Ch02_Code
Yang Haoran 11/27/2023 HuggingFace
# Test
from transformers import pipeline
if __name__ == '__main__':
print("111")
classfier = pipeline("sentiment-analysis")
print(classfier(
[
"I've been waiting for huggingface course for my whole life.",
"I hate this so much!",
"Its hard to say",
]
))
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# tokenizer(指定名字自动选tokenizer)
from transformers import AutoTokenizer
# import torch # 如果pytorch安装成功即可导入
import torchtext
import datasets
import transformers
import torch
import torchvision
import torchaudio
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
# print(torchtext.__version__)
# print(datasets.__version__)
# print(transformers.__version__)
# print(torch.__version__, torchvision.__version__, torchaudio.__version__)
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# 根据模型自动加载分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for huggingface course for my whole life.",
"I hate this so much!",
"It's insteresting",
]
# padding 表示把每句句子加上空格,凑齐长度
# truncation 表示最大长度 一般512字
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
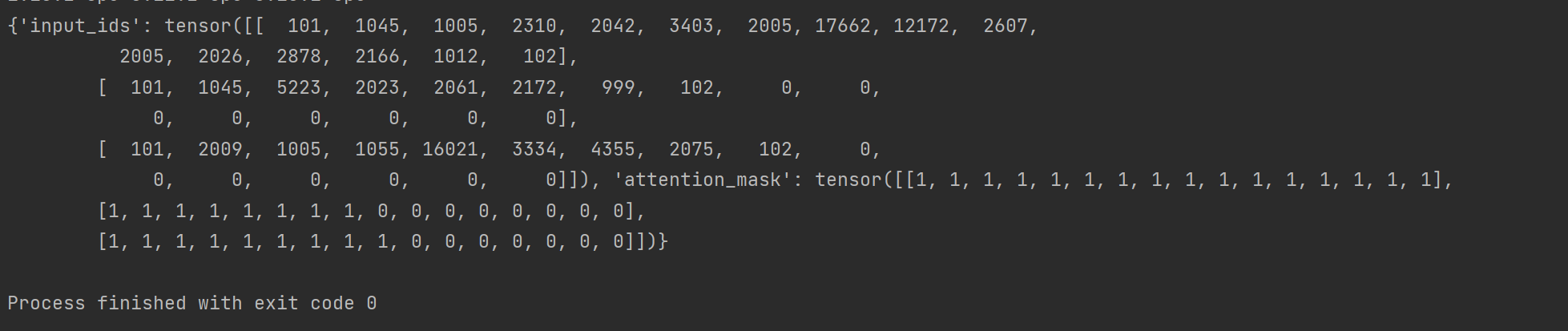
- attention mask 表示每个字符都要跟之前的字符算关系

- 开始和终止自动补充字符
# model(指定名字自动选model)
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# 根据模型自动加载分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for huggingface course for my whole life.",
"I hate this so much!",
"It's insteresting",
]
# padding 表示把每句句子加上空格,凑齐长度
# truncation 表示最大长度 一般512字
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
# 自动选模型
model = AutoModel.from_pretrained(checkpoint)
print(model)
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25

- 一共三句输入,每句输入变成16个token,每个token都编码成768维向量
from transformers import AutoModelForSequenceClassification
import torch
# 自动获取分类输出头
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print("logits")
print(outputs.logits.shape)
# 根据输出头自己获取他最后的结果
pridictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print("pridictions")
print(pridictions)
# tensor([[7.3581e-03, 9.9264e-01],
# [9.9946e-01, 5.4418e-04],
# [9.4180e-01, 5.8201e-02]], grad_fn= < SoftmaxBackward0 >)
print(model.config.id2label) # 查看最终标签是什么 {0: 'NEGATIVE', 1: 'POSITIVE'}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15

多了一个全连接层,表示输出结果是三个句子,每个句子是二分类
如果要自定义每个词的id是多少,不能忘了加attention mask(跟子网掩码一个道理)
pad_token_id就是占位符,表示哪些字符是补的0
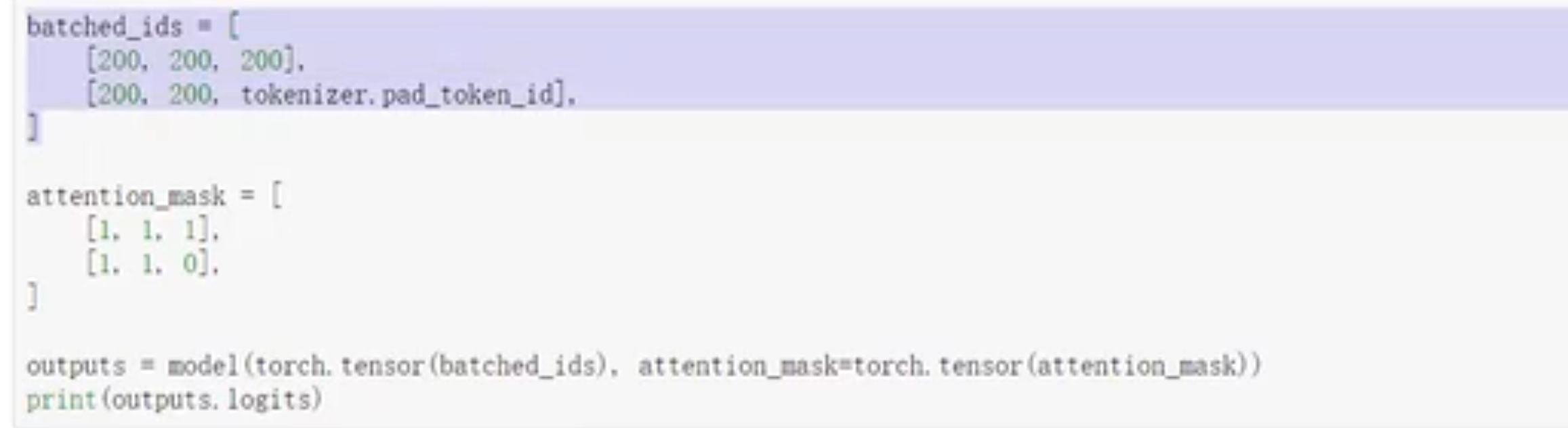
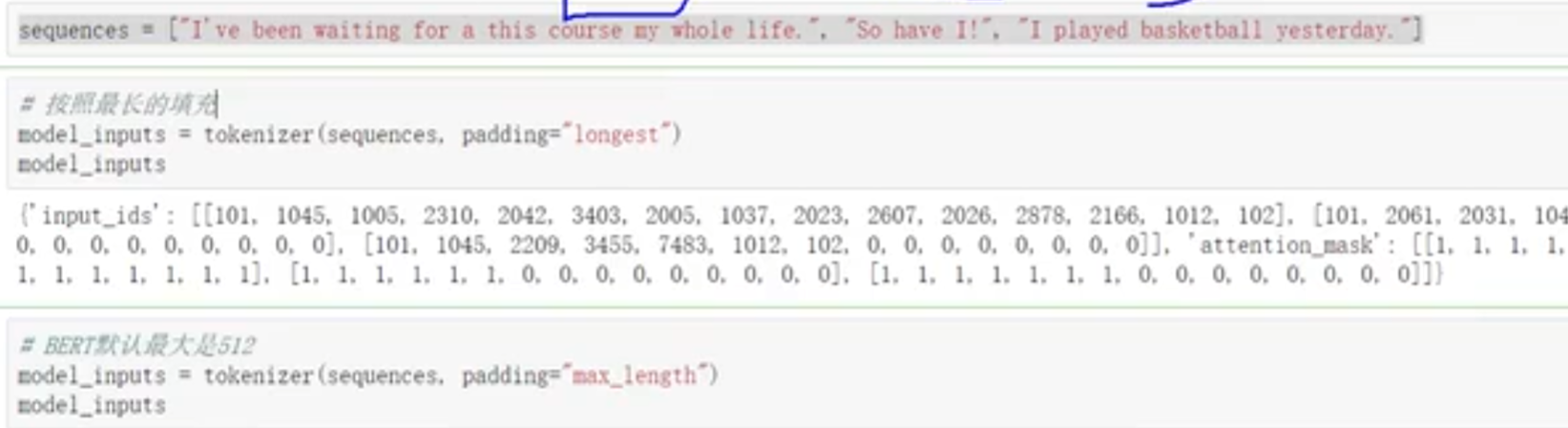
# padding方法
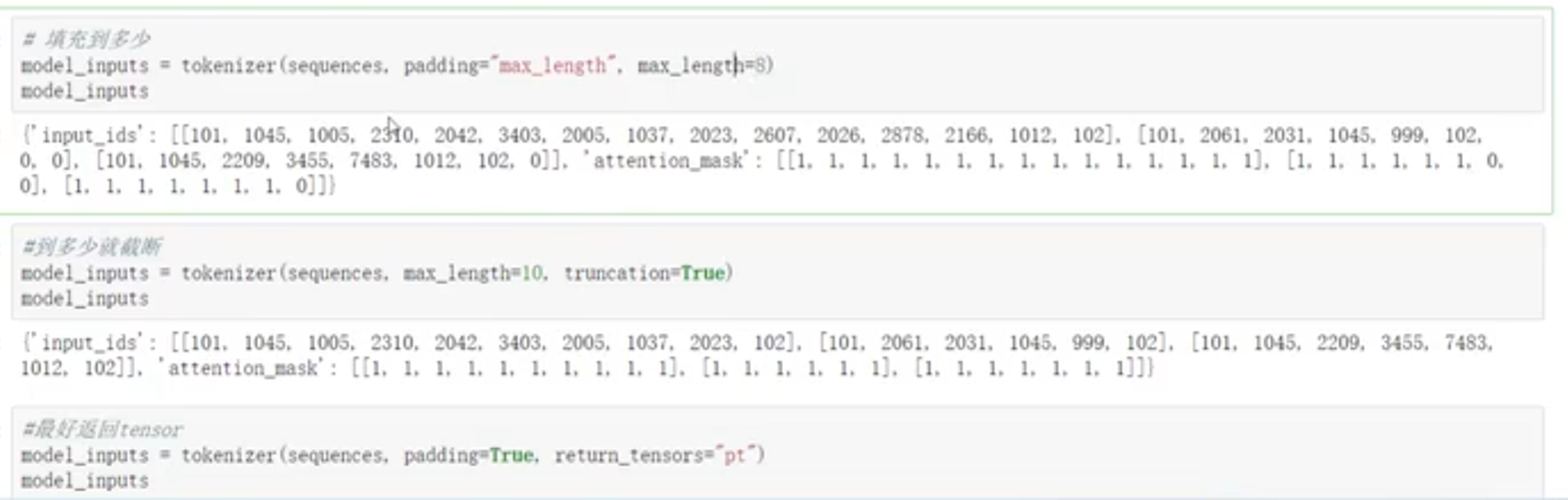
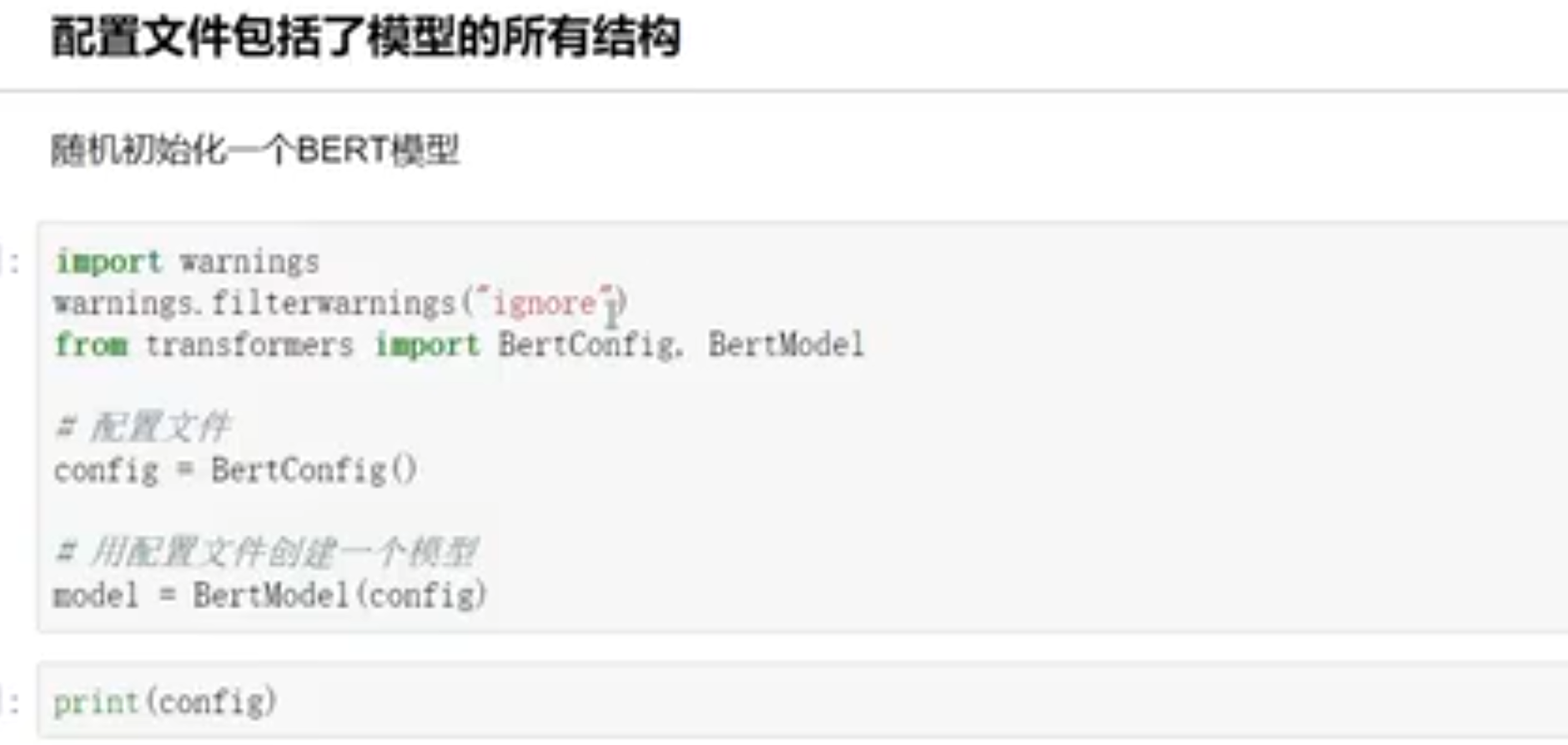
# 用配置文件创建模型
# 保存模型
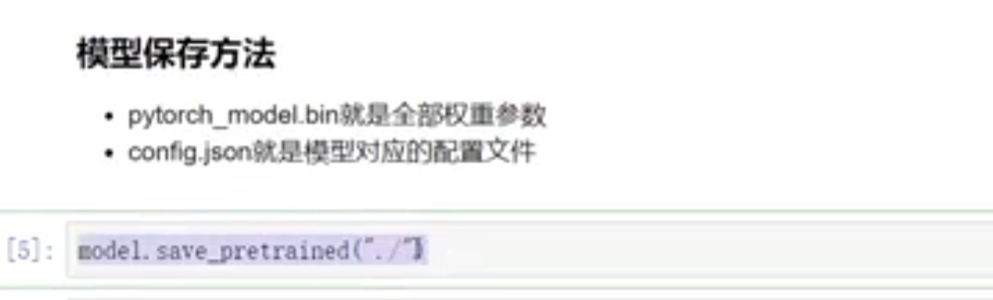
# 完整
from transformers import AutoTokenizer
from transformers import AutoModel
from transformers import AutoModelForSequenceClassification
import torch
def test():
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# 根据模型自动加载分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for huggingface course for my whole life.",
"I hate this so much!",
"It's insteresting",
]
# padding 表示把每句句子加上空格,凑齐长度
# truncation 表示最大长度 一般512字
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print("------------inputs-----------")
print(inputs)
# 自动选模型
model = AutoModel.from_pretrained(checkpoint)
print("--------------model-----------")
print(model)
outputs = model(**inputs)
print("-------------shape------------")
print(outputs.last_hidden_state.shape)
print("-------------outputs------------")
print(outputs)
# 自动获取分类输出头
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print("---------------logits shape------------")
# 在深度学习中,特别是在分类问题中,"logits" 是指模型的输出层的未经过 softmax 激活函数的原始输出。
# Logits 是网络在每个类别上的得分或预测值,这些得分可以通过 softmax 函数转换为概率分布。
print(outputs.logits.shape)
# 根据输出头自己获取他最后的结果
pridictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print("-------------pridictions---------------")
print(pridictions)
# tensor([[7.3581e-03, 9.9264e-01],
# [9.9946e-01, 5.4418e-04],
# [9.4180e-01, 5.8201e-02]], grad_fn= < SoftmaxBackward0 >)
print(model.config.id2label) # 查看最终标签是什么 {0: 'NEGATIVE', 1: 'POSITIVE'}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# dataset
from datasets import load_dataset
def data():
raw_dataset = load_dataset("glue", "mrpc")
print(raw_dataset)
raw_train_dataset = raw_dataset["train"]
# 对数据集的解释
print(raw_train_dataset.features)
print(raw_train_dataset[100])
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
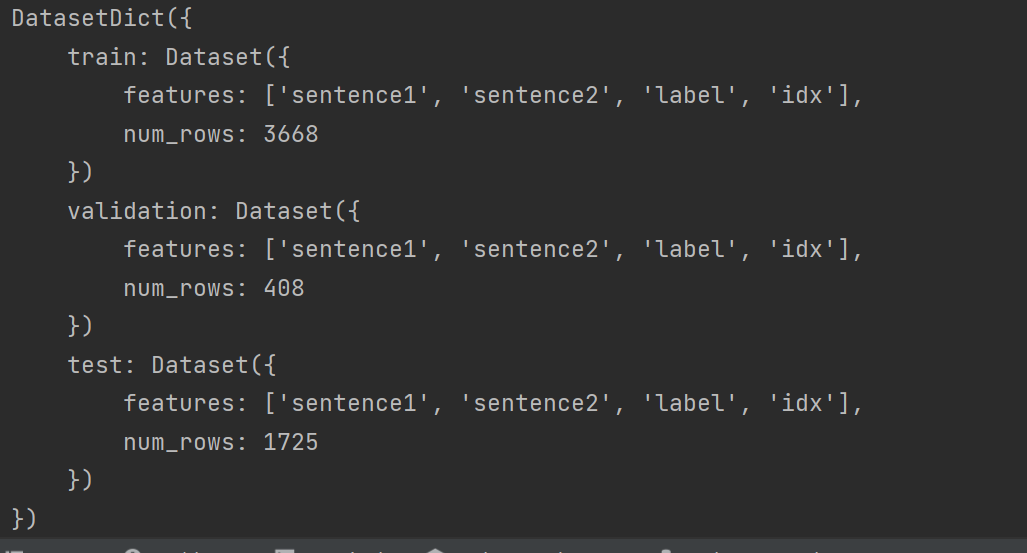
- label表示两句句子相不相关
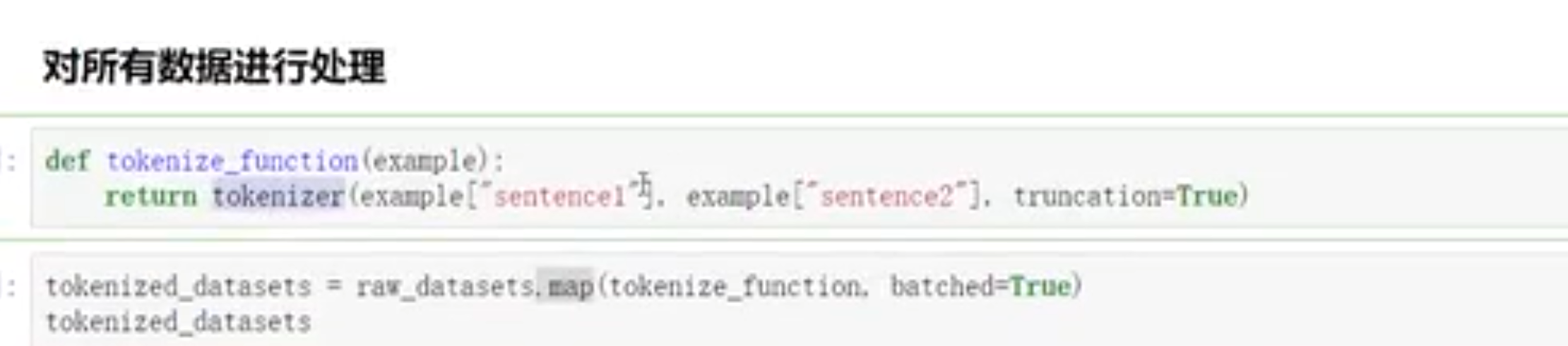
- 对数据处理推荐用函数
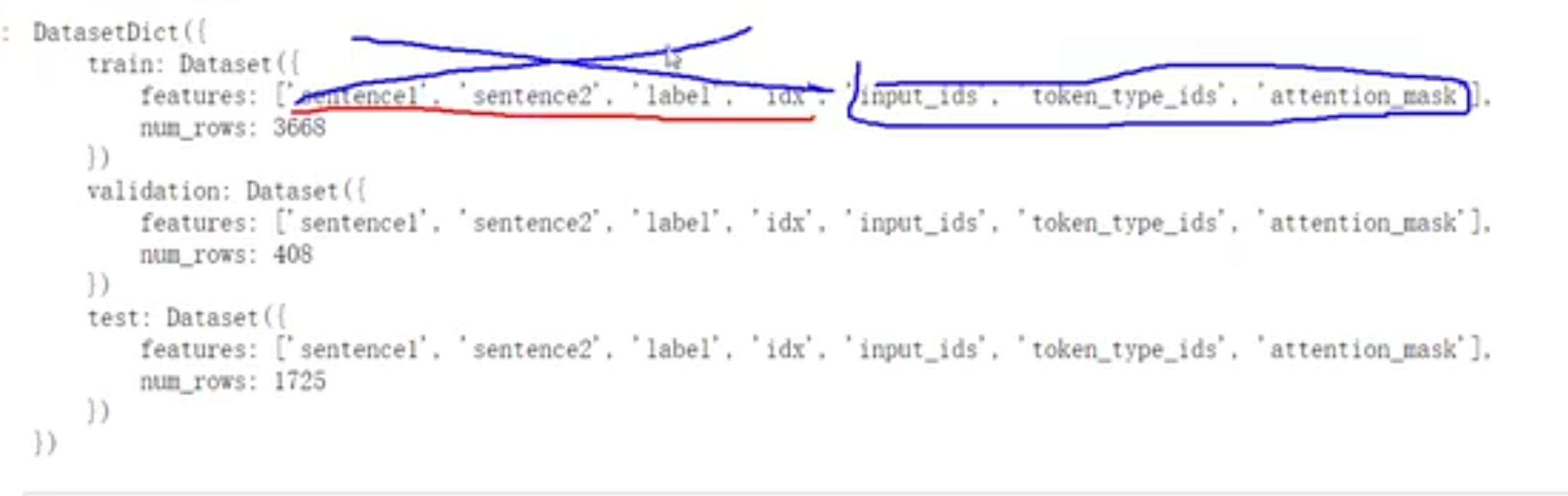
- 处理完之后,本来的字段就没有用了,应该删掉
- 可以理解为一个dataloader


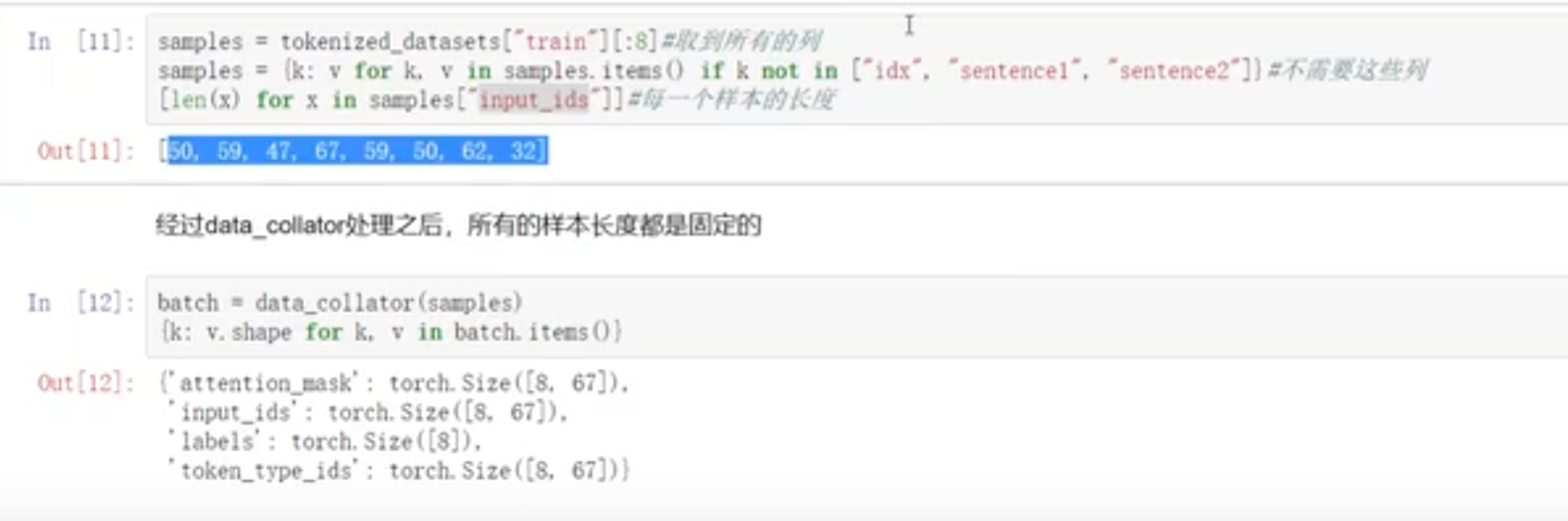
- 取前8行,删除前面不需要的的字段
# Tokenizer
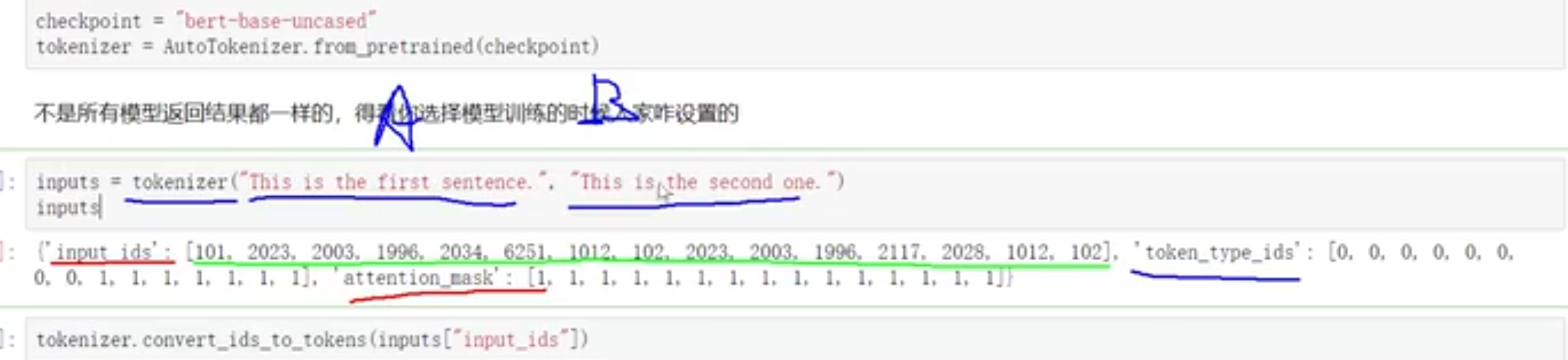
- 在两句话是否相关的任务中,会把这两句话拼起来,并用token_type_id 表示哪几个词属于第一句话
# Training
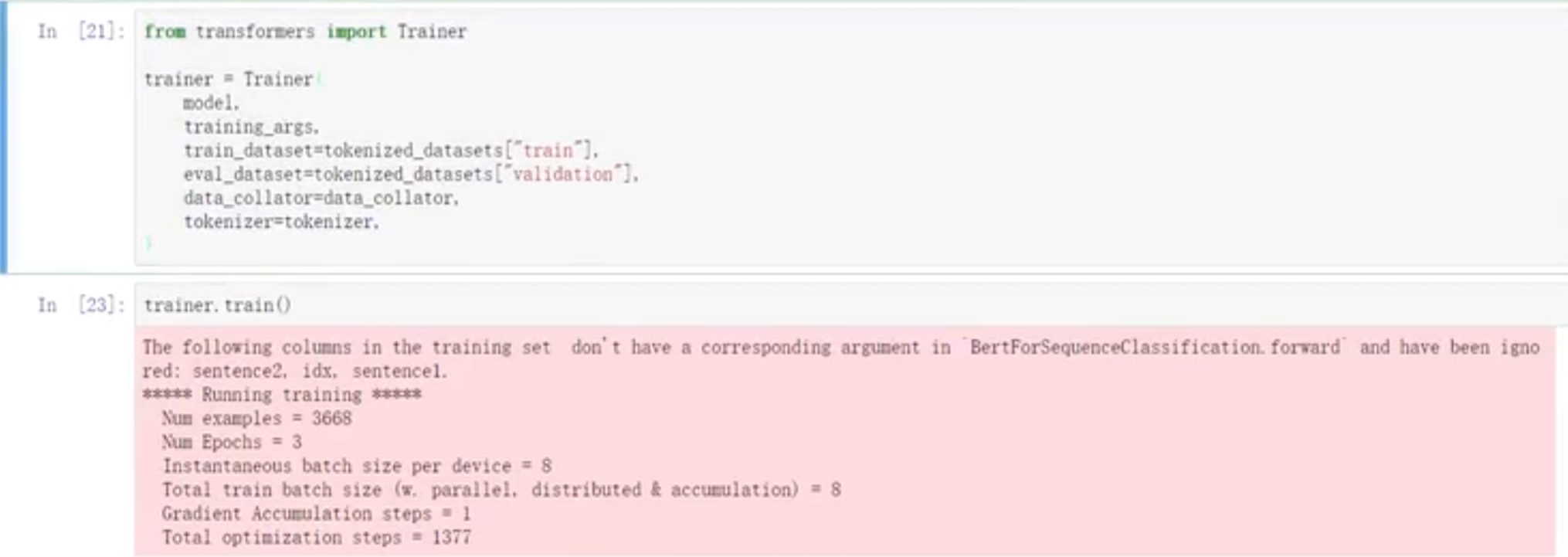
- 要分类还是预测?用啥导啥包

- 输出层都是我们自己去训练,怎么训练?
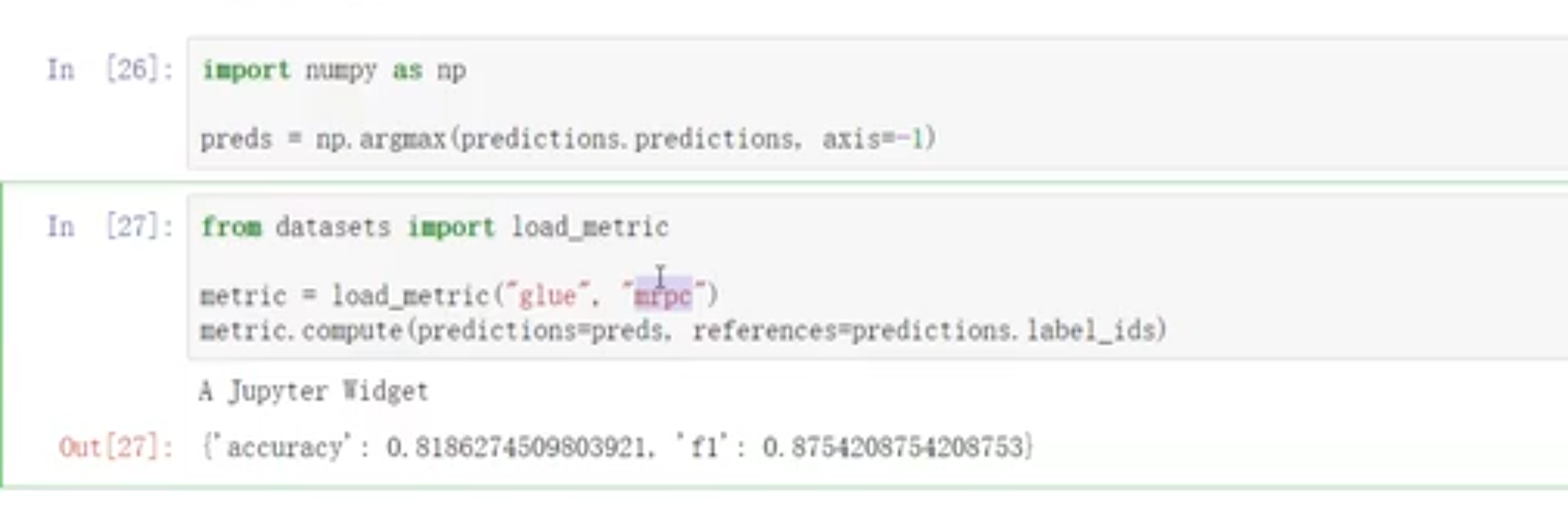
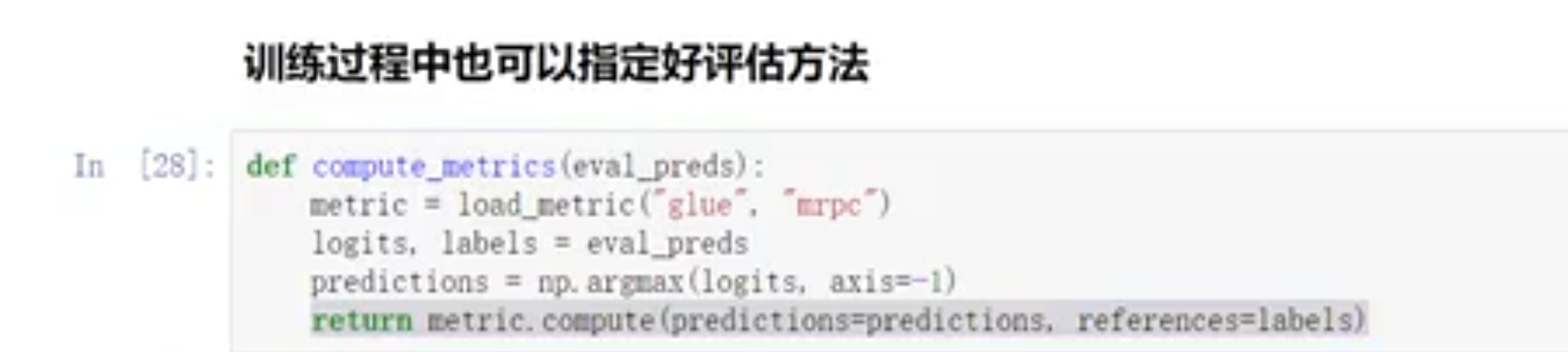
# 测试

- 增加评估方法(可以直接使用别人的评估方法,compute【预测值,真实值】)