
Ch11 K8s Ops
# K8s Ops
# 无状态工作负载Deployment
# 更新

# 回滚

# 有状态工作负载StatefulSet
# 更新

- 和无状态工作负载的区别主要是有序更新和部分更新
- 例子:先partition设置为2,滚动更新了一部分之后,验证完没有问题,再设置为0,相当于灰度发布
# 回滚
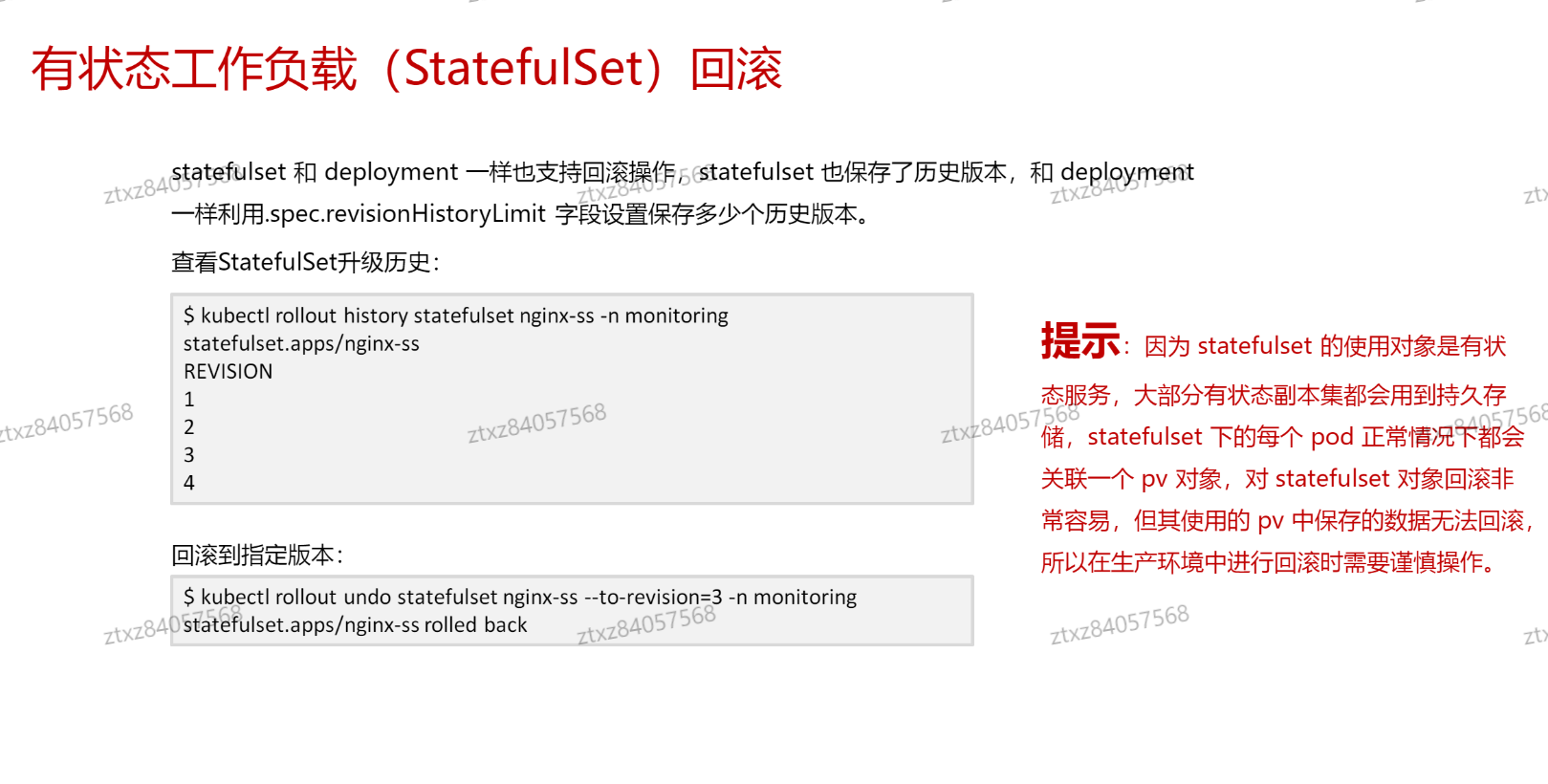
- 注意pv里的数据不会回滚
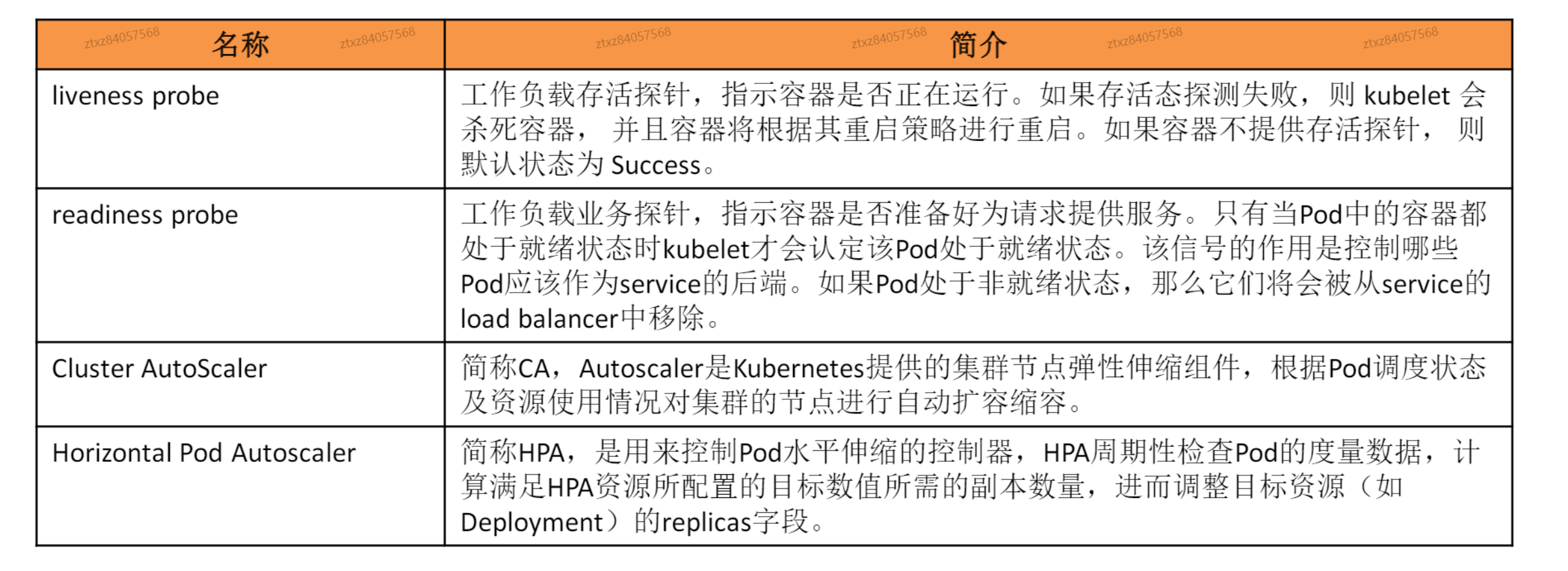
# 容器健康检查
# 探针检查机制

- 7层http探针,4层tcp socket探针

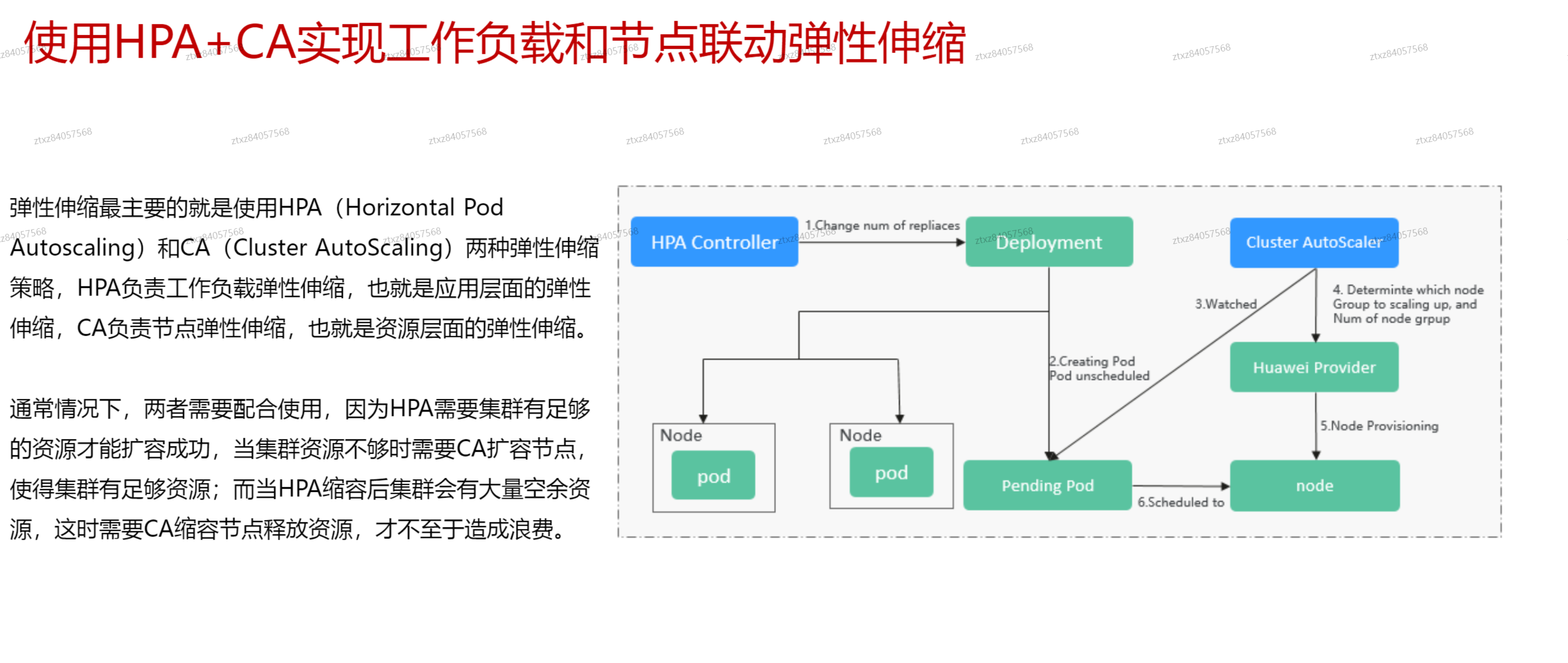
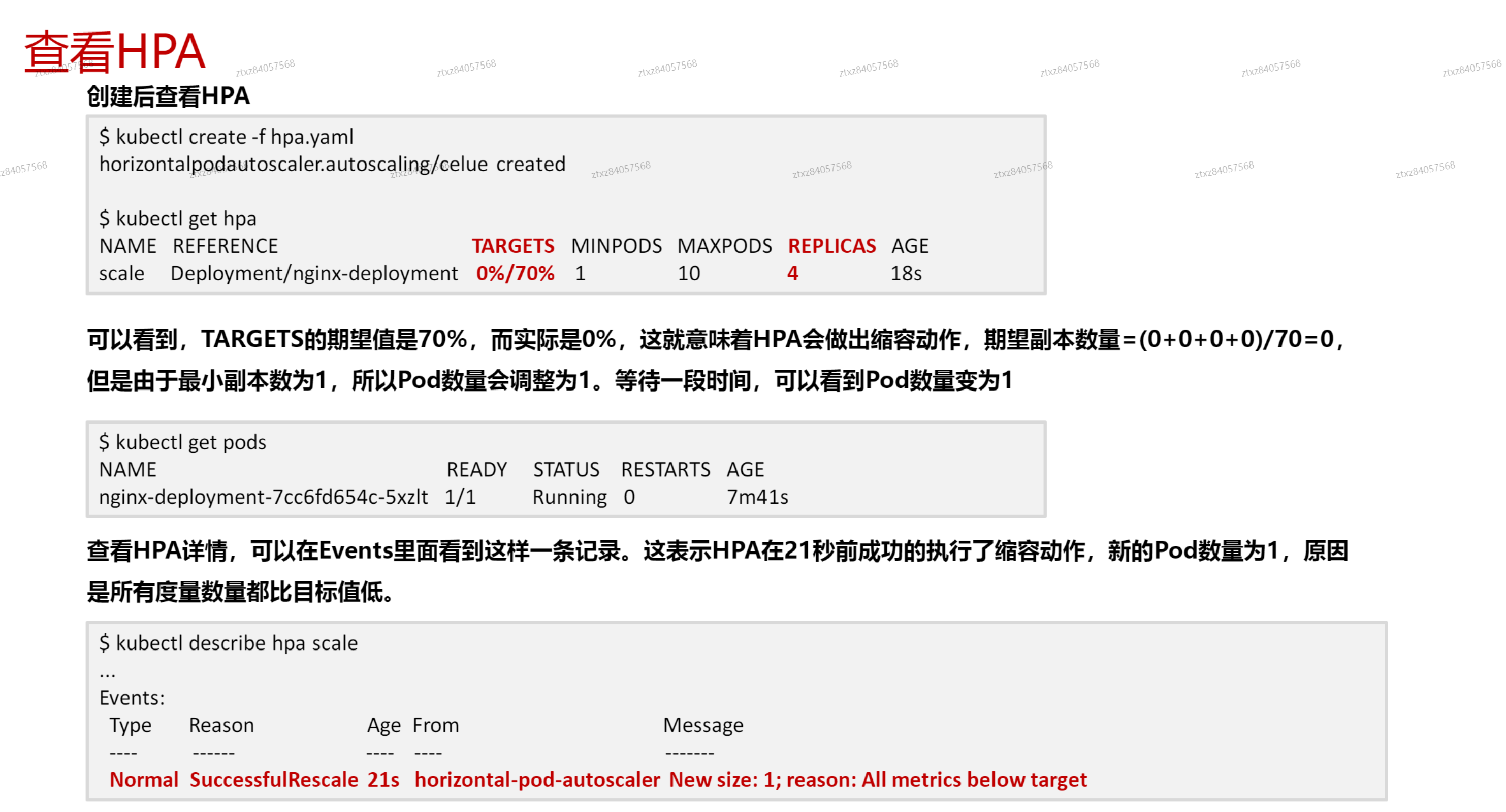
# 弹性伸缩
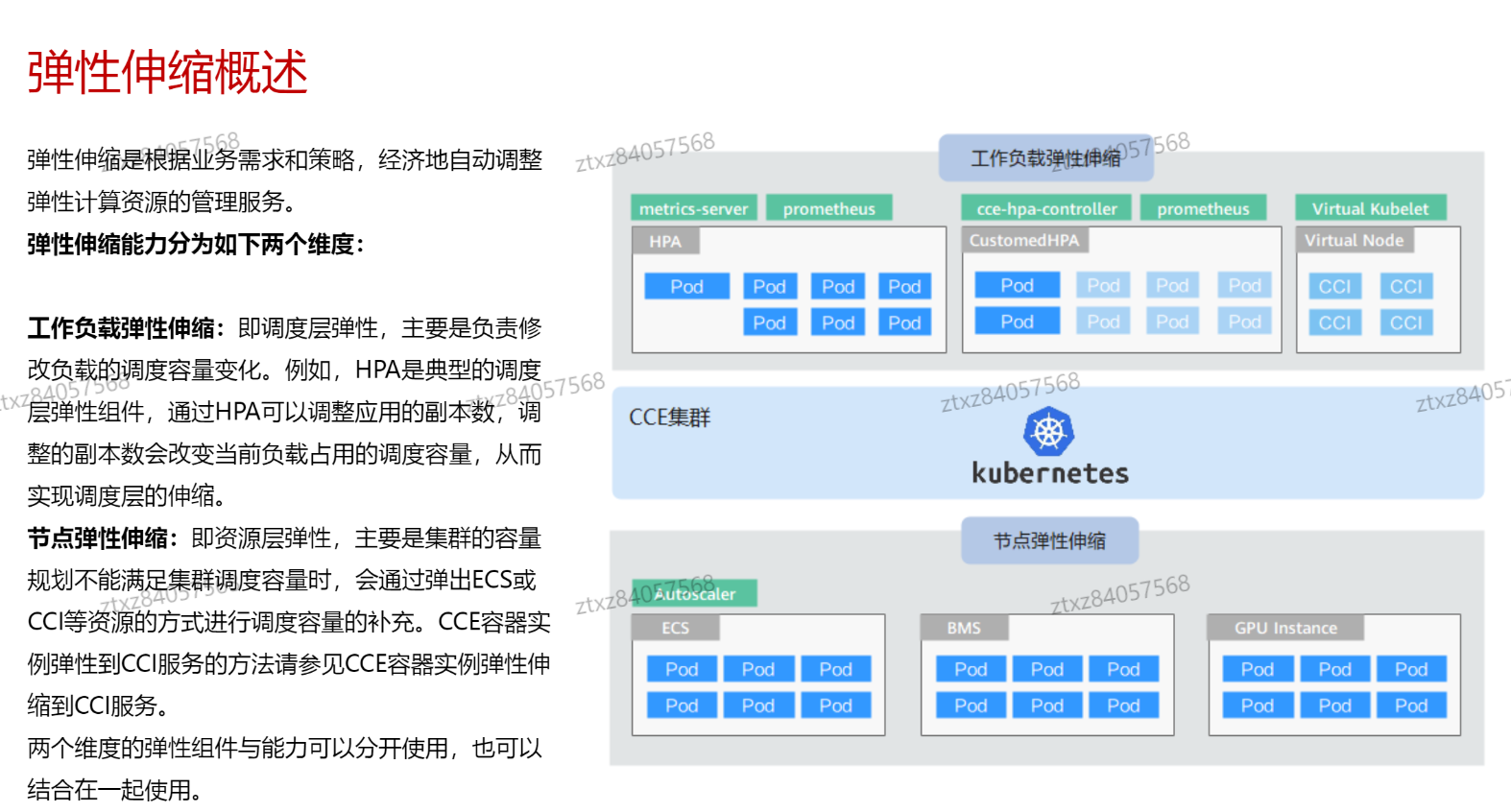
- metric server提供的是cpu和内存级别的弹性伸缩
- 普罗提供的是自定义指标的弹性伸缩
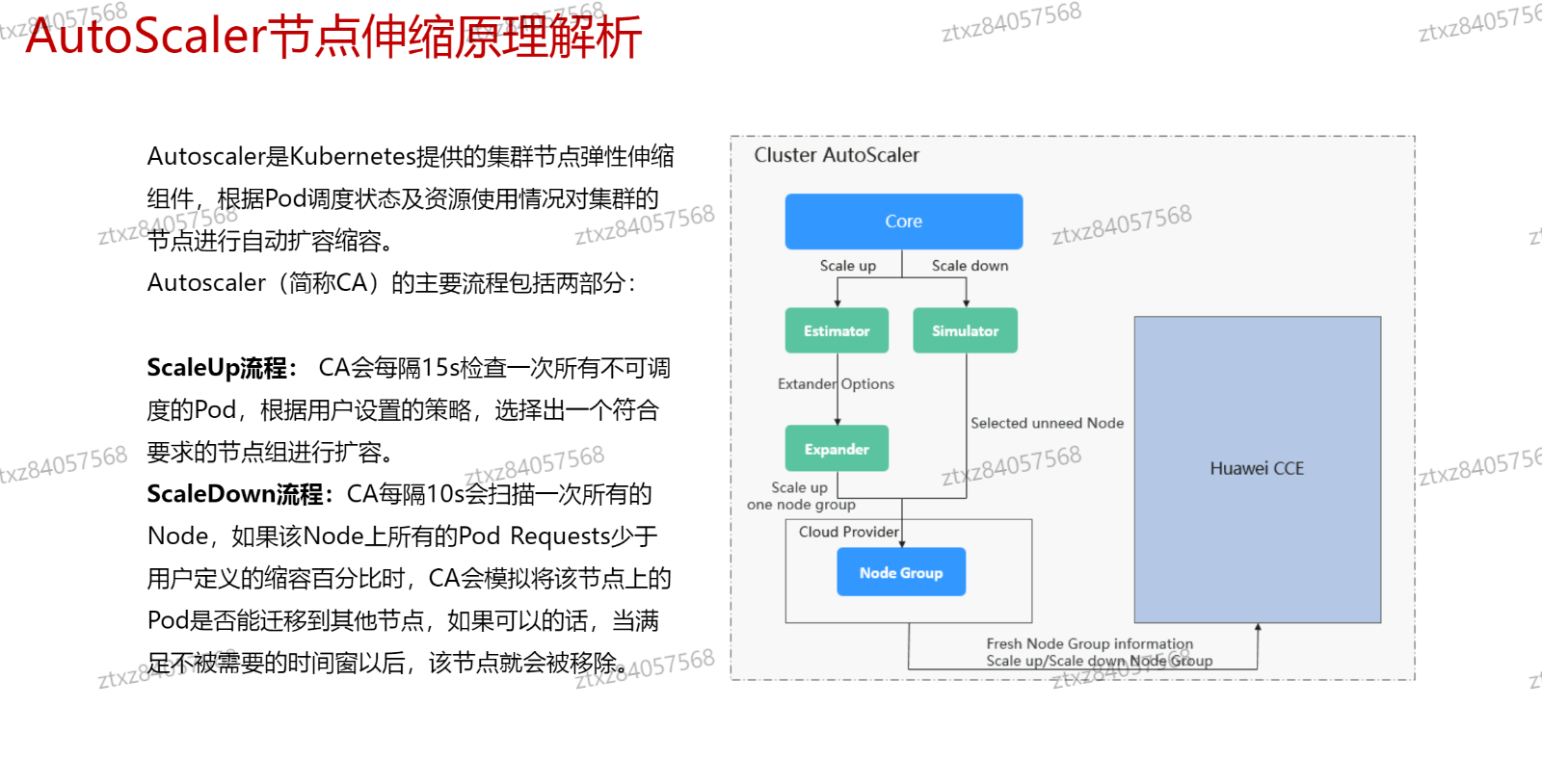
# 节点伸缩原理AutoScaler
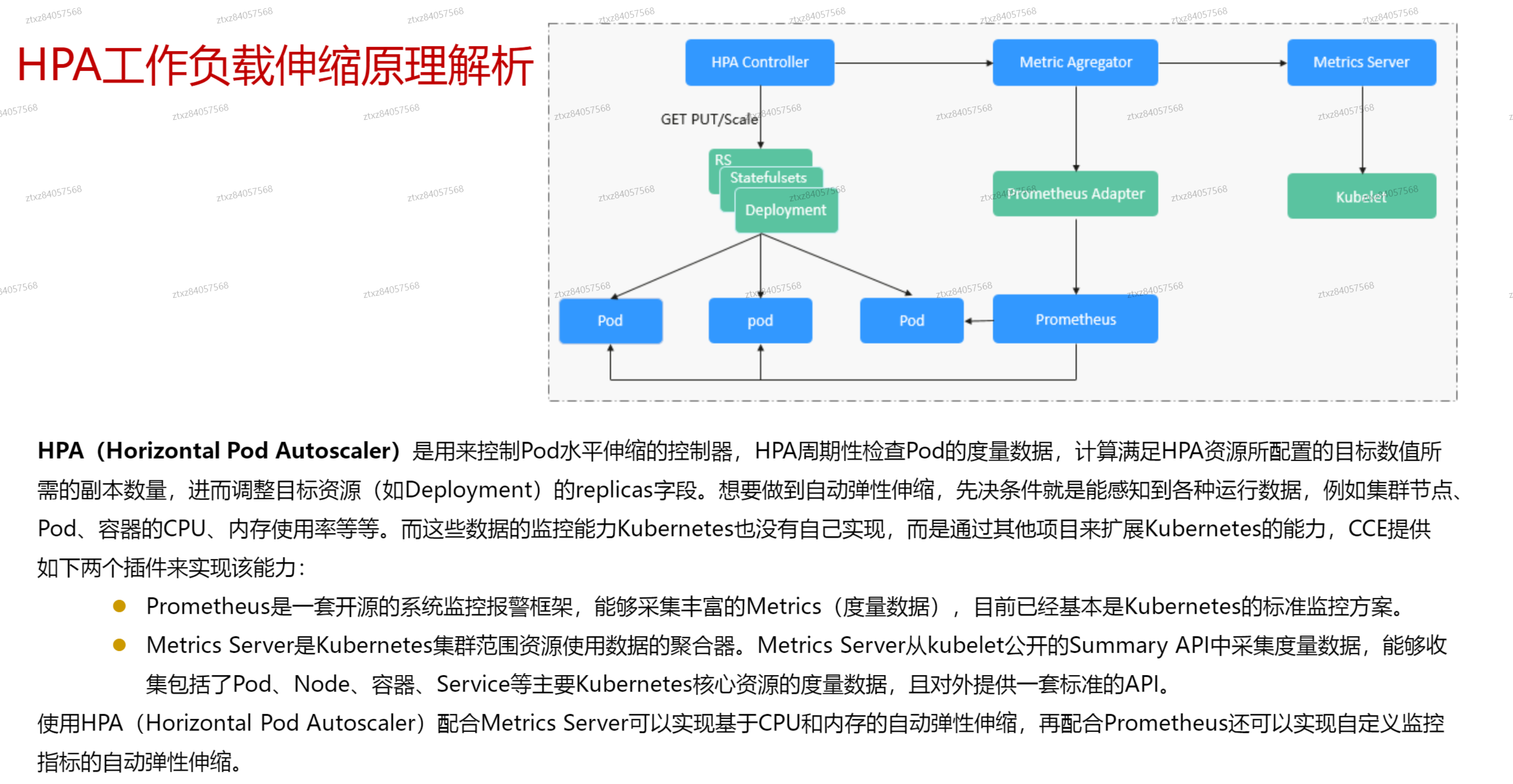
# 工作负载伸缩原理HPA

# 上半节总结
# 云原生应用特点

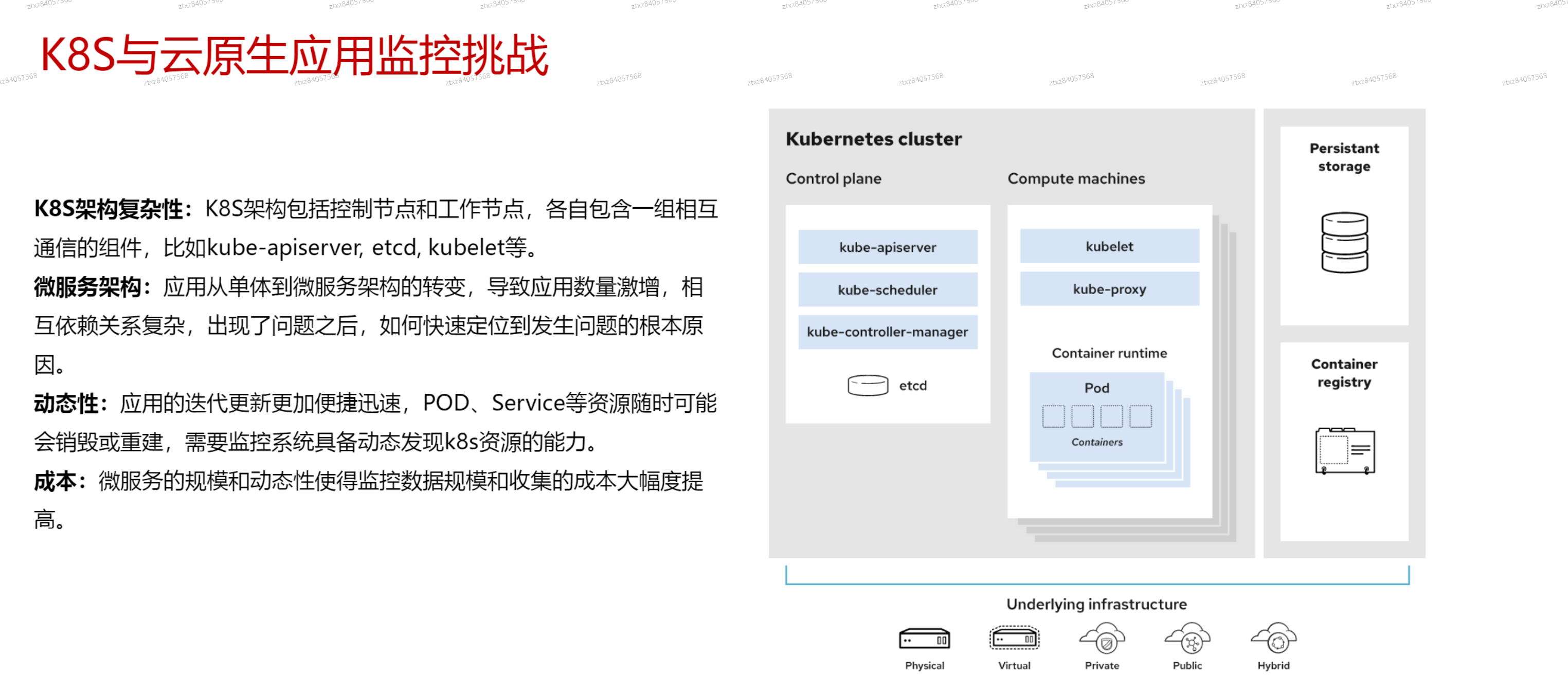
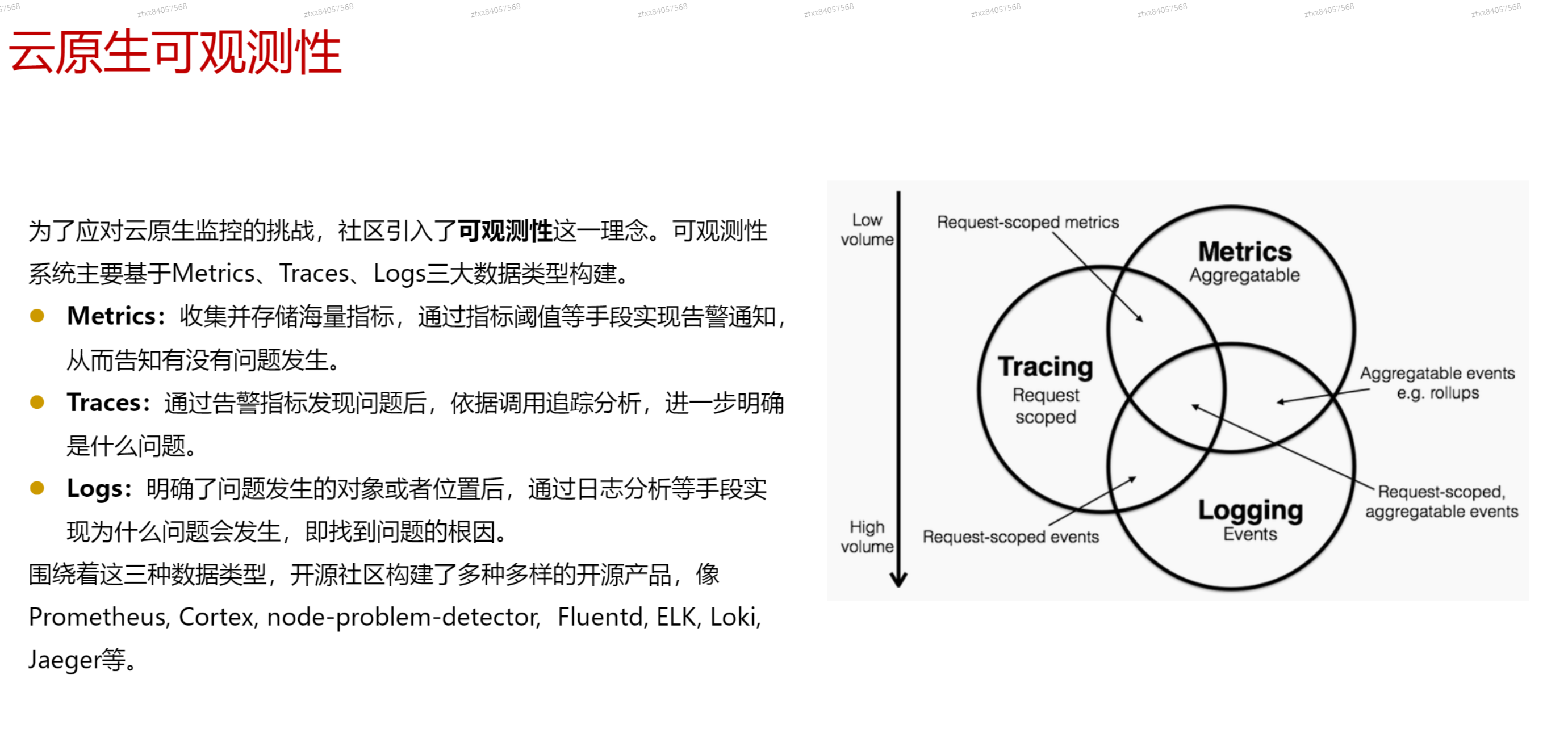
# 云原生的可观测性
# Prometheus架构


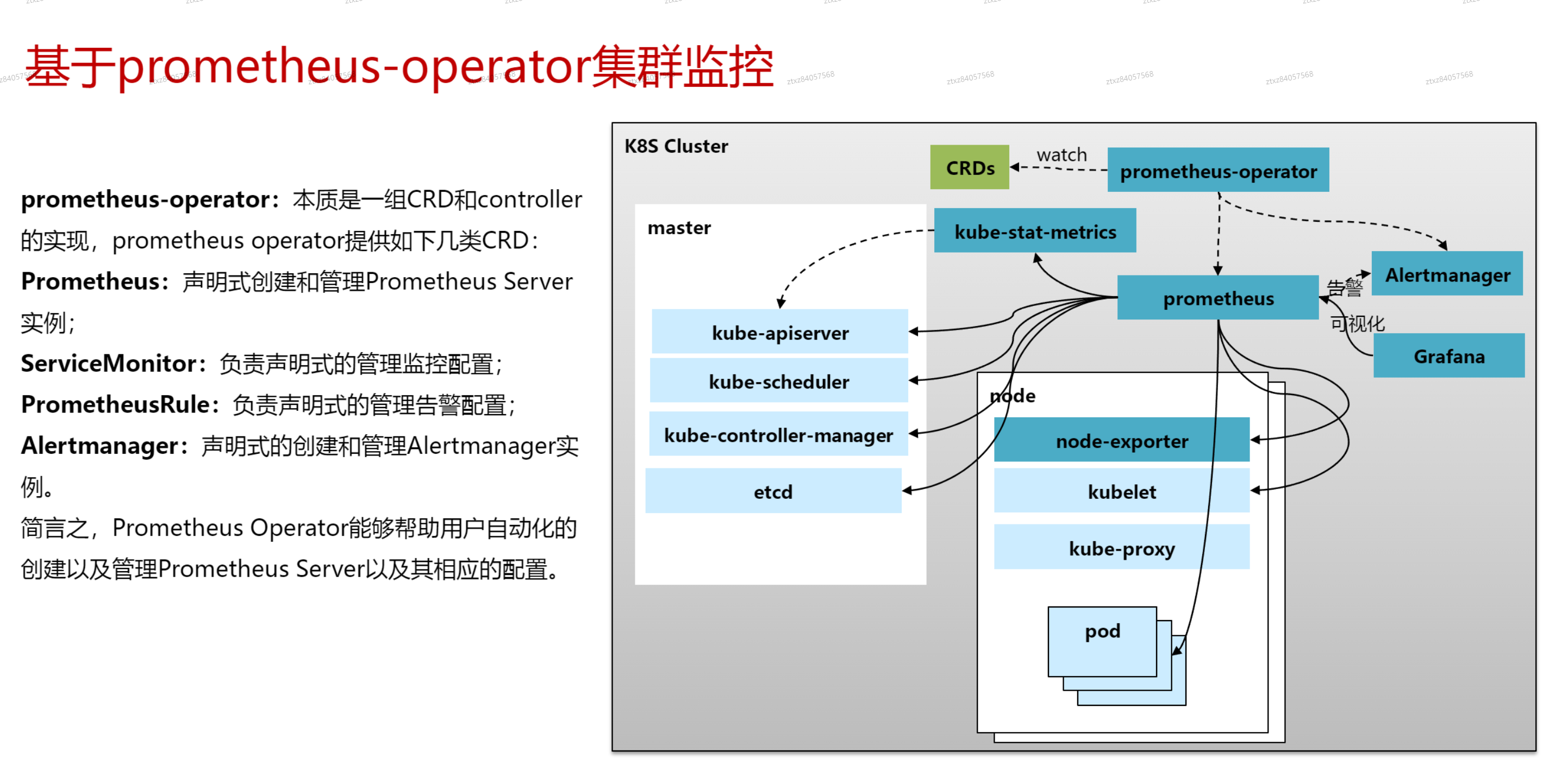
# Prometheus-operator
# K8s集群监控指标解析

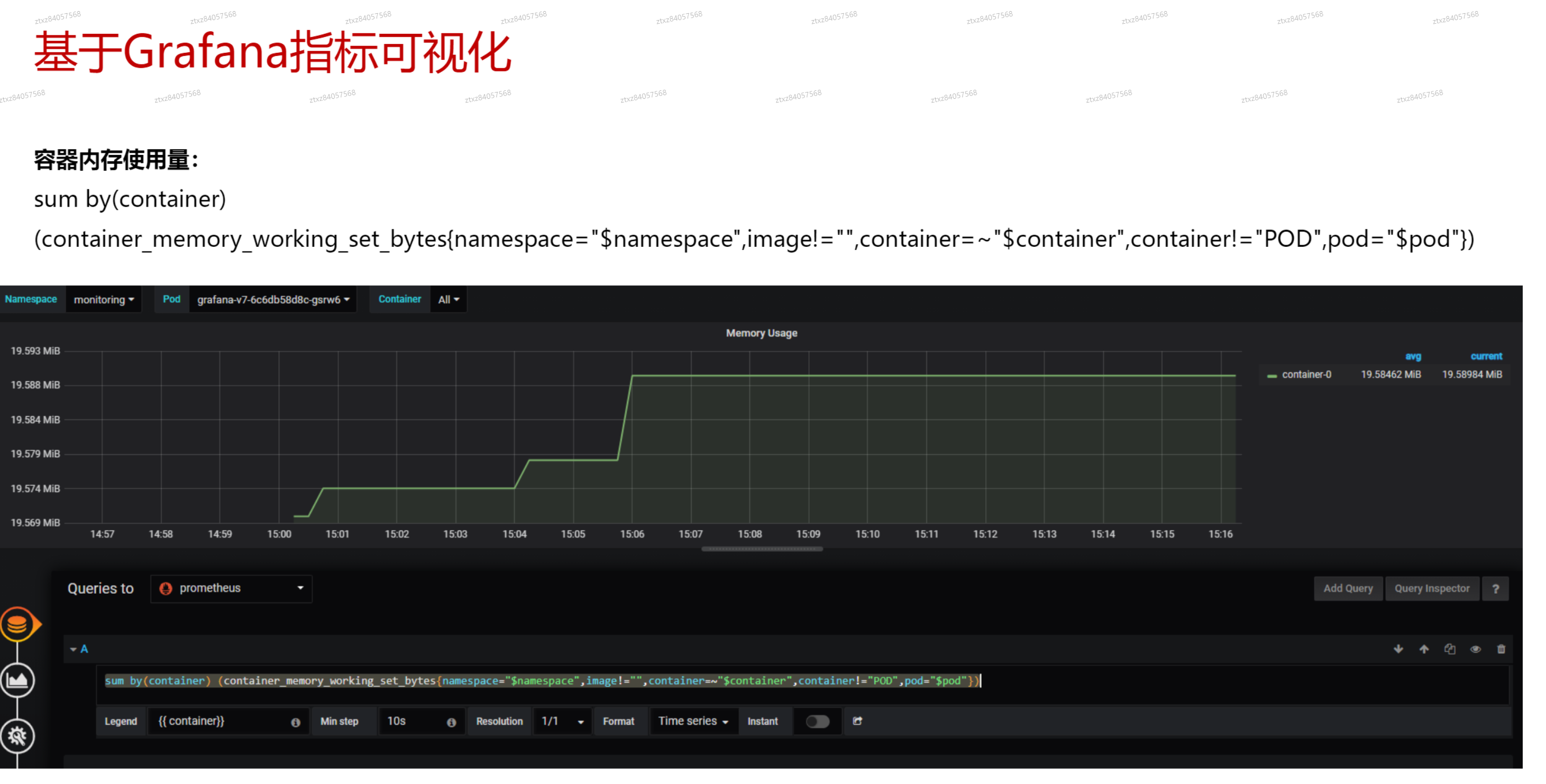
# Grafana可视化
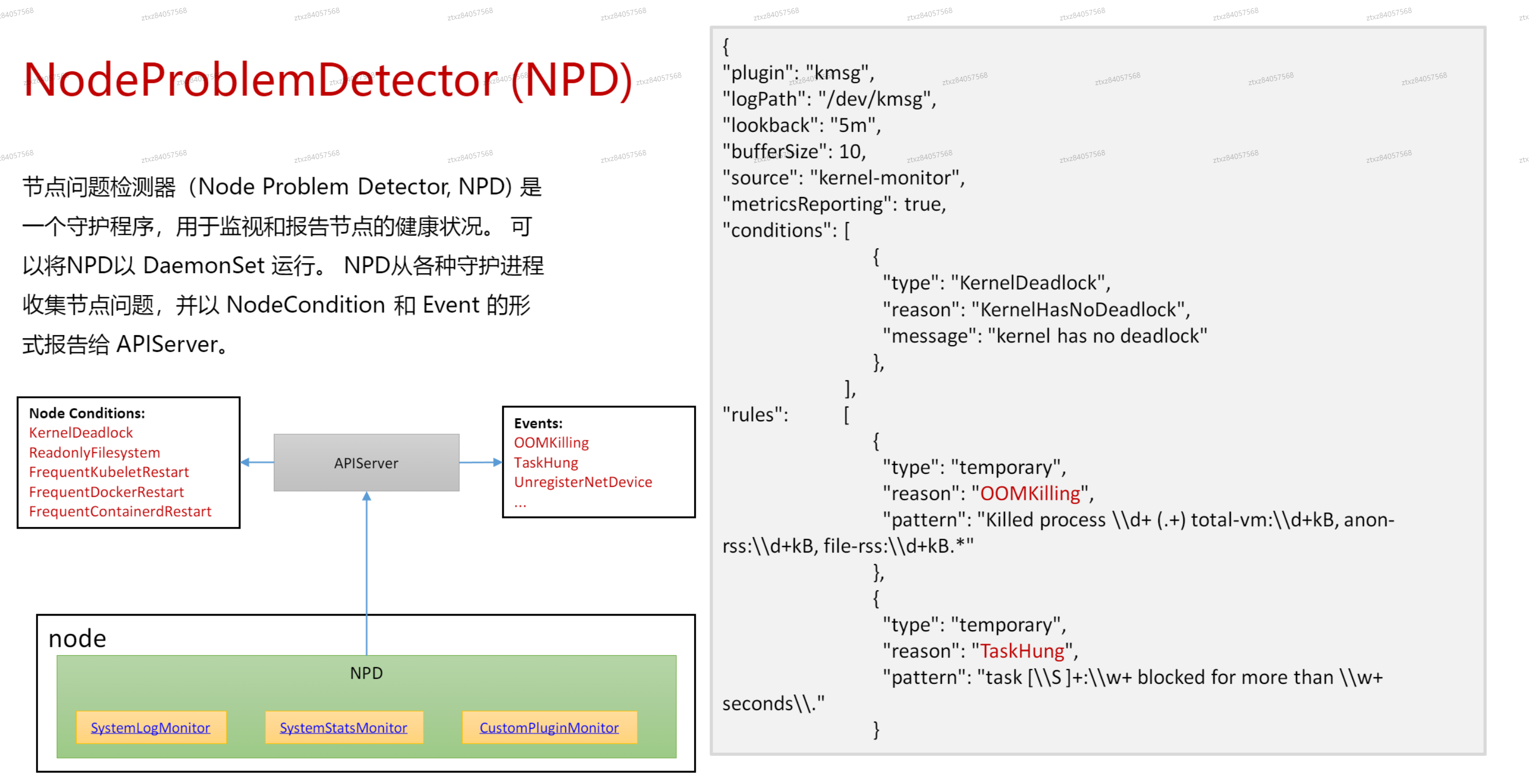
# NodeProblemDetector(NPD)
- 是一个守护进程
- 上报方式,一种是通过event,另一种是修改node节点的状态
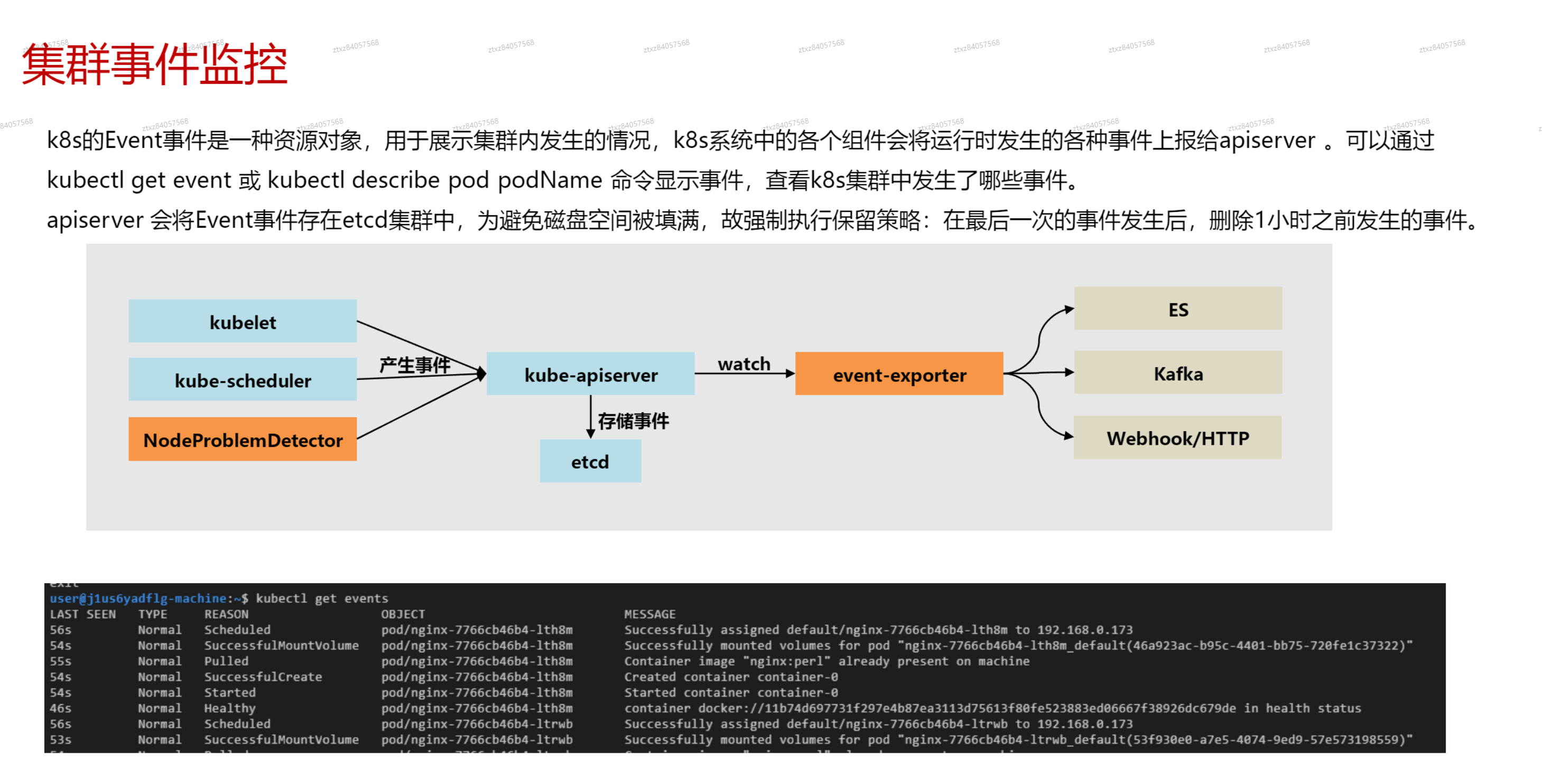
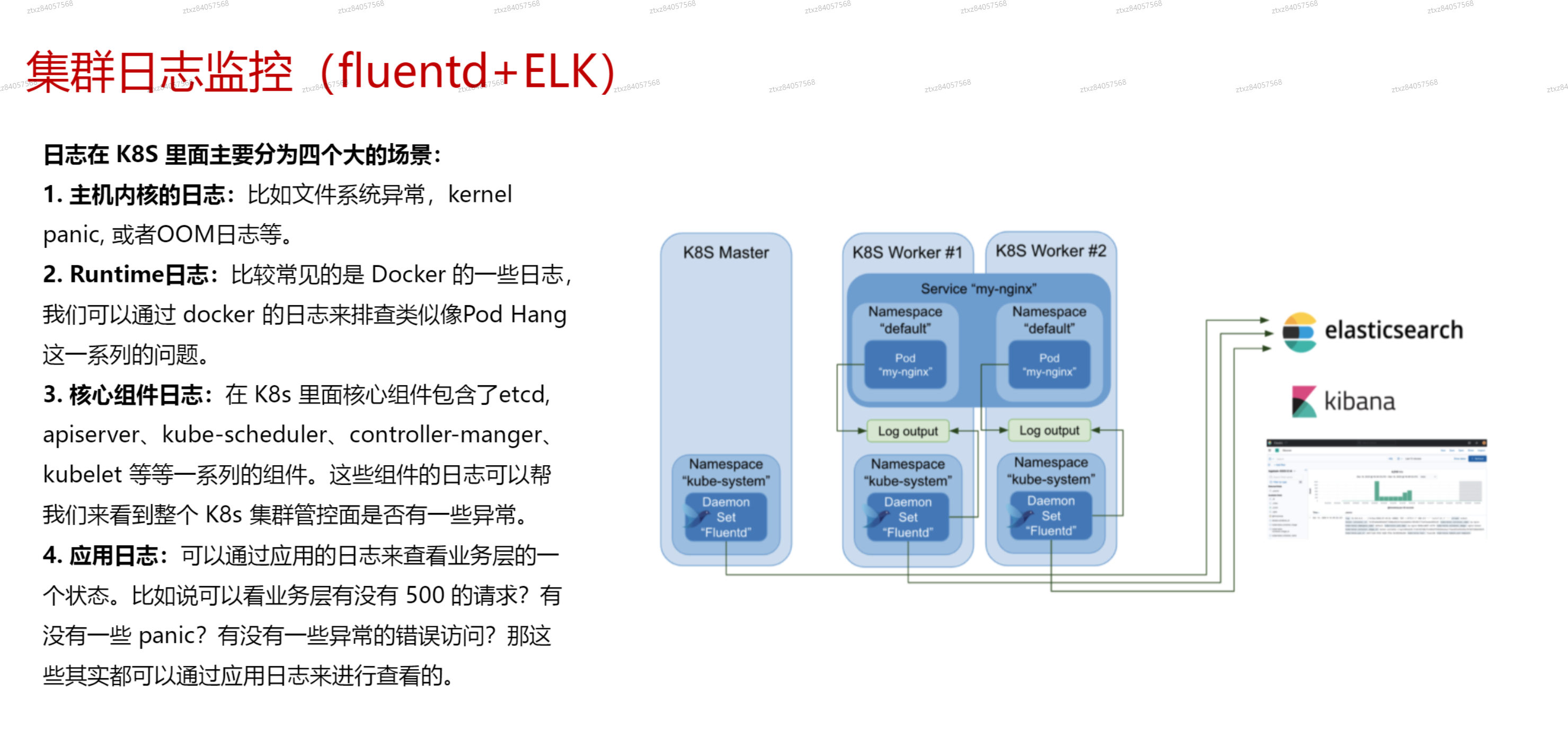
# 集群日志监控
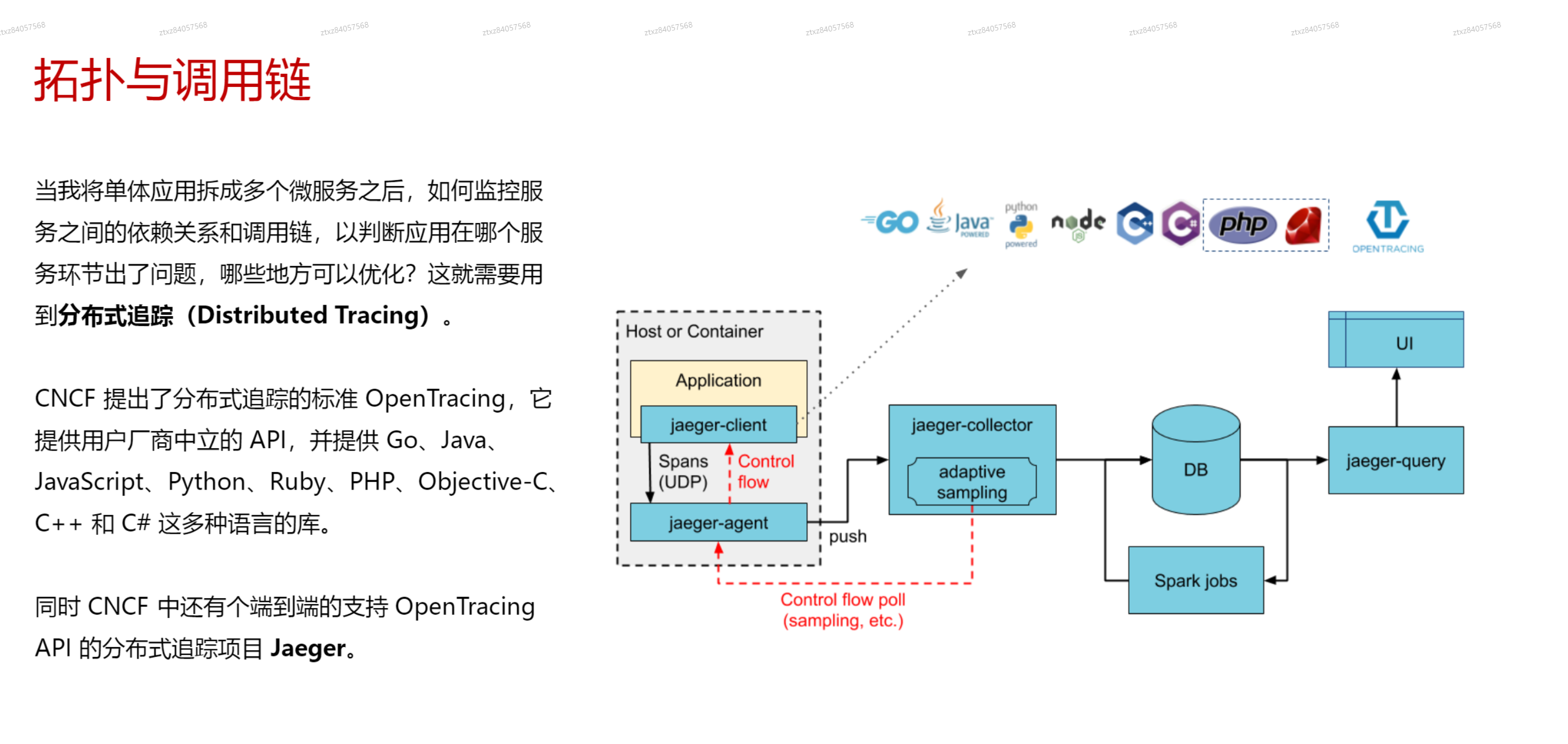
# 拓扑与日志调用链Jaeger
.png)
# 常见集群排错故障

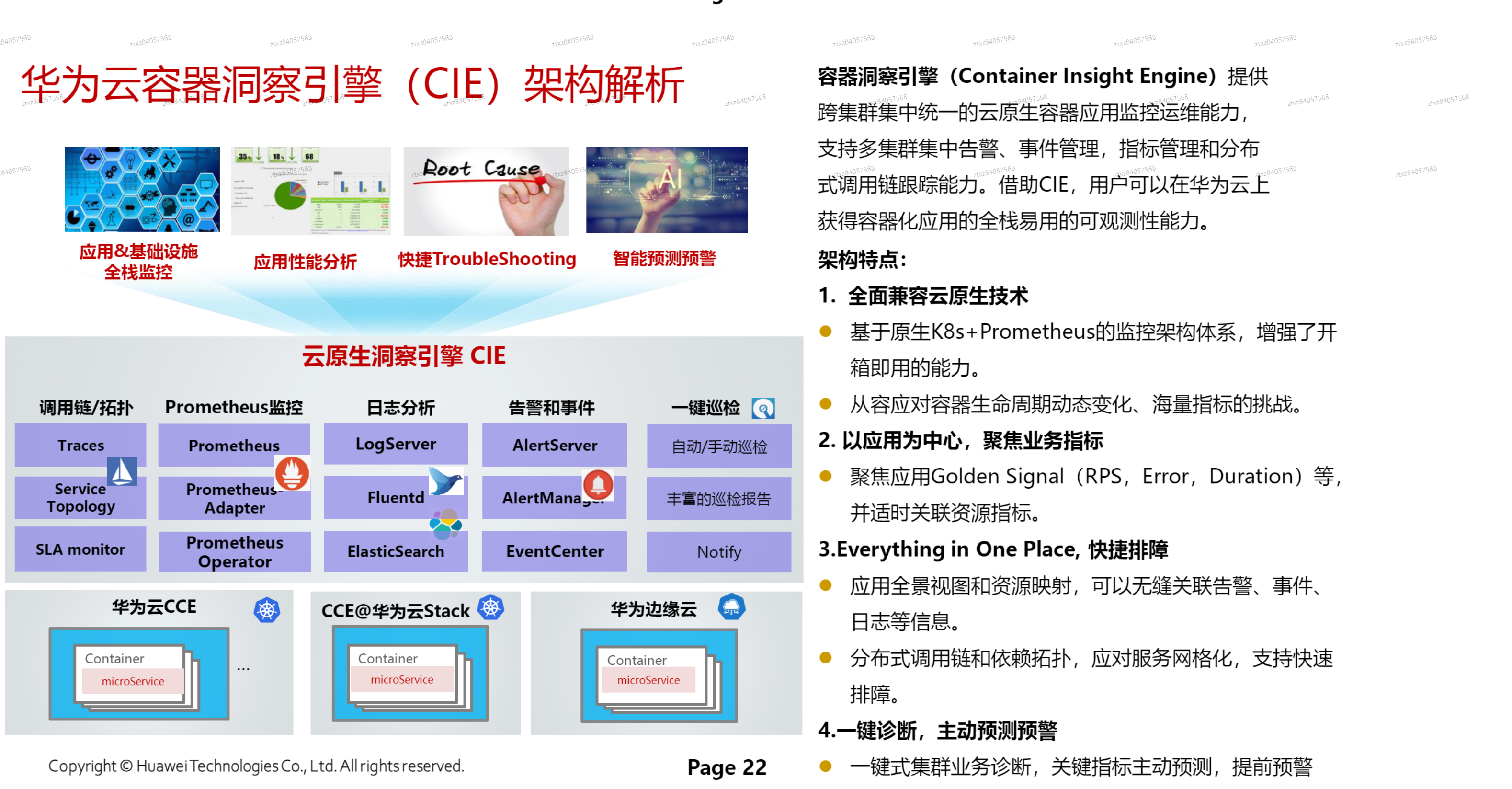
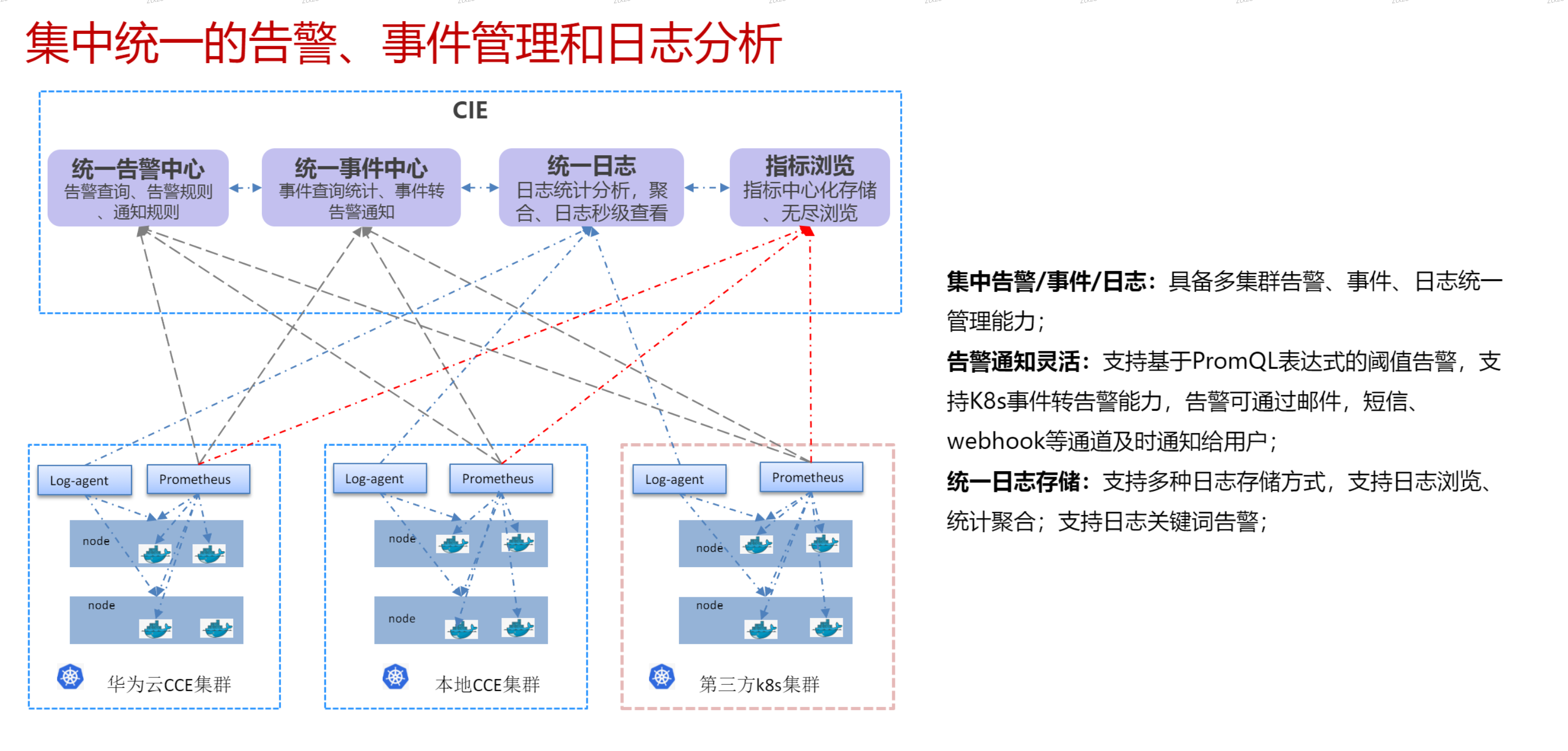
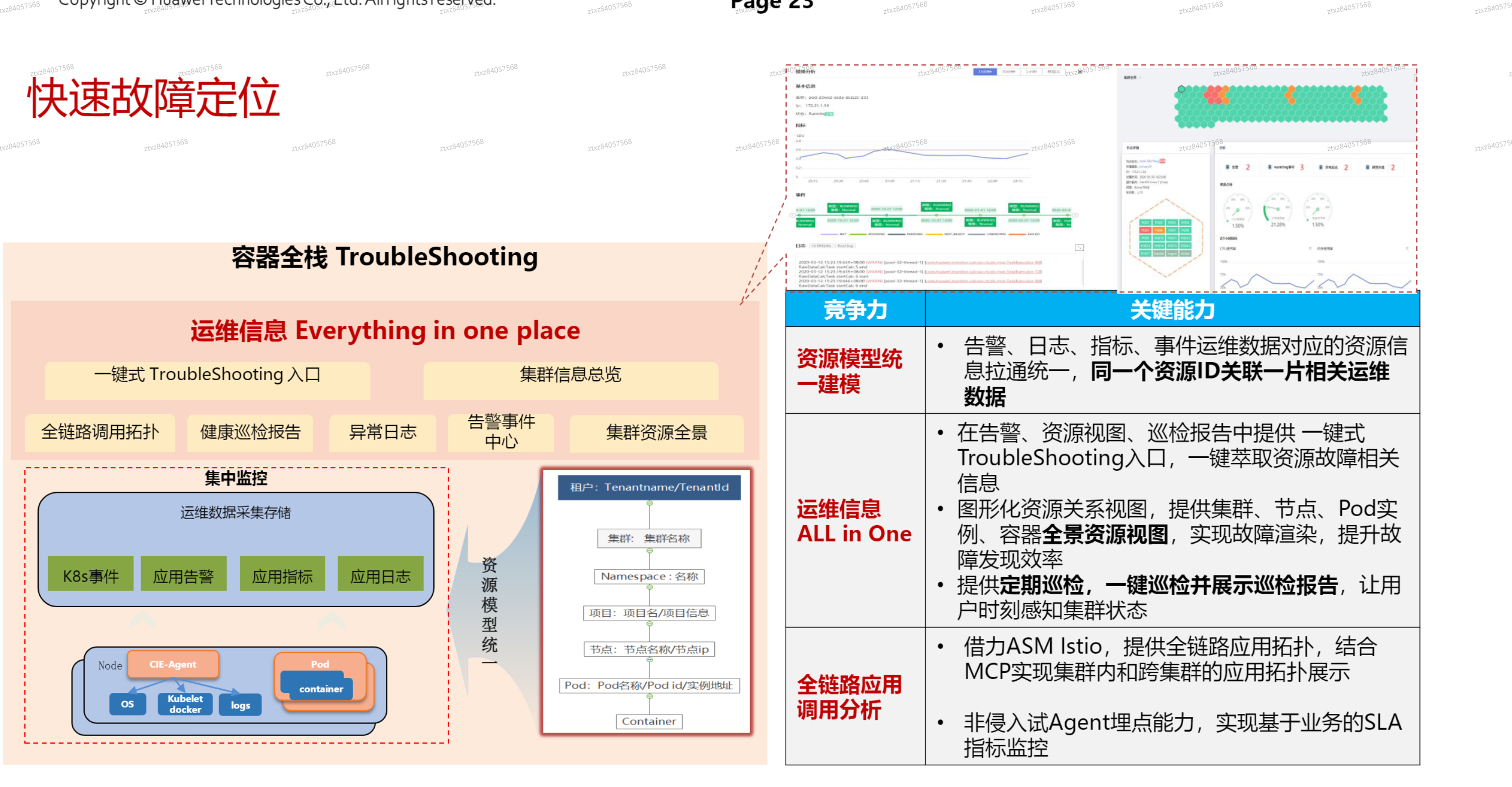
# 华为云CIE容器洞察引擎
# 监控相关拓展知识
Prometheus 采集容器数据通过 cAdvisor 提供的接口来获取
- cAdvisor通过容器运行时接口(CRI)获得数据
- 容器运行时分为runc: 主要是通过 Linux 内核的 cgroup 和其他相关的文件系统(如/proc)来获取数据
- runv:
- 在虚拟机内部,容器运行时(类似 runc 的机制)利用虚拟机操作系统的 cgroup 来统计容器资源使用情况
- 从主机角度,Hypervisor(如 KVM)会提供虚拟机层面的资源使用信息,如虚拟机的 CPU 使用率、内存使用量、网络和磁盘 I/O 等宏观指标。
- cAdvisor通过容器运行时接口(CRI)获得数据
对于NVIDIA GPU数据,通常依赖于 DCGM(NVIDIA Data Center GPU Manager)和 DCGM Exporter。
- DCGM:是用于管理和监控基于 Linux 系统的 NVIDIA GPU 大规模集群的一体化工具。它能提供主动健康监控、诊断、系统验证、策略、电源和时钟管理、配置管理和审计等多种功能。DCGM 提供用于收集 GPU 遥测的 API,能收集 GPU 的各种信息,比如 GPU 利用率指标、内存指标、流量指标等,这些数据是后续进行 GPU 监控和分析的基础。可以识别 GPU 上运行的各个进程,并统计每个进程的相关资源使用指标。
- DCGM Exporter: 使用 Go 绑定从 DCGM 收集 GPU 遥测数据,然后通过 HTTP 接口(通常是/metrics)向 Prometheus 暴露指标。
- 容器与GPU关联:从 Kubernetes 1.13 开始,kubelet 通过 /var/lib/kubelet/pod-resources 下的 Unix 套接字来提供 pod 资源查询服务。DCGM Exporter 中的 HTTP 服务可以连接到这个套接字服务,查询为每个 pod 分配的 GPU 设备信息。
- NVIDIA GPU Device Plugin: 遵循 Kubernetes 的 Device Plugin 机制。该插件会扫描节点上的 GPU 卡,并将 GPU 资源信息以扩展资源(ExtendedResource)的形式注册到节点中,供 Kubernetes 调度器使用。当 Pod 请求 GPU 资源时,Device Plugin 会与 Kubernetes 的 Kubelet 组件进行通信,告知其可用的 GPU 设备信息以及如何将 GPU 设备挂载到容器中。这样,Pod 中的容器就能够访问到分配给它的 GPU 设备。
- 多个pod使用同一张gpu部分设计到gpu虚拟化,如显存是相对隔离的,但对于 GPU 的计算核心,虽然多个 Pod 可以共享使用,但并不像传统的虚拟化那样进行严格的分割。在没有采用类似 MIG(Multi - Instance GPU) 这样的技术时,多个 Pod 内的应用程序通常是通过多线程或多进程的方式共享 GPU 的计算核心。它们利用 CUDA 等编程模型的调度机制来协调对计算核心的使用,这种共享方式更像是多个应用程序直接竞争使用 GPU 的计算核心资源,而不是每个 Pod 拥有独立的、经过虚拟化分割的计算核心。
- nvidia容器运行时做了一些什么?
- 资源隔离与分配:
- GPU 设备隔离:NVIDIA 容器运行时(如 nvidia - docker)能够将 GPU 设备有效地隔离并分配给不同的容器。它通过与 NVIDIA GPU Device Plugin 以及容器编排工具(如 Kubernetes)协同工作,确保每个容器能够访问到分配给自己的 GPU 设备。例如,在一个多租户的场景中,不同用户的容器可能需要使用不同的 GPU 资源,nvidia 容器运行时会根据配置信息,将物理 GPU 的资源划分给各个容器,使得容器就像拥有独立的 GPU 一样进行操作。
- 显存隔离与分配:对于 GPU 显存,它也能进行合理的隔离和分配。通过设置适当的参数和机制,容器运行时可以限制每个容器能够使用的显存大小。例如,当一个容器启动时,nvidia 容器运行时可以根据容器的配置文件或者命令行参数,为其分配指定大小的显存,防止一个容器过度占用显存而影响其他容器的正常运行。
- 环境配置与依赖管理:
- 驱动程序配置:NVIDIA 容器运行时会在容器内部自动配置 GPU 驱动程序相关的环境。这意味着在容器内部,应用程序可以像在主机系统上一样正常地使用 GPU,而无需在每个容器内部单独安装和配置 GPU 驱动。它会将主机系统中的 GPU 驱动程序以一种合适的方式映射到容器环境中,使得容器能够正确地与 GPU 进行通信。
- CUDA 库和其他依赖项:除了驱动程序,它还会管理容器内部的 CUDA(Compute Unified Device Architecture)库等 GPU 相关的依赖项。CUDA 库是使用 NVIDIA GPU 进行并行计算的关键软件库,nvidia 容器运行时会确保容器内的 CUDA 库版本与主机系统的 GPU 以及其他相关组件兼容。例如,它会根据主机系统的 CUDA 版本,在容器内部挂载相同版本或者经过适配的 CUDA 库,以便容器内的应用程序能够顺利地调用 CUDA 函数进行 GPU 计算。
- 优化容器内 GPU 使用体验:
- 性能优化:通过一系列的内部机制,NVIDIA 容器运行时可以优化容器内 GPU 的使用性能。例如,它可以调整 GPU 的一些参数设置(如电源管理模式、显存带宽分配等),以适应容器内应用程序的需求。对于一些对性能要求极高的应用场景,如深度学习训练和推理任务,这种性能优化可以显著提高应用程序的执行效率。
- 监控和日志记录:它还可以提供容器内 GPU 使用情况的监控和日志记录功能。这使得开发人员和运维人员能够更好地了解容器对 GPU 资源的使用情况,包括 GPU 利用率、显存使用量、温度等指标。通过分析这些监控数据和日志,可以及时发现潜在的问题,如 GPU 资源过度使用、异常的温度升高等,并采取相应的措施进行调整和优化。
- 资源隔离与分配:
- NVML(NVIDIA Management Library)是 NVIDIA 提供的一个基于 C 语言的应用程序接口(API)库,用于监测和管理 NVIDIA GPU 设备的各种状态。它提供了对 NVIDIA GPU 的直接访问,能够查询和获取 GPU 的多种信息,比如 GPU 的温度、功率、风扇转速、显存使用情况、GPU 利用率、ECC 错误计数、时钟频率、设备识别信息等。并且,NVML 是向后兼容的,旨在为第三方应用程序的开发提供一个稳定的平台。
- DCGM(Data Center GPU Manager)则是用于管理和监控基于 Linux 系统的 NVIDIA GPU 大规模集群的一体化工具。它具有主动健康监控、诊断、系统验证、策略、电源和时钟管理、配置管理和审计等多种功能。DCGM 提供了用于收集 GPU 遥测数据的 API。
- nvidia-smi命令就是基于 NVML 构建的命令行实用工具。DCGM 可以单独安装,其操作命令为dcgmi。虽然 NVML 主要用于单个 GPU 的监控和管理,而 DCGM 更侧重于集群环境下的 GPU 管理,但在一些需要更全面、深入的 GPU 监控和管理的场景中,开发者可能会同时使用 NVML 和 DCGM 来获取更详细的信息和实现更复杂的管理功能。
- DCGM 底层确实会调用每张 GPU 卡的 NVML
- GPU 的时钟速度(Clock Speed),也称为 GPU 核心频率,是指 GPU 芯片内部的时钟发生器产生的时钟信号的频率。它通常以兆赫兹(MHz)或吉赫兹(GHz)为单位来衡量。简单来说,时钟速度决定了 GPU 每秒能够处理的基本操作次数,是衡量 GPU 运算速度的一个关键指标。
- GPU 的内部包含大量的计算单元(如 CUDA 核心)和其他组件,这些单元的工作就像一个高度协调的团队。时钟信号就像是这个团队的指挥节奏,每一个时钟周期,计算单元就会执行一次基本操作。例如,在一个时钟周期内,一个 CUDA 核心可能会完成一次乘法 - 加法运算。较高的时钟速度意味着每秒有更多的时钟周期,从而使 GPU 能够在单位时间内执行更多的计算操作。
一味的升高gpu时钟频率,除了会产生过多热量,功耗更高,损伤硬件之外,会对计算有什么影响吗?
计算稳定性下降:
- 原理:当 GPU 时钟频率过高时,计算单元的工作节奏变得过快,可能会导致信号传输出现问题。在每个时钟周期内,数据需要在 GPU 的各个组件(如寄存器、缓存、计算核心等)之间准确地传输和处理。如果时钟频率过高,数据传输可能来不及完成,就像一个人跑步速度太快,可能会摔倒一样。这种情况下,可能会出现数据错误或者丢失,导致计算结果不准确。
- 示例:在深度学习模型训练过程中,如果 GPU 时钟频率过高,可能会导致梯度计算错误。梯度是用于更新模型参数的重要信息,错误的梯度会使模型训练朝着错误的方向进行,导致模型无法收敛或者收敛到一个错误的结果。例如,在训练一个图像识别模型时,过高的时钟频率可能会使模型对图像特征的提取和学习出现偏差,从而降低模型的准确率。
性能提升边际效益递减
- 原理:在一定范围内,提高 GPU 时钟频率可以提升计算性能。但是,随着时钟频率的不断升高,性能提升的效果会逐渐减弱。这是因为 GPU 的性能不仅仅取决于时钟频率,还受到其他因素(如内存带宽、数据传输延迟、计算单元的并行度等)的限制。当这些其他因素成为瓶颈时,单纯提高时钟频率并不能带来与之成正比的性能提升。
- 示例:假设一款 GPU 的初始时钟频率为 1GHz,将其提升到 1.2GHz 时,性能提升了 20%。但是,当继续将时钟频率提升到 1.4GHz 时,由于内存带宽等因素的限制,性能可能只提升了 10%。这种边际效益递减意味着,过度追求时钟频率的提升可能会导致投入(如功耗增加、硬件风险提升)与产出(性能提升)不成正比。
系统兼容性和软件异常:
- 原理:过高的时钟频率可能会导致 GPU 与系统的其他组件(如主板、电源等)出现兼容性问题。此外,一些软件可能是基于 GPU 的标准时钟频率进行优化的。当 GPU 时钟频率过高时,软件可能无法正常工作,或者出现错误。
- 示例:在一些专业图形设计软件中,如 Adobe Photoshop 或 3ds Max,它们在开发过程中会考虑 GPU 的正常工作参数。如果 GPU 时钟频率过高,可能会导致这些软件在渲染图形时出现画面闪烁、纹理错误或者软件崩溃等现象。因为软件的渲染算法和 GPU 的交互是基于一定的性能预期进行设计的,过高的时钟频率打乱了这种平衡。
集成电路的角度看时钟频率
在集成电路(IC)中,时钟频率(Clock Frequency)是指芯片内部时钟信号的振荡频率。它就像是一个节拍器,为芯片内所有的数字电路(如逻辑门、寄存器、计数器等)提供同步的时序基准。芯片的各种操作,如数据的读取、写入、运算等,都是按照这个时钟信号的节拍来进行的。以一个简单的例子来说,想象一个工厂的生产线,时钟频率就像是生产线的传送带速度,它决定了产品(数据)在各个生产环节(电路模块)之间移动和加工的速度。
在集成电路中,时钟信号通常由一个专门的时钟发生器(Clock Generator)产生。这个时钟发生器可以是一个简单的晶体振荡器(Crystal Oscillator),它利用石英晶体的压电效应产生稳定的振荡信号。例如,一个常见的石英晶体振荡器可以产生频率为 12MHz 或 100MHz 等标准频率的时钟信号。这个信号随后会经过一些缓冲器(Buffer)和分频器(Divider)等电路进行调整和分配,以满足芯片内部不同模块对时钟频率的需求。
时钟信号通过芯片内部的金属布线(通常是铝或铜等金属制成的互连线)在整个芯片中传播。这些布线就像是城市中的道路,将时钟信号输送到各个需要它的电路角落。然而,由于布线的长度、电阻、电容等因素的影响,时钟信号在传播过程中会出现延迟(Delay)和信号失真(Signal Distortion)。例如,较长的布线会导致信号延迟,就像声音在长管道中传播会有延迟一样;而布线的电容会使时钟信号的上升沿和下降沿变得不那么陡峭,影响信号的质量。为了尽量减小这些影响,芯片设计工程师会采用各种技术,如优化布线布局、使用信号中继器(Repeater)等来确保时钟信号的准确传播。
集成电路中的各种数字电路模块(如寄存器、算术逻辑单元 ALU 等)都按照时钟信号的节拍进行同步操作。以寄存器为例,它是一种用于存储数据的电路元件。在每个时钟信号的上升沿(Positive Edge)或下降沿(Negative Edge),寄存器会根据输入信号更新其存储的数据。
为什么要限制频率
- 工艺和功耗限制:集成电路的制造工艺(如晶体管的尺寸、材料等)对时钟频率有很大的限制。随着晶体管尺寸的不断缩小,晶体管的性能和可靠性会受到挑战。例如,在超小型晶体管中,电子的隧穿效应(Tunneling Effect)会变得更加明显,这可能导致电路漏电增加,从而限制了时钟频率的提高。
- 信号完整性限制:如前面提到的,时钟信号在传播过程中会受到布线延迟、信号失真等因素的影响。当时钟频率过高时,这些问题会更加严重。例如,在高频情况下,信号的上升沿和下降沿时间变得非常短,如果信号失真严重,可能会导致电路无法正确识别时钟信号的边沿,从而出现错误的操作。
# GPU驱动 vs GPU固件
定义和本质区别
- GPU 驱动:是软件程序,存储在计算机的硬盘或系统存储中,它是可以被操作系统和用户更新的部分。其代码主要是用于在操作系统、应用程序和 GPU 硬件之间进行交互沟通,根据操作系统和应用程序的指令来控制 GPU 的操作。例如,在 Windows 操作系统中,用户可以通过设备管理器或显卡厂商的官方软件来更新 GPU 驱动程序。
- GPU 固件:更像是一种嵌入在 GPU 硬件内部的 “小型操作系统”,它存储在 GPU 芯片的非易失性存储介质(如 ROM 或闪存)中。固件主要负责 GPU 硬件本身最基本的初始化、启动以及一些非常底层的硬件功能控制。比如,当 GPU 芯片上电启动时,固件会首先运行,进行一些基本的硬件自检和初始化设置,像是设置 GPU 核心的时钟频率、检测显存的初始状态等。
功能重点差异
- GPU 驱动的功能重点:
- 指令转换与资源管理:如前面所述,它主要负责将应用程序通过图形 API(如 OpenGL、DirectX)发送的高级图形指令转换为 GPU 能够理解的底层指令。并且会对 GPU 的各种资源(如显存、计算单元)进行合理分配,以满足不同应用程序的需求。例如,在运行多个图形应用程序时,驱动会根据应用程序的请求动态地分配显存给每个应用程序用于存储纹理、顶点数据等。
- 性能优化与兼容性维护:驱动开发者会根据 GPU 硬件的特性和软件应用的发展,不断优化性能。例如,针对新的游戏或者图形软件,驱动可能会优化指令执行顺序、采用新的算法来提升渲染效率。同时,驱动也确保 GPU 与各种操作系统(Windows、Linux、macOS 等)和不同版本的应用程序之间的兼容性。
- GPU 固件的功能重点:
- 硬件初始化与基本操作:在 GPU 刚上电启动时,固件负责初始化 GPU 的各个硬件组件。例如,它会对 GPU 的内存控制器进行初始化,设置正确的内存访问模式和时序参数,确保后续对显存的访问能够正常进行。同时,固件还会对 GPU 的显示输出接口(如 HDMI、DisplayPort)进行初始化,设置合适的分辨率和刷新率等基本参数。
- 硬件级别的错误检测与修复(在一定程度上):固件能够检测一些硬件层面的基本错误。比如,在 GPU 启动过程中,它可以检测显存是否存在物理损坏或者读取错误。如果发现问题,固件可能会尝试进行一些简单的修复操作,如重新初始化出错的显存模块或者调整错误的硬件参数。不过这种修复能力是有限的,对于严重的硬件故障,固件可能只能报告错误,等待进一步的维修。
- GPU 驱动的功能重点: