
Ch20 RNN
Yang Haoran 7/3/2022 TensorflowRNN
# Ch20 RNN
# 用RNN实现连续数据的预测,比如股票预测

# 卷积:

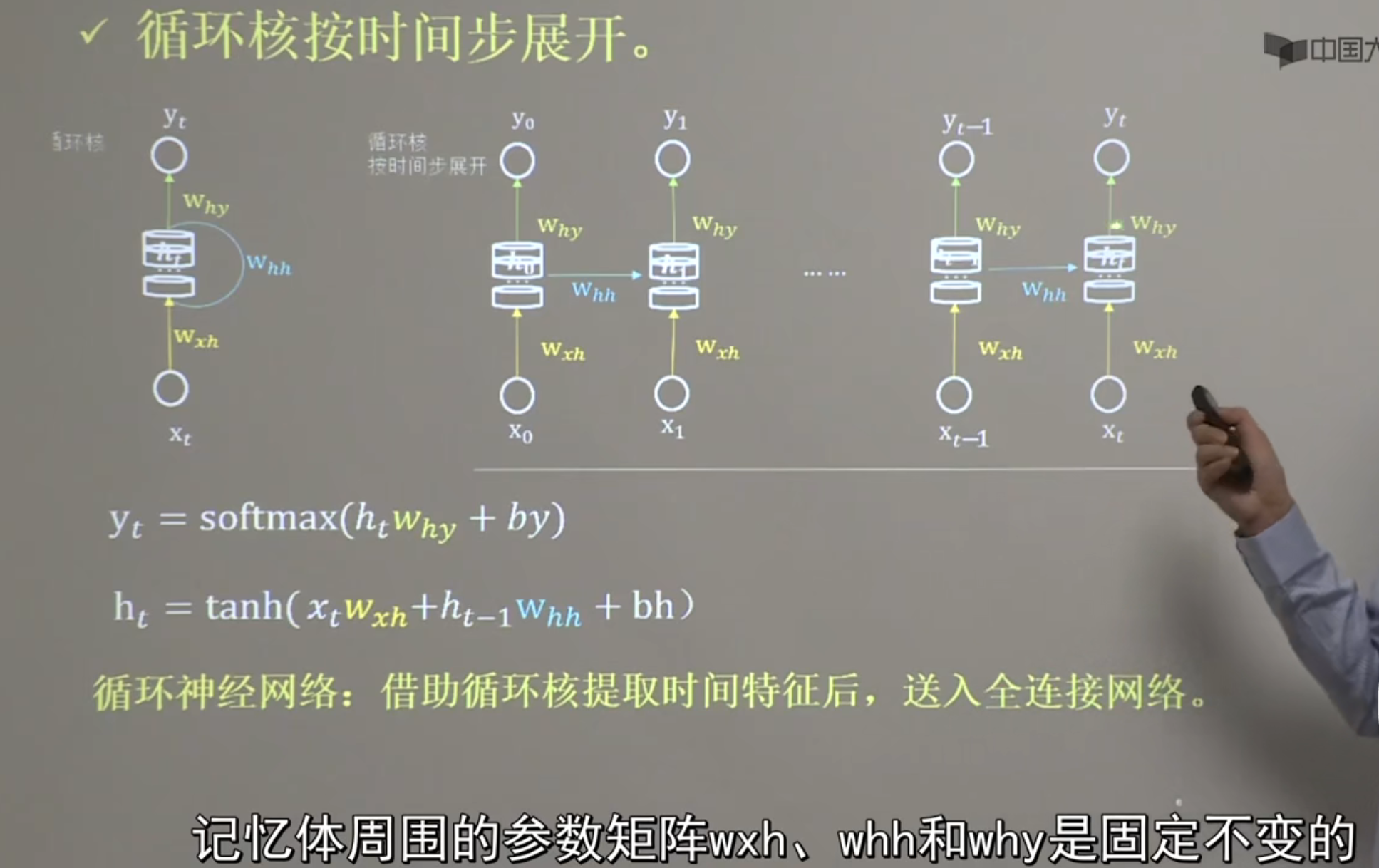
# 循环核
比如鱼离不开_. 第一反应是水,因为我们有对历史数据的记忆
循环核就是由一个记忆体组成,上面,下面,侧面都有一组待训练参数

tanh,softmax都是激活函数, yt就是全连接网络
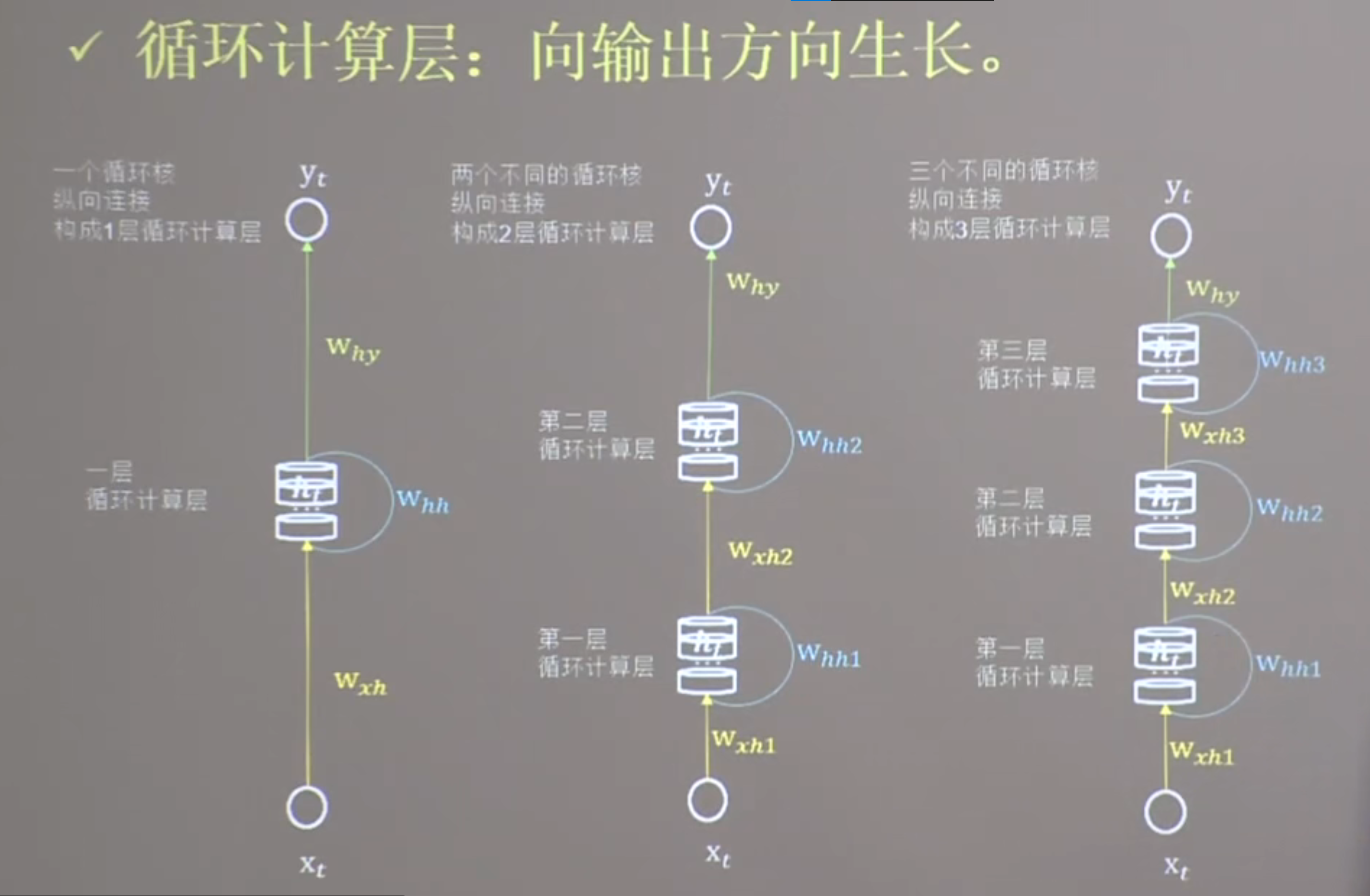
- 记忆体个数纵向扩展
# TF

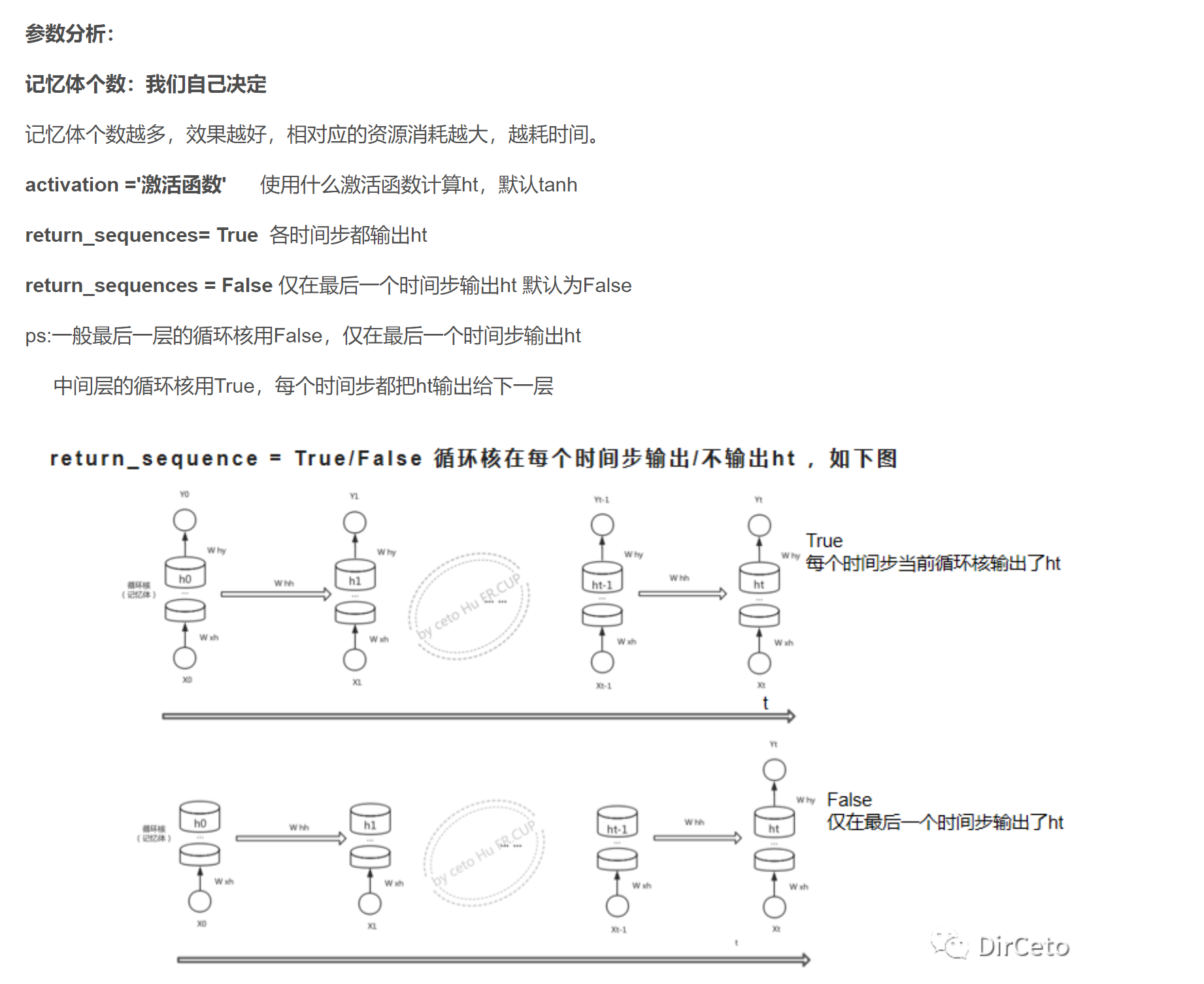
一般最后一个循环核用false,中间的循环核用true
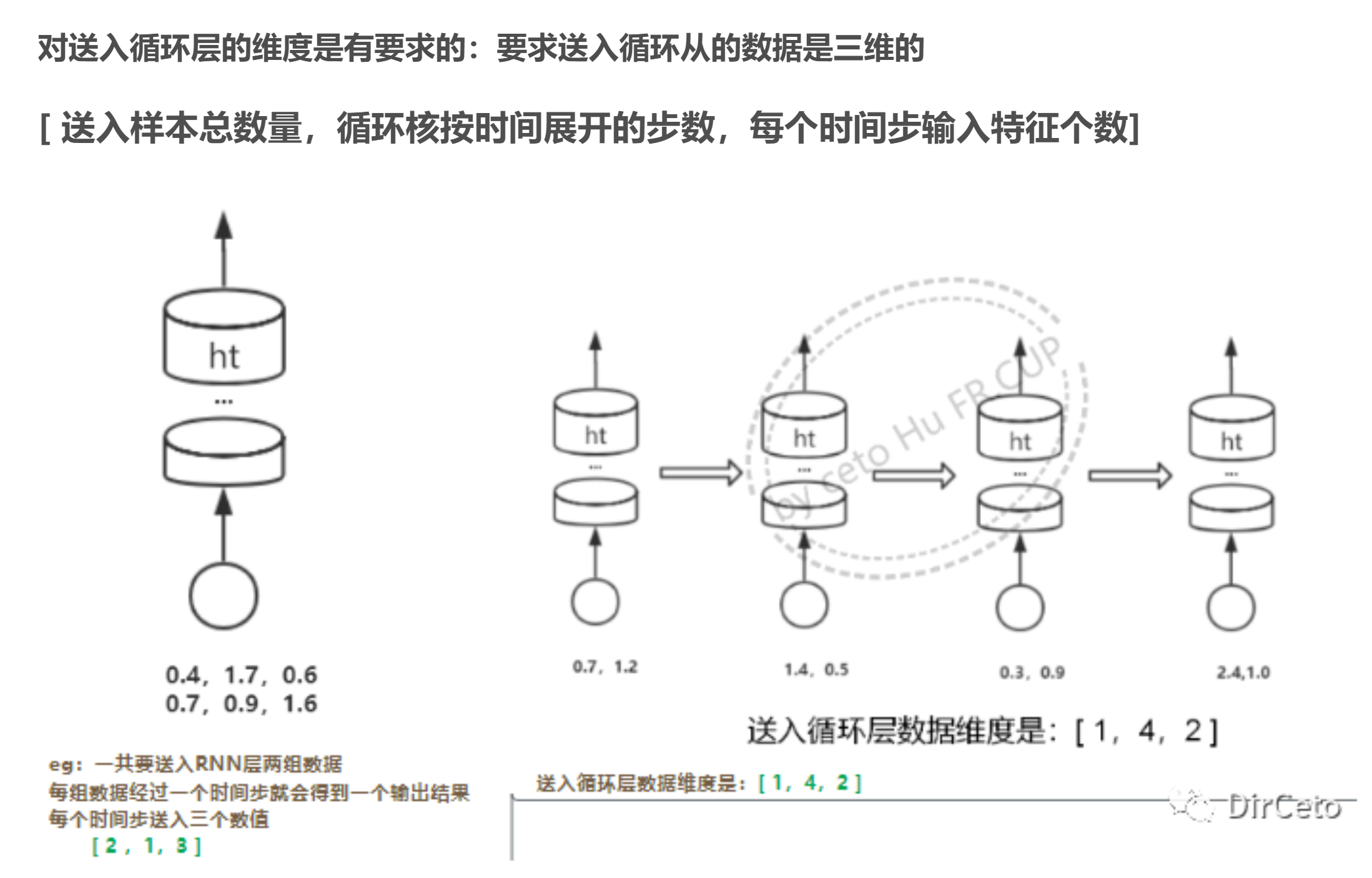
详细计算过程

训练一个网络,输入一个字母,预测下一个字母:
import numpy as np import tensorflow as tf from tensorflow.keras.layers import Dense, SimpleRNN import matplotlib.pyplot as plt import os input_word = "abcde" w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典 id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.], 4: [0., 0., 0., 0., 1.]} # id编码为one-hot x_train = [id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]] y_train = [w_to_id['b'], w_to_id['c'], w_to_id['d'], w_to_id['e'], w_to_id['a']] np.random.seed(7) np.random.shuffle(x_train) np.random.seed(7) np.random.shuffle(y_train) tf.random.set_seed(7) # 使x_train符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。 # 此处整个数据集送入,送入样本数为len(x_train);输入1个字母就出结果,所以循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5 # 见上面图片详细解释 x_train = np.reshape(x_train, (len(x_train), 1, 5)) y_train = np.array(y_train) model = tf.keras.Sequential([ SimpleRNN(3), Dense(5, activation='softmax') ]) model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['sparse_categorical_accuracy']) checkpoint_save_path = "./checkpoint/rnn_onehot_1pre1.ckpt" if os.path.exists(checkpoint_save_path + '.index'): print('-------------load the model-----------------') model.load_weights(checkpoint_save_path) cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path, save_weights_only=True, save_best_only=True, monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型 history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback]) model.summary() # print(model.trainable_variables) file = open('./weights.txt', 'w') # 参数提取 for v in model.trainable_variables: file.write(str(v.name) + '\n') file.write(str(v.shape) + '\n') file.write(str(v.numpy()) + '\n') file.close() ############################################### show ############################################### # 显示训练集和验证集的acc和loss曲线 acc = history.history['sparse_categorical_accuracy'] loss = history.history['loss'] plt.subplot(1, 2, 1) plt.plot(acc, label='Training Accuracy') plt.title('Training Accuracy') plt.legend() plt.subplot(1, 2, 2) plt.plot(loss, label='Training Loss') plt.title('Training Loss') plt.legend() plt.show() ############### predict ############# preNum = int(input("input the number of test alphabet:")) for i in range(preNum): alphabet1 = input("input test alphabet:") alphabet = [id_to_onehot[w_to_id[alphabet1]]] # 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入1个字母出结果,所以循环核时间展开步数为1; 表示为独热码有5个输入特征,每个时间步输入特征个数为5 alphabet = np.reshape(alphabet, (1, 1, 5)) result = model.predict([alphabet]) pred = tf.argmax(result, axis=1) pred = int(pred) tf.print(alphabet1 + '->' + input_word[pred])1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90连续输入4个字母,输出下一个字母


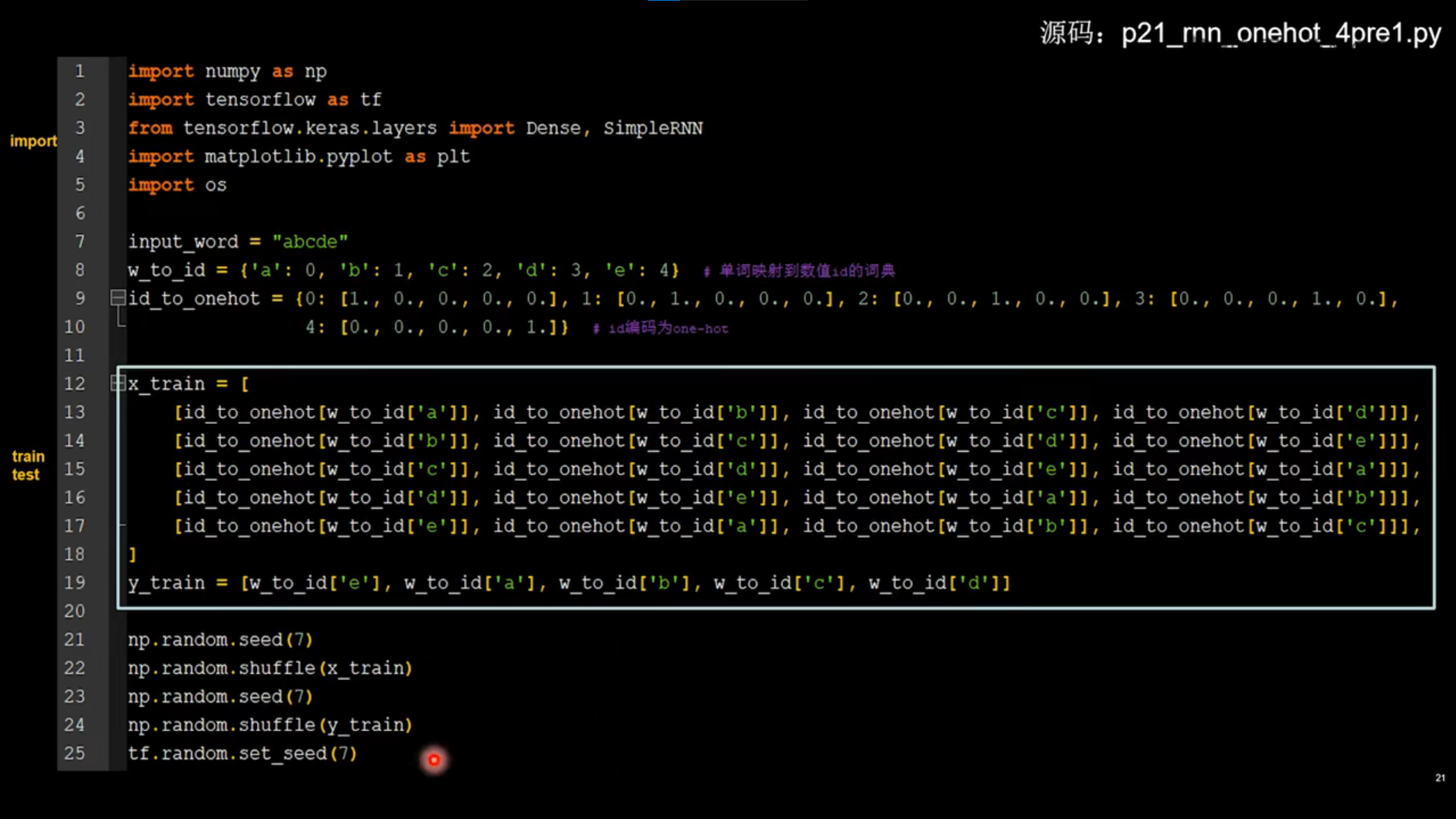
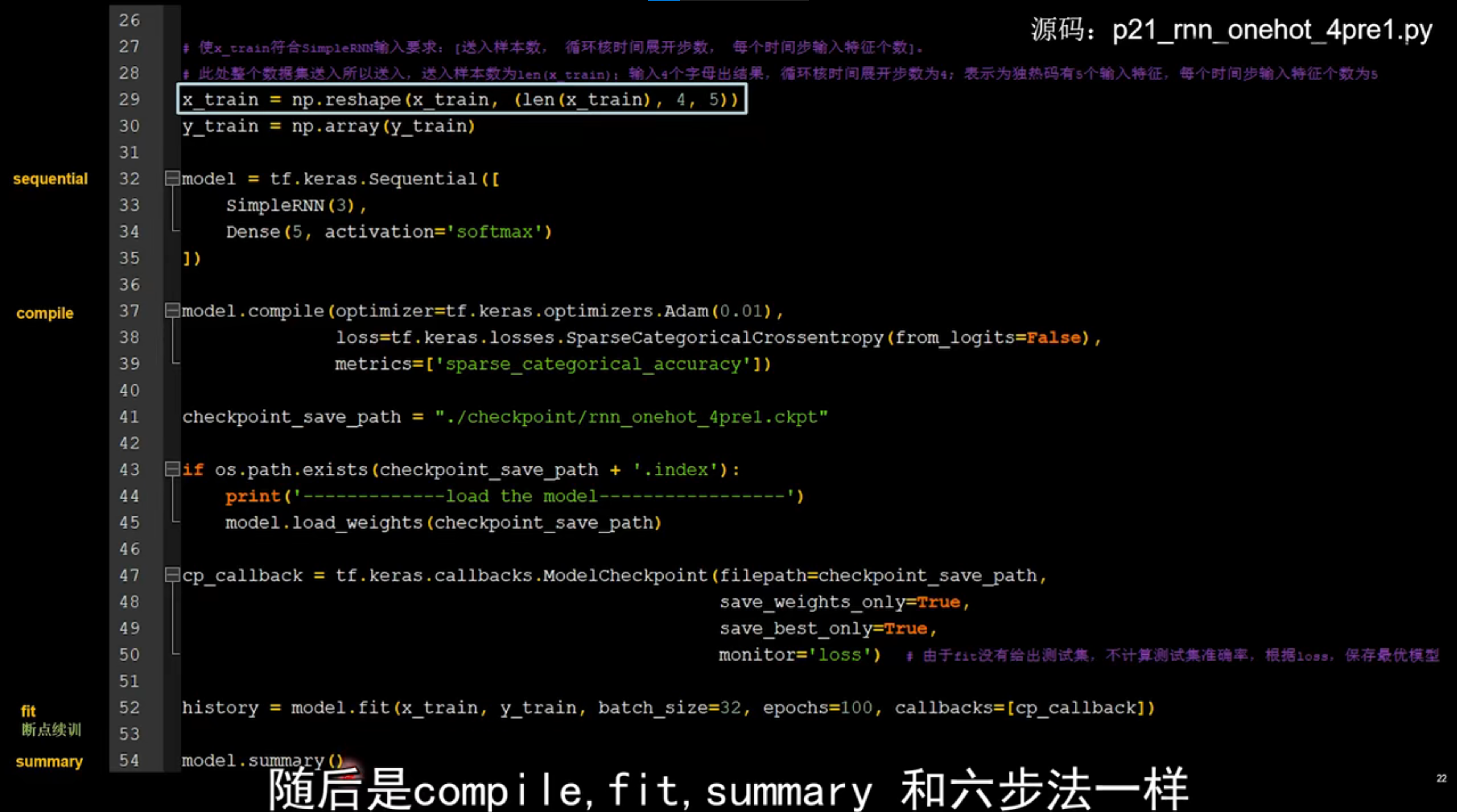
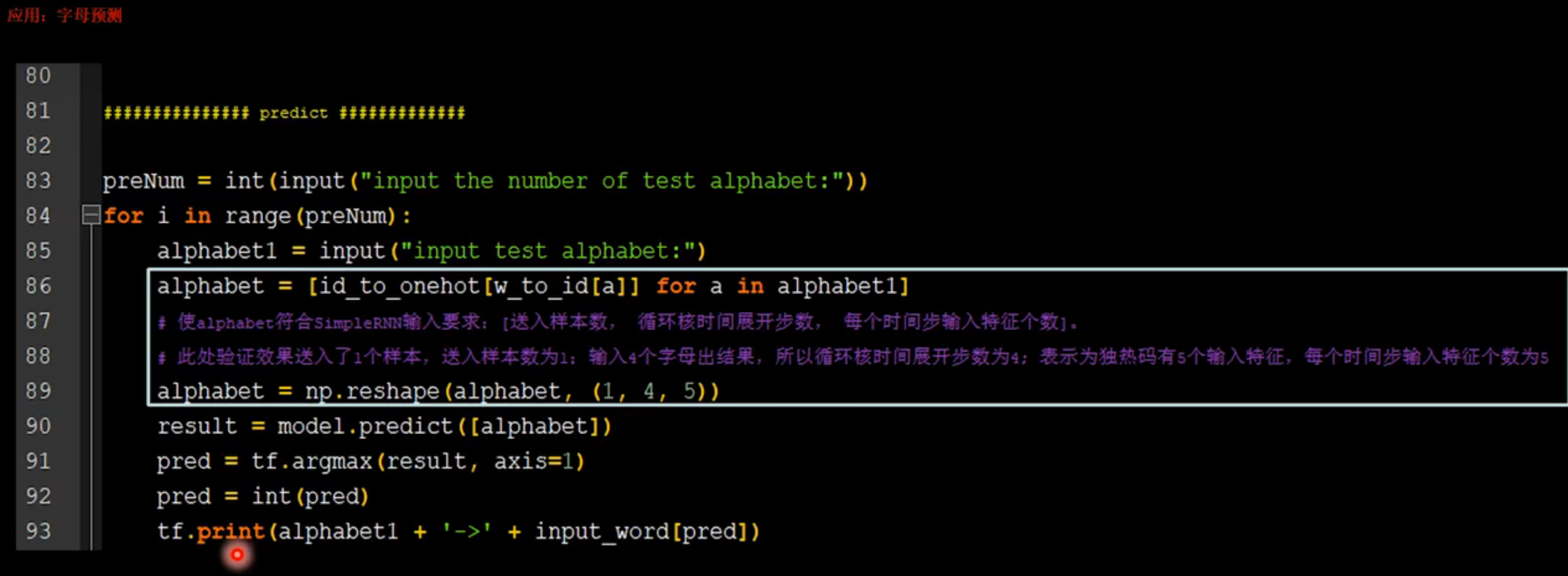
import numpy as np import tensorflow as tf from tensorflow.keras.layers import Dense, SimpleRNN import matplotlib.pyplot as plt import os input_word = "abcde" w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4} # 单词映射到数值id的词典 id_to_onehot = {0: [1., 0., 0., 0., 0.], 1: [0., 1., 0., 0., 0.], 2: [0., 0., 1., 0., 0.], 3: [0., 0., 0., 1., 0.], 4: [0., 0., 0., 0., 1.]} # id编码为one-hot x_train = [ [id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']]], [id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']]], [id_to_onehot[w_to_id['c']], id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']]], [id_to_onehot[w_to_id['d']], id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']]], [id_to_onehot[w_to_id['e']], id_to_onehot[w_to_id['a']], id_to_onehot[w_to_id['b']], id_to_onehot[w_to_id['c']]], ] y_train = [w_to_id['e'], w_to_id['a'], w_to_id['b'], w_to_id['c'], w_to_id['d']] np.random.seed(7) np.random.shuffle(x_train) np.random.seed(7) np.random.shuffle(y_train) tf.random.set_seed(7) # 使x_train符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。 # 此处整个数据集送入,送入样本数为len(x_train);输入4个字母出结果,循环核时间展开步数为4; 表示为独热码有5个输入特征,每个时间步输入特征个数为5 x_train = np.reshape(x_train, (len(x_train), 4, 5)) y_train = np.array(y_train) model = tf.keras.Sequential([ SimpleRNN(3), Dense(5, activation='softmax') ]) model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['sparse_categorical_accuracy']) checkpoint_save_path = "./checkpoint/rnn_onehot_4pre1.ckpt" if os.path.exists(checkpoint_save_path + '.index'): print('-------------load the model-----------------') model.load_weights(checkpoint_save_path) cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path, save_weights_only=True, save_best_only=True, monitor='loss') # 由于fit没有给出测试集,不计算测试集准确率,根据loss,保存最优模型 history = model.fit(x_train, y_train, batch_size=32, epochs=100, callbacks=[cp_callback]) model.summary() # print(model.trainable_variables) file = open('./weights.txt', 'w') # 参数提取 for v in model.trainable_variables: file.write(str(v.name) + '\n') file.write(str(v.shape) + '\n') file.write(str(v.numpy()) + '\n') file.close() ############################################### show ############################################### # 显示训练集和验证集的acc和loss曲线 acc = history.history['sparse_categorical_accuracy'] loss = history.history['loss'] plt.subplot(1, 2, 1) plt.plot(acc, label='Training Accuracy') plt.title('Training Accuracy') plt.legend() plt.subplot(1, 2, 2) plt.plot(loss, label='Training Loss') plt.title('Training Loss') plt.legend() plt.show() ############### predict ############# preNum = int(input("input the number of test alphabet:")) for i in range(preNum): alphabet1 = input("input test alphabet:") alphabet = [id_to_onehot[w_to_id[a]] for a in alphabet1] # 使alphabet符合SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]。此处验证效果送入了1个样本,送入样本数为1;输入4个字母出结果,所以循环核时间展开步数为4; 表示为独热码有5个输入特征,每个时间步输入特征个数为5 alphabet = np.reshape(alphabet, (1, 4, 5)) result = model.predict([alphabet]) pred = tf.argmax(result, axis=1) pred = int(pred) tf.print(alphabet1 + '->' + input_word[pred])1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93