
Ch18_DataStream
# Flink DataStream 算子 Map、FlatMap、Filter、KeyBy、Reduce、Fold、Aggregate
https://blog.csdn.net/wangpei1949/article/details/101625394
streamSource.flatMap(new TweetParser())//encapsulate the string to the tweet object
.map(new TweetKeyValue())//map to key-value
.keyBy(new KeySelector<Tuple2<Tweet, Integer>, String>() {
public String getKey(Tuple2<Tweet, Integer> tweetIntegerTuple2) throws Exception {
return tweetIntegerTuple2.f0.hashtagStr;//use hashtag to classify
}
})
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))//5 seconds one analyze
.sum(1)
.print();
// execute program
env.execute("Flink Streaming Java API Skeleton");
2
3
4
5
6
7
8
9
10
11
12
13
# 1. Map [DataStream->DataStream]
一对一的操作,把String转换成int输出:
DataStream<Integer> resultStream = inputSource.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String s) throws Exception {
return s.length();//输出数据的长度
}
});
2
3
4
5
6
# 2.FlatMap [DataStream->DataStream]
一行变零到多行。如下,将一个句子(一行)分割成多个单词(多行)。可以改变数据类型
DataStream<String> resultStream = inputSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] res = s.split(" ");
for(String r:res){
collector.collect(r);//以空格为分割把数据打散
}
}
});
2
3
4
5
6
7
8
9
10
# 3. Filter [DataStream->DataStream]
过滤出需要的数据(不改变数据类型)
返回值为false则过滤掉,true为通过
DataStream<String> resultStream = inputSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return s.startsWith("h");
}
});//只输出开头为h的字符串
2
3
4
5
6
# 4. KeyBy [DataStream->KeyedStream]
https://zhuanlan.zhihu.com/p/99695563?from_voters_page=true
rebalance操作轮询
要先对数据进行分组之后才可以聚合
按指定的Key对数据重分区。将同一Key的数据放到同一个分区,基于hashcode计算。
注意:
分区结果和KeyBy下游算子的并行度强相关。如下游算子只有一个并行度,不管怎么分,都会分到一起。
对于POJO类型(javaBean,只有getter,setter方法),KeyBy可以通过keyBy(fieldName)指定字段进行分区。
对于Tuple类型,KeyBy可以通过keyBy(fieldPosition)指定字段进行分区。
对于一般类型,如上, KeyBy可以通过keyBy(new KeySelector {...})指定字段进行分区。

通过ID进行分组,第一个泛型(SensorReading为传进来的数据类型),第二个泛型(Tuple)为返回对数据类型,是key的数据类型。
由于keyBy的参数可以传多个值,且都为属性名(使用getter方法获取,所以一定要定义getter方法),所以类型为Tuple(一个可以存放不同数据类型的容器)
也可以通过java8新特性方法引用来规定按照返回值进行分组:
也可以自定义方法:

# 5.Aggregate [KeyedStream->DataStream]
Aggregate 对KeyedStream按指定字段滚动聚合并输出每一次滚动聚合后的结果。默认的聚合函数有:sum、min、minBy、max、mabBy。
注意:
max(field)与maxBy(field)的区别: maxBy返回field最大的那条数据;而max则是将最大的field的值赋值给第一条数据并返回第一条数据。同理,min与minBy。
Aggregate聚合算子会滚动输出每一次聚合后的结果。
# 6. Reduce [KeyedStream->DataStream]
Reduce: 基于ReduceFunction进行滚动聚合,并向下游算子输出每次滚动聚合后的结果。数据类型不可以改变
注意: Reduce会输出每一次滚动聚合的结果。
reduce第一个参数为上次滚动聚合的结果,第二个参数为新的数据
# 多流操作
# 1. Split [DataStream->SplitStream]
根据某些特征把一个datastream拆分成多个dataStream,但是返回值是一个SplitStream。
此操作相当于把每个数据盖一个戳,再放到Stream中,一般后面跟select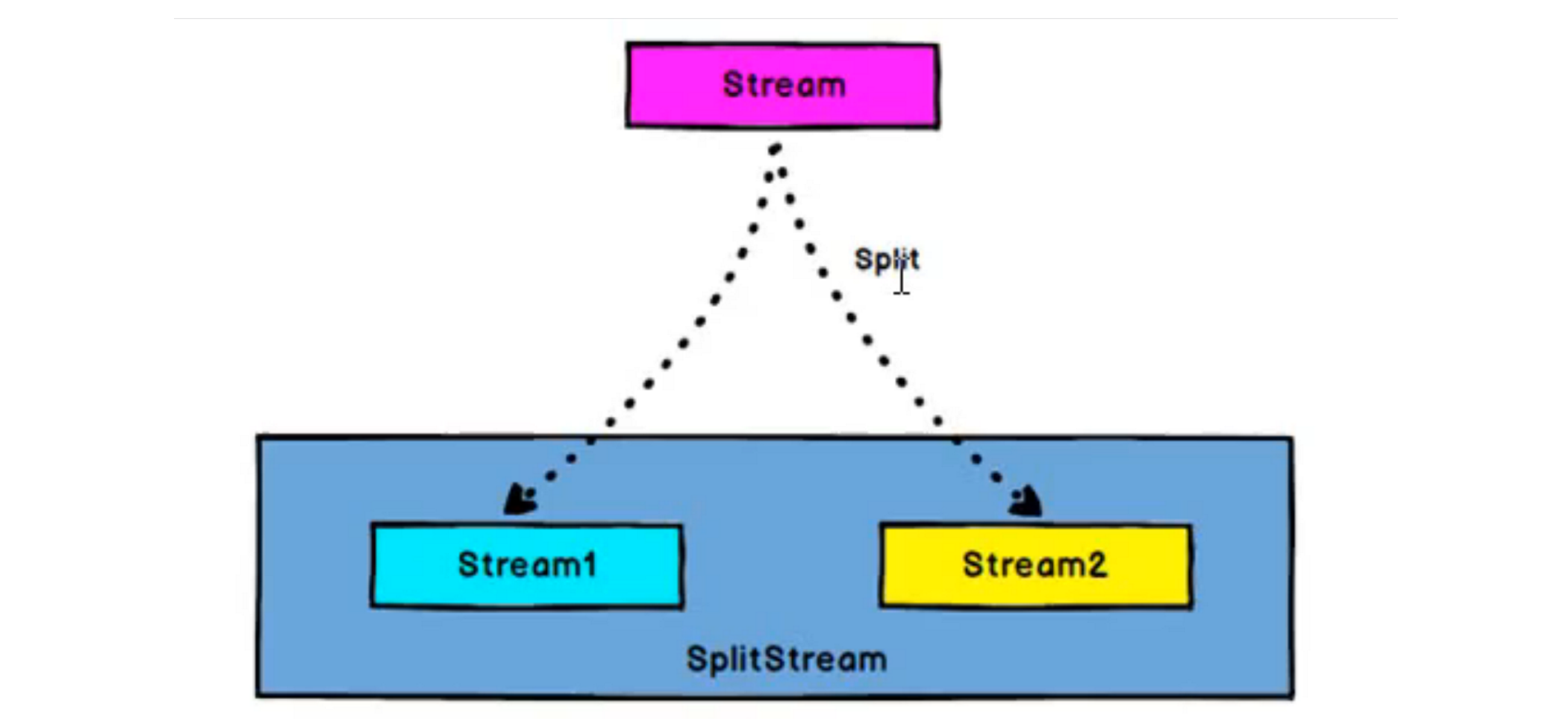

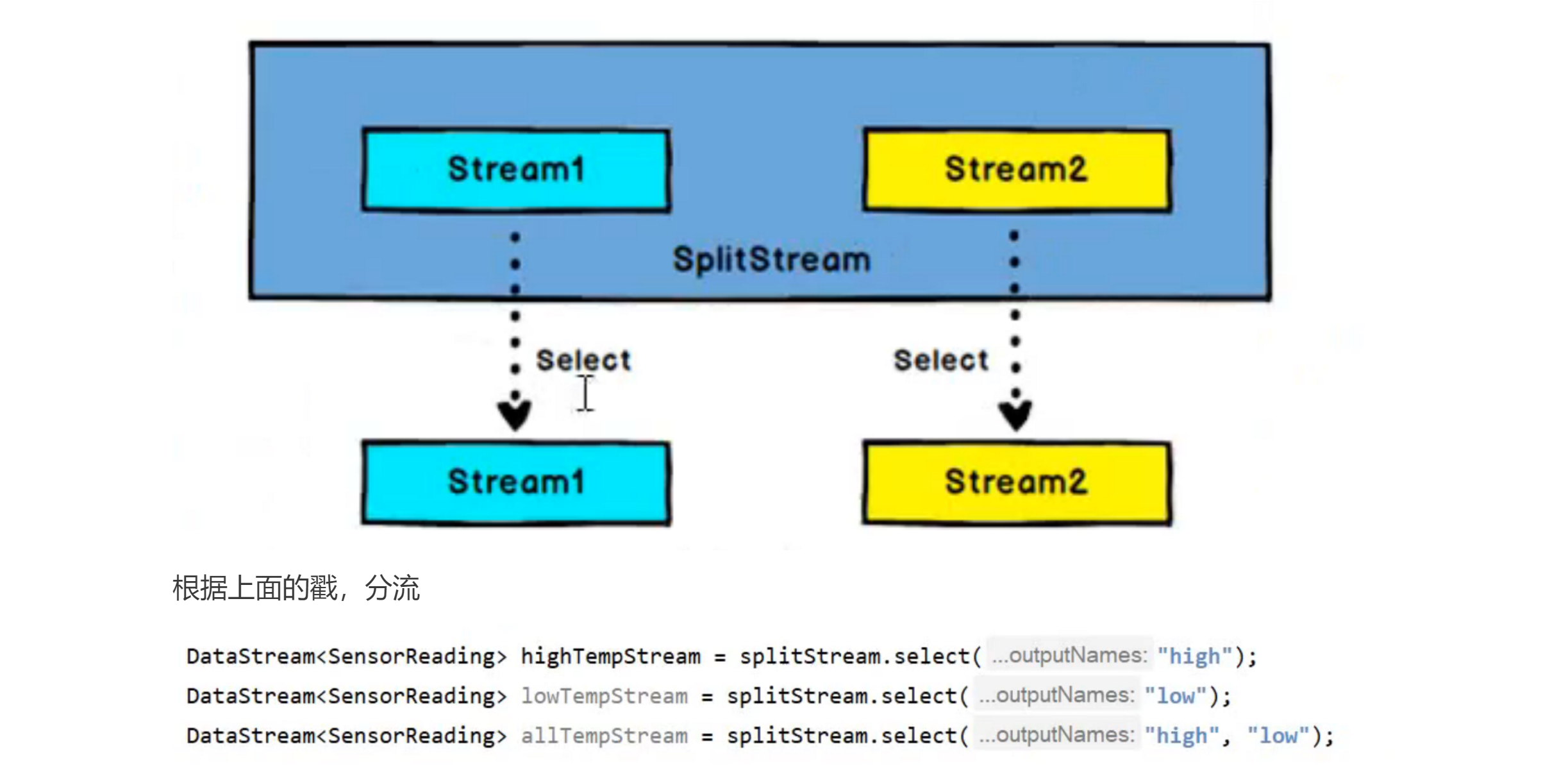
# 2.Select[SplitStream->DataStream]
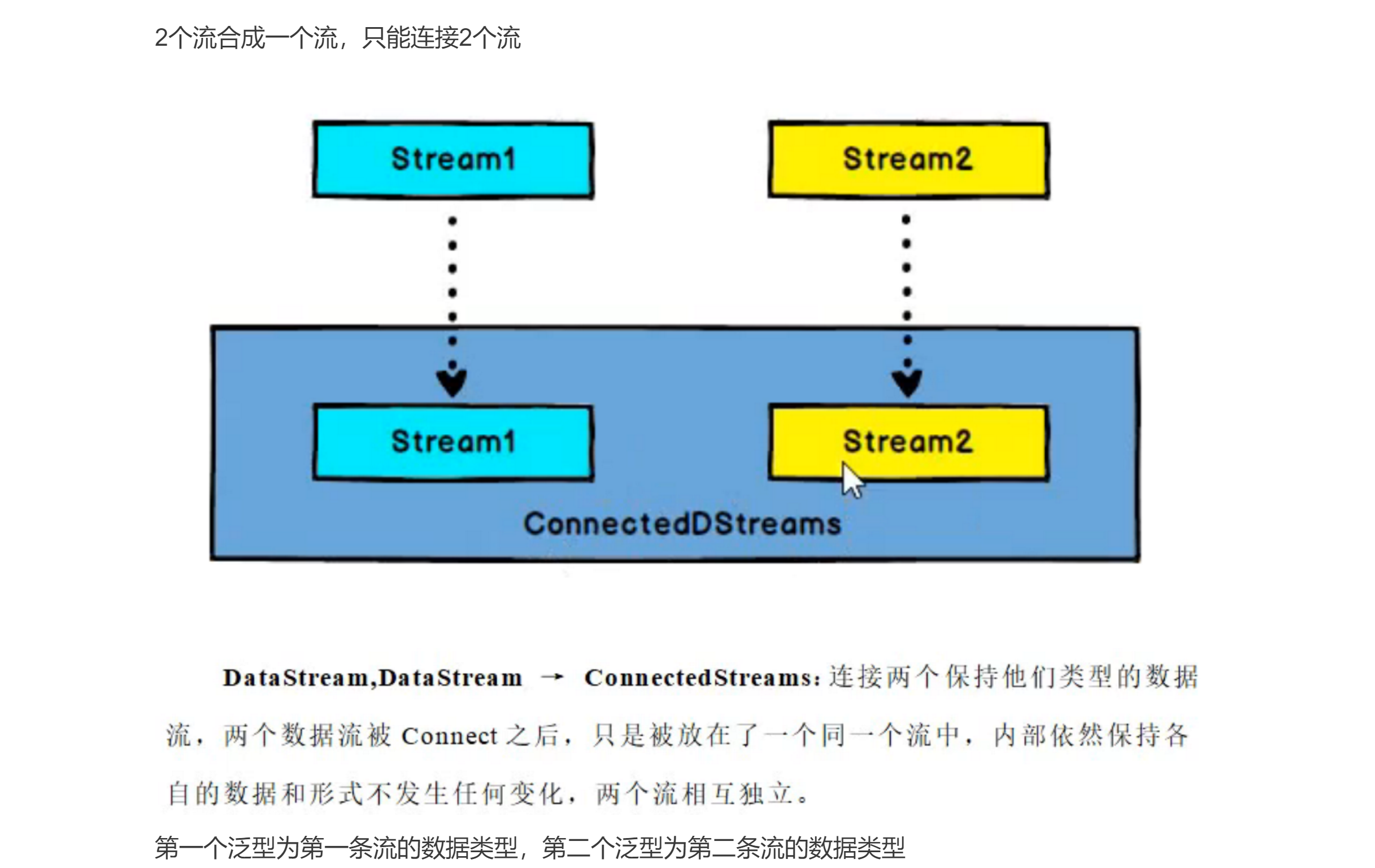
# 3.Connect[DataStream-> ConnectedStreams]

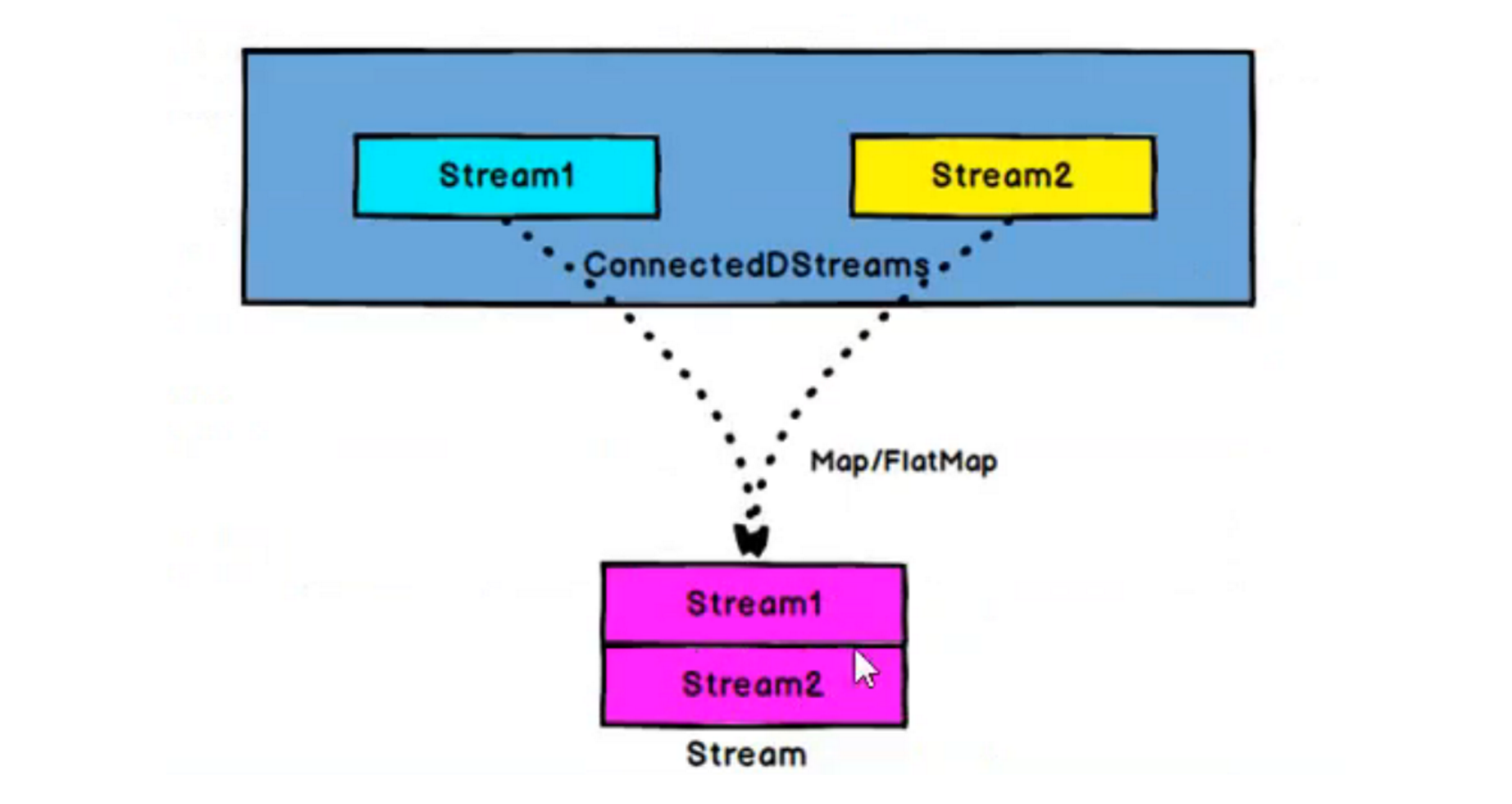
# 4. CoMap,CoFlatMap[ConnectedStreams->DataStream]

# 5. Union[DataStream -> DataStream]
