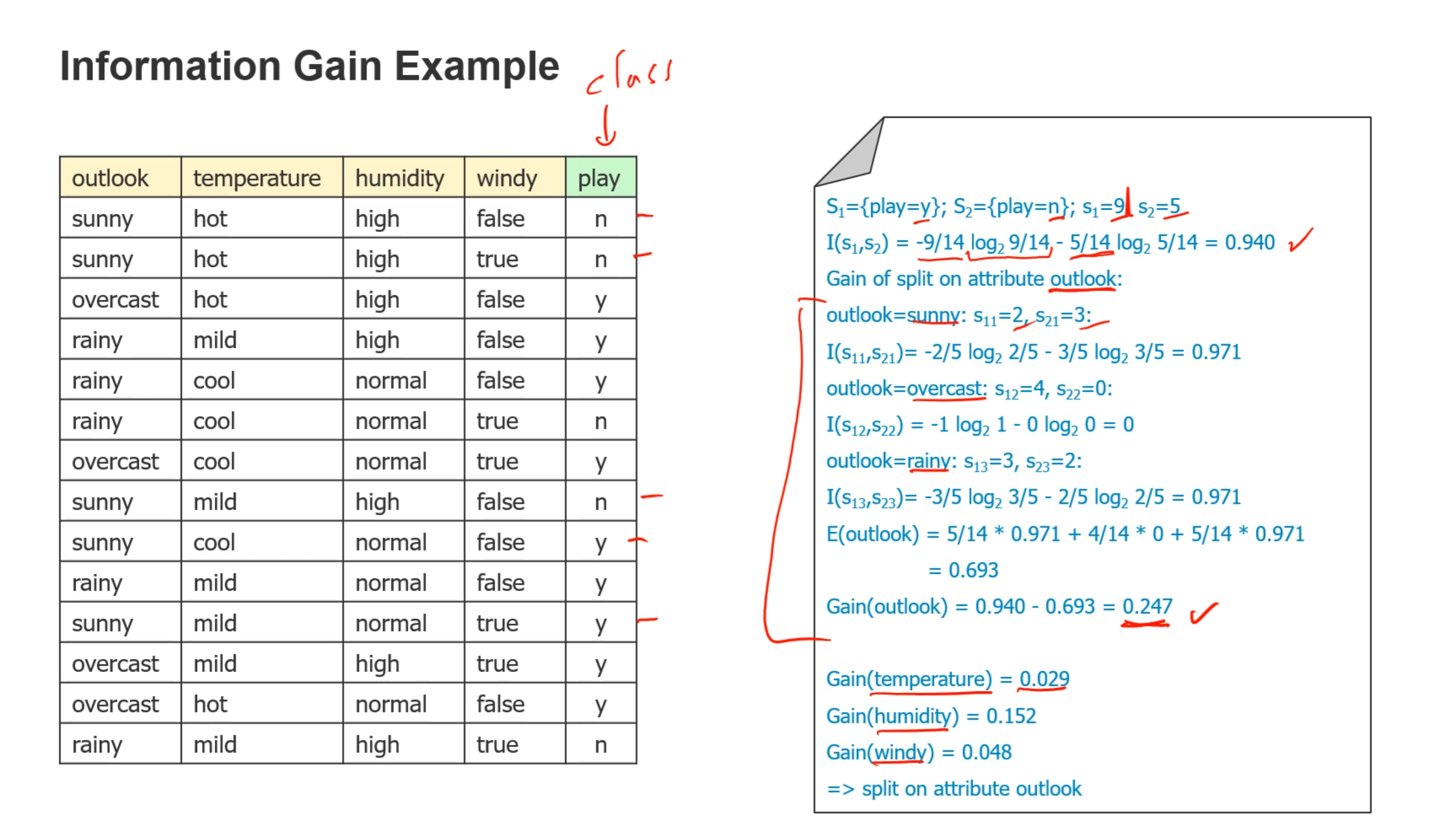
- 例子:分别计算原来的信息量与拆分之后的信息量,选取信息量获取最多的那个
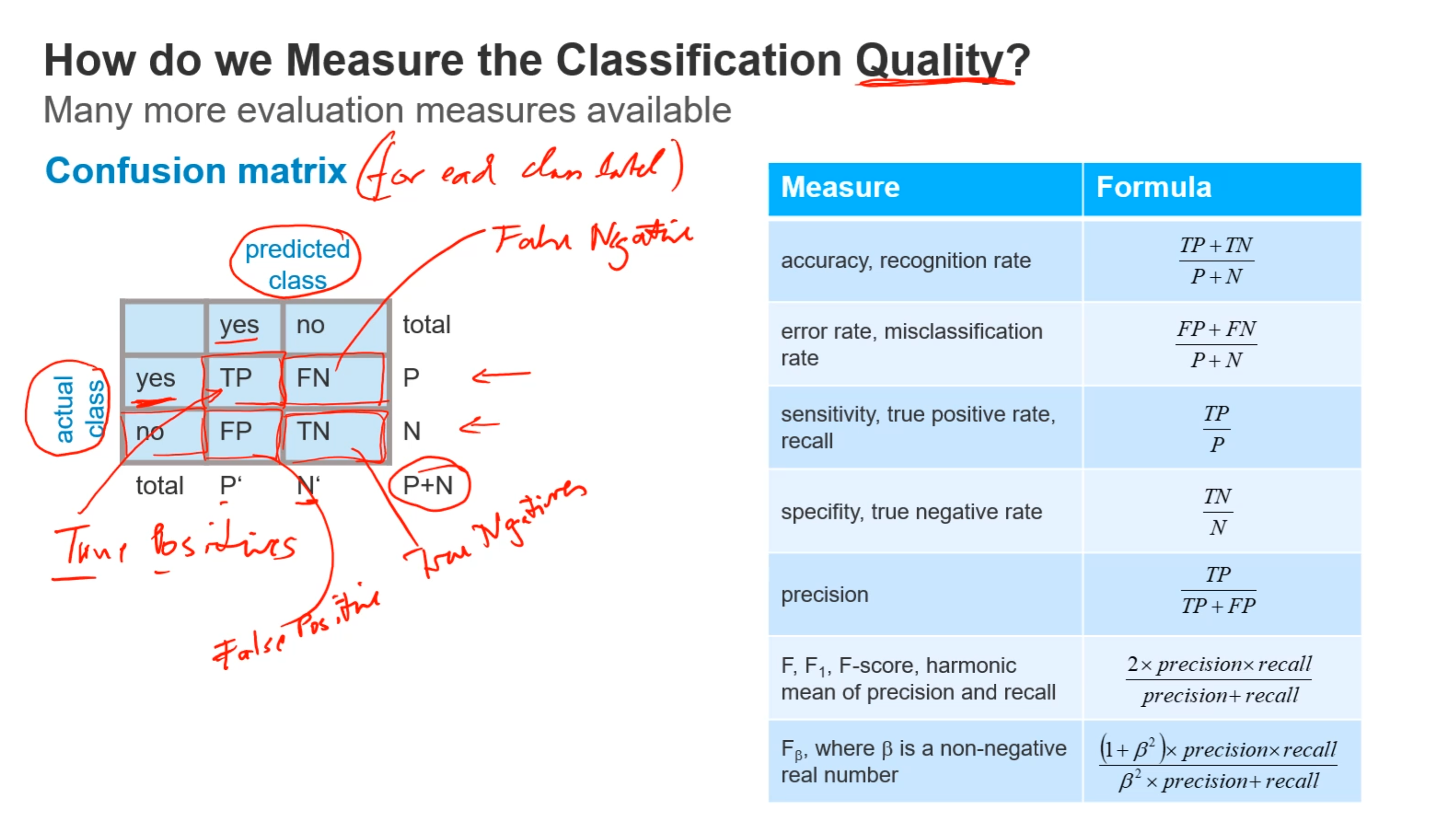
- 如何测试分类的质量:
- 其他分类方法:
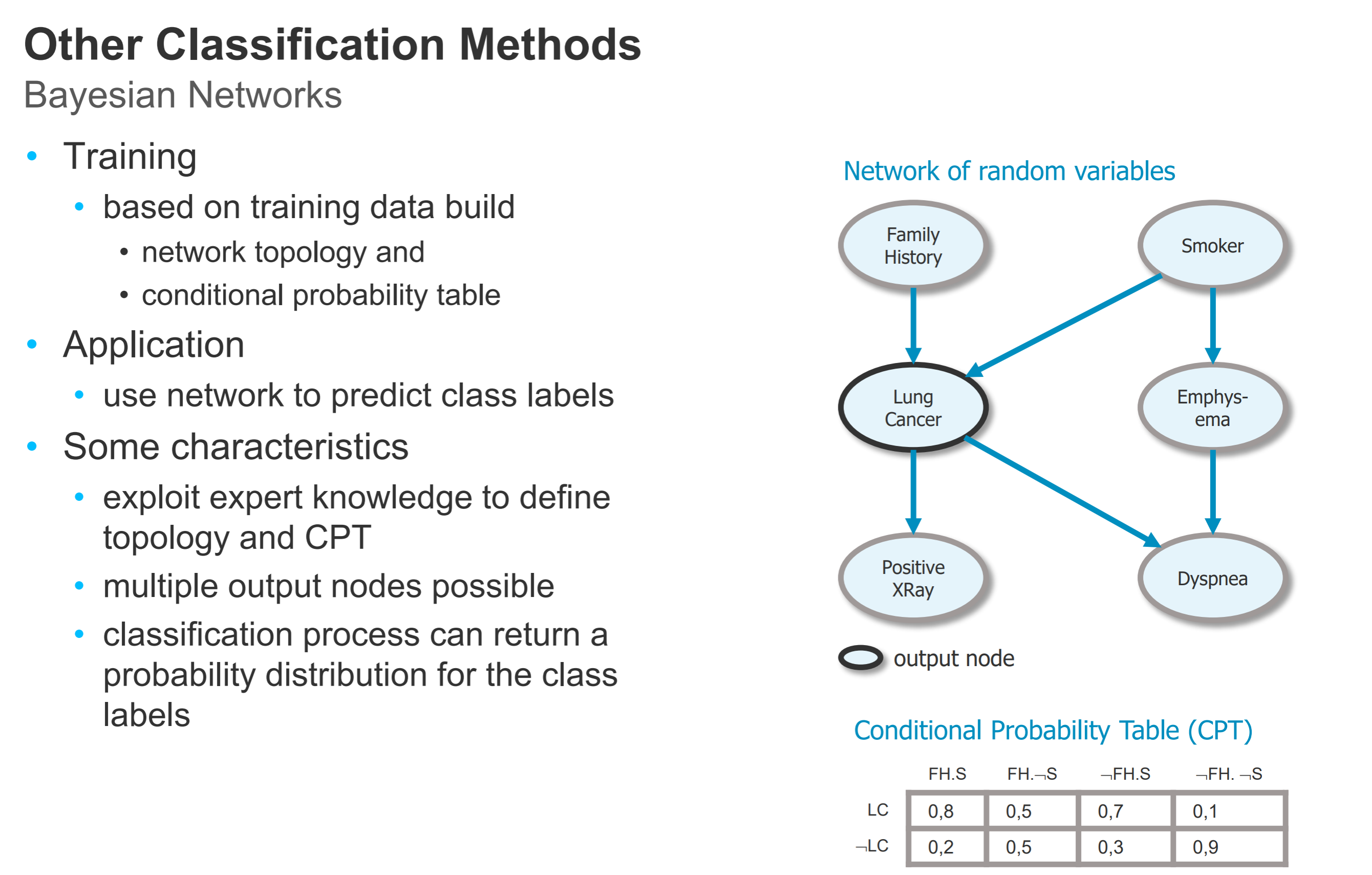
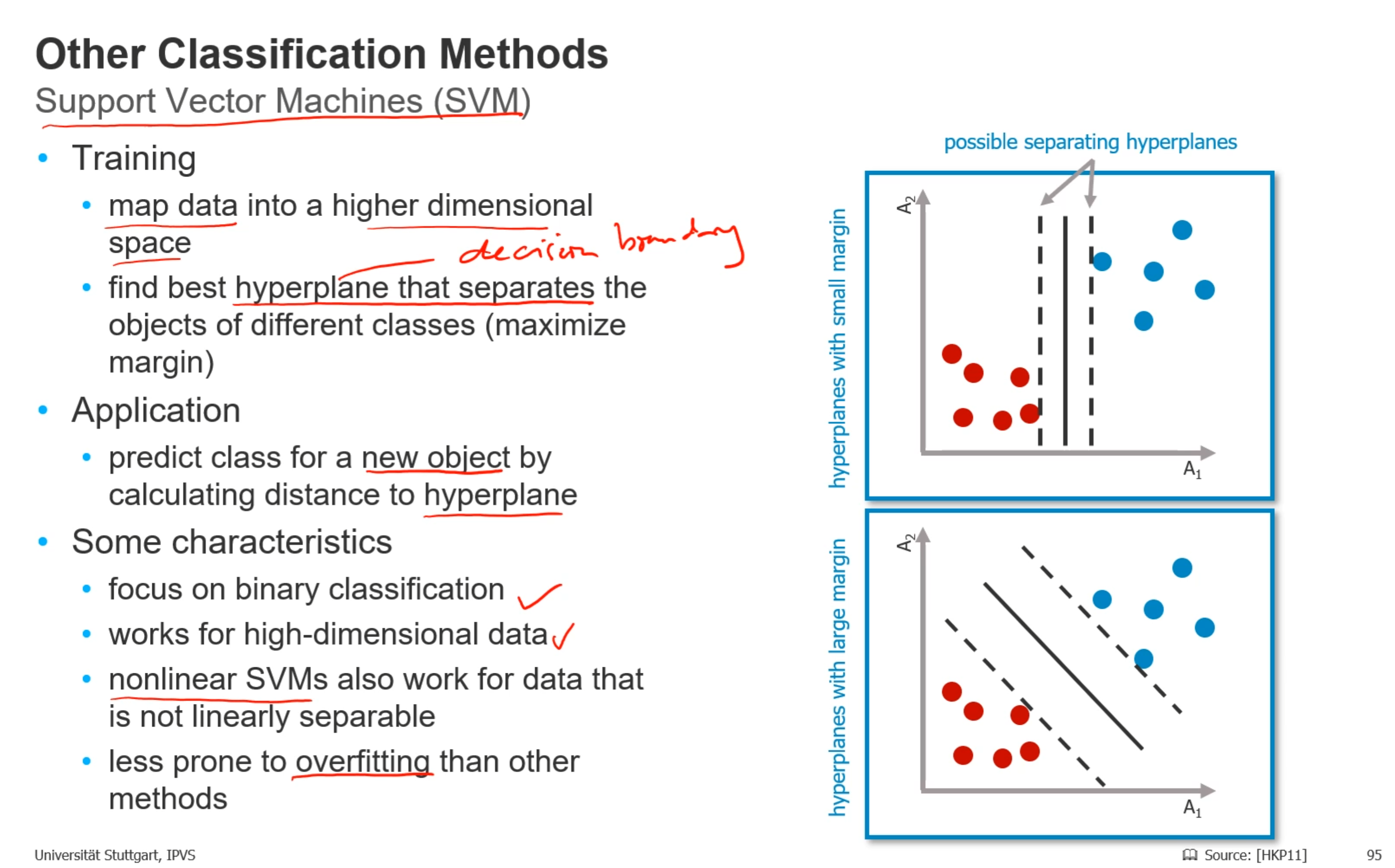
- 其他分类方法:
- Regression:

- 线性回归
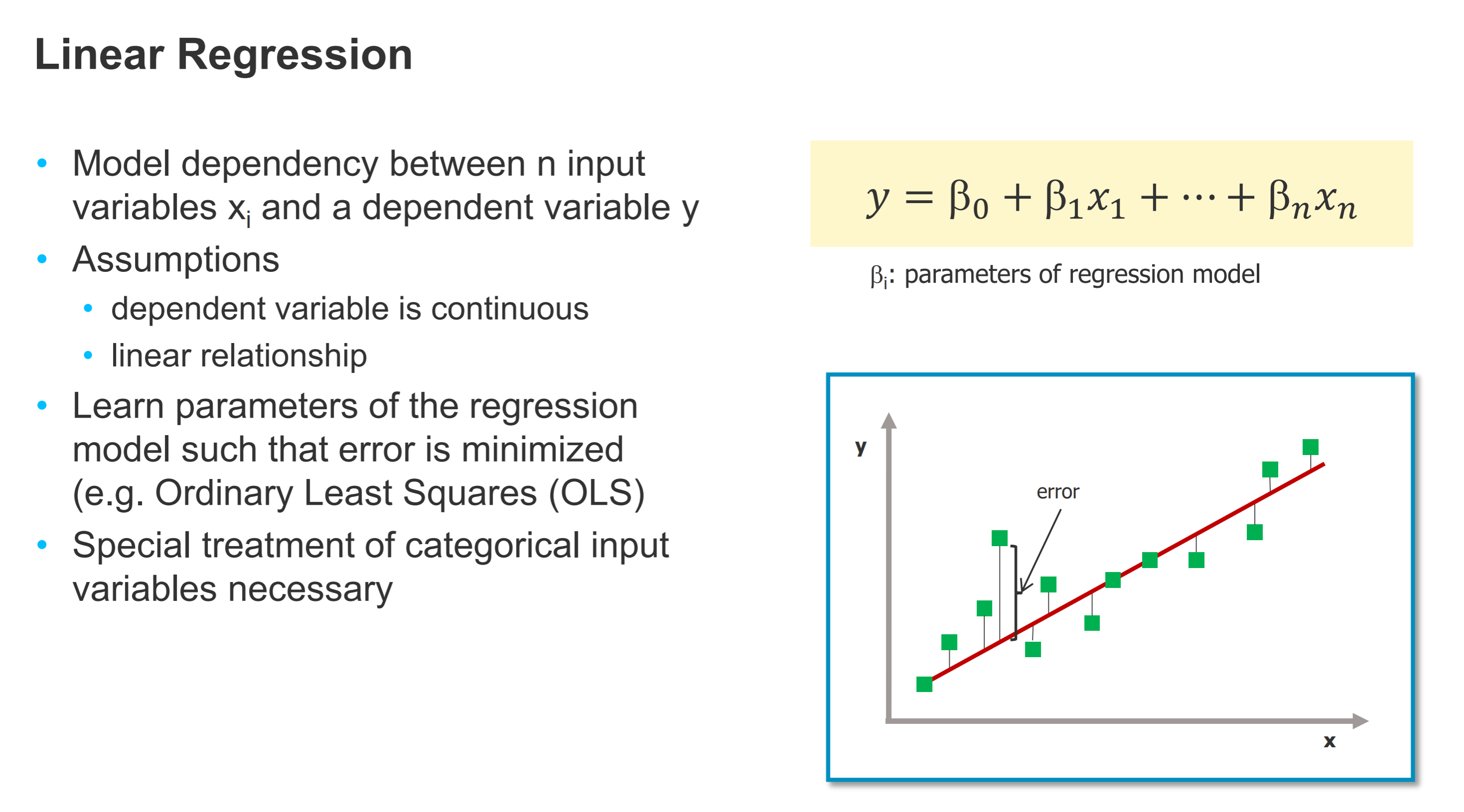
- 线性回归
- 例子:
- 算法:第3,4块是用来判断结束递归,attribute list是分类的依据字段,每次都选择最佳分类字段
# Data mining systems
- 数据分析是基于之前建立起来的数据模型
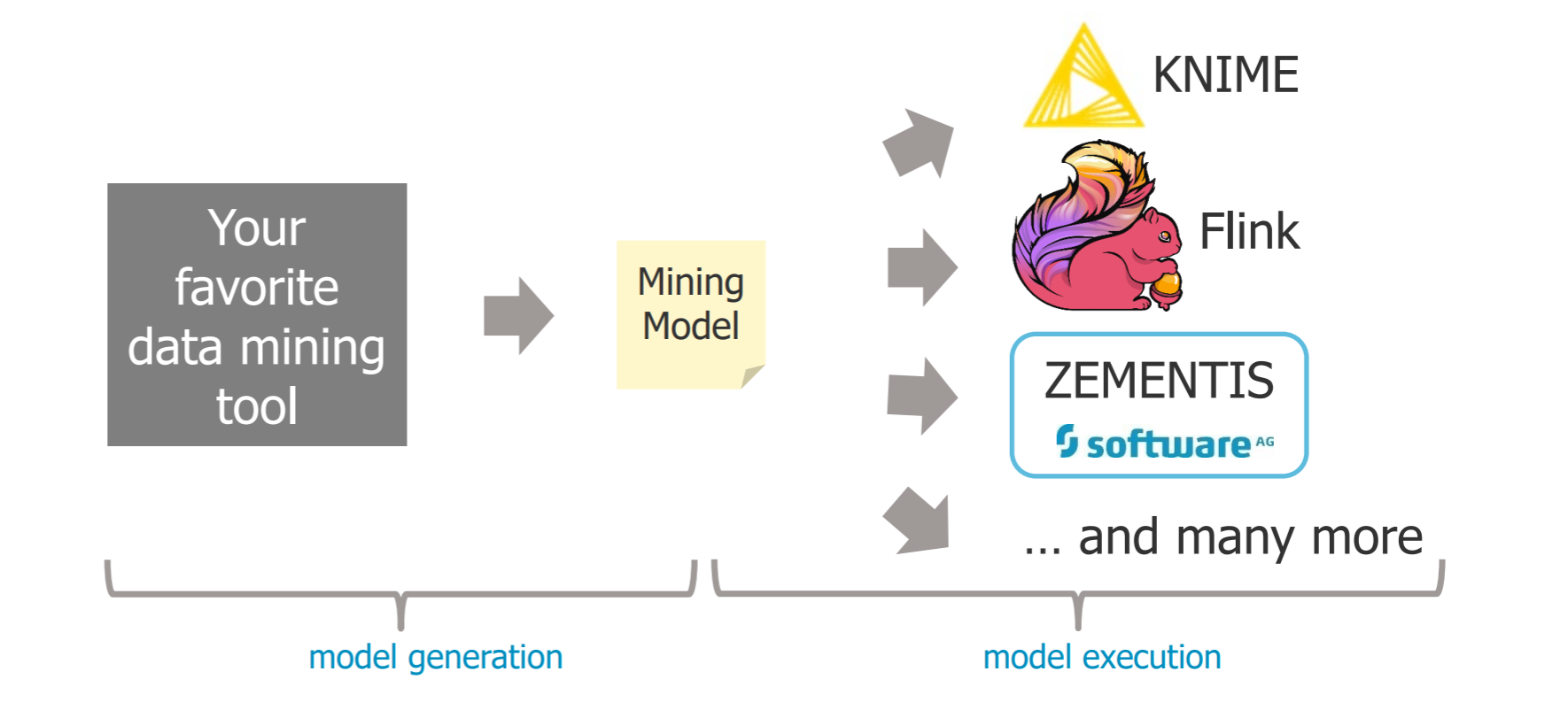
- pmml

- 先产生model,再测试这个model的好坏,再应用在实际数据中